When cudaMalloc() is called, what gets stored in the pointer deviceA? Is it the address of some location on the device heap?
Also, why does cudaMalloc() take a double pointer as its first parameter (void**) instead of just a pointer like malloc() in C?
jazzbass
@Kapteyn malloc returns the pointer to the block of memory that was dynamically allocated. cudaMalloc takes your pointer of pointers, and makes it point to the block of memory that was dynamically allocated to you.
Practically, it is the same, we could write a "wrapper" for cudaMalloc that has the same signature as malloc:
Is there a limit on the number of bytes we can transfer at once from host to device using cudaMemcpy?
paluri
@gryffolyon I believe this limit would be:
1) Loosely bound by the virtual address space (e.g., 32 bits), and
2) Tightly bound simply by the actual memory size of the device (minus whatever over-head is needed by the device to operate)
Doing a little research, it seems macros like CUDA_SAFE_CALL exist which allow you to wrap your call to cudaMemcpy for example, and receive information as to the status of the call (e.g., a failure due to trying to copy too much memory).
skywalker
@Kapteyn @jazzbass
Yes, deviceA has the memory address of the data on the device heap.
To answer your question of the double pointer, here's a simple example
int *A = malloc(10 * sizeof(int));
A is a pointer to an int array. To modify the array in any function we pass in the parameter A.
Once the memory is allocated on the device heap cudaMalloc would essentially do something like:
*ipp = mallocOnHeap(len) (so deviceA is set to the address)
kayvonf
@skywalker. Nice explanation. To summarize @skywalker's argument:
Let float* ptr be a pointer to a buffer that is to be allocated. If that pointer is to be modified by a function foo, we'd write this:
// function that allocates a buffer of 'count' floats, and stores
// a pointer to the buffer at the location pointed to by ptr
void allocate_floats(float** ptr, int count) {
*ptr = malloc( sizeof(float) * count );
}
The prototype of cudaMalloc essentially follows the prototype of allocate_floats above.
Note that CPU-side code should not attempt to deference the pointer provided by cudaMalloc, since that address is an address located in CUDA's global memory, not the address space of the CPU process. For example, the following will go boom:
Is the device global memory shared by different processes? Is it possible to use "cudaMalloc" to get a pointer and write beyond the boundary and tamper data of other process? Is the address returned from "cudaMalloc" a virtual address or a physical address?
kayvonf
CUDA global memory addresses are virtual addresses.
When
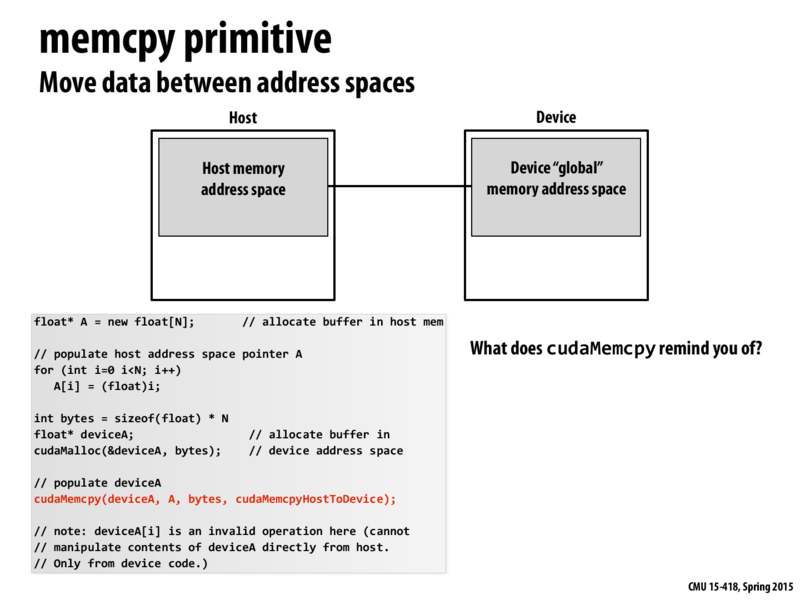
cudaMalloc()is called, what gets stored in the pointerdeviceA? Is it the address of some location on the device heap?Also, why does
cudaMalloc()take a double pointer as its first parameter(void**)instead of just a pointer like malloc() in C?@Kapteyn
mallocreturns the pointer to the block of memory that was dynamically allocated.cudaMalloctakes your pointer of pointers, and makes it point to the block of memory that was dynamically allocated to you.Practically, it is the same, we could write a "wrapper" for
cudaMallocthat has the same signature asmalloc:Is there a limit on the number of bytes we can transfer at once from host to device using
cudaMemcpy?@gryffolyon I believe this limit would be: 1) Loosely bound by the virtual address space (e.g., 32 bits), and 2) Tightly bound simply by the actual memory size of the device (minus whatever over-head is needed by the device to operate)
Doing a little research, it seems macros like CUDA_SAFE_CALL exist which allow you to wrap your call to cudaMemcpy for example, and receive information as to the status of the call (e.g., a failure due to trying to copy too much memory).
@Kapteyn @jazzbass
Yes, deviceA has the memory address of the data on the device heap.
To answer your question of the double pointer, here's a simple example
int *A = malloc(10 * sizeof(int));A is a pointer to an int array. To modify the array in any function we pass in the parameter A.
BUT To modify A itself, we need to pass in &A.
It might help to look at this illustration
Here deviceA = ip1.
So ipp = &deviceA;
Once the memory is allocated on the device heap cudaMalloc would essentially do something like:
*ipp = mallocOnHeap(len)(so deviceA is set to the address)@skywalker. Nice explanation. To summarize @skywalker's argument:
Let
float* ptrbe a pointer to a buffer that is to be allocated. If that pointer is to be modified by a functionfoo, we'd write this:The prototype of
cudaMallocessentially follows the prototype ofallocate_floatsabove.Note that CPU-side code should not attempt to deference the pointer provided by
cudaMalloc, since that address is an address located in CUDA's global memory, not the address space of the CPU process. For example, the following will go boom:Is the device global memory shared by different processes? Is it possible to use "cudaMalloc" to get a pointer and write beyond the boundary and tamper data of other process? Is the address returned from "cudaMalloc" a virtual address or a physical address?
CUDA global memory addresses are virtual addresses.