I wonder how do they partition the graphs into several machines. Do existing systems just use the greedy algorithm to partition the graph? Take this graph for instance, what if some scope of the current vertex is partitioned onto different machine, then the update for current vertex will be slow.
afzhang
It seems from a later slide that these might be used for a graph on a single machine. I'd assume that these should scale somehow to multiple machines too though, so I'm also curious about partitioning.
uncreative
I looked through some of the documentation.
It seems that if you want to run your graph on a cluster, you over partition your graph in to "atoms" so that the number of atoms is bigger than the largest cluster you will ever run on. A disk_graph is the composition of these atoms.
This describes the distributed graph data structures, and some things about how graphs are partitioned:
The default graph class, which is for in memory graphs, contains a number of partition methods which are given by this enum
I've copied the relevant documentation here
PARTITION_RANDOM
Vertices are randomly assigned to partitions. Every partition will have roughly the same number of vertices. (between vertices / nparts and (vertices / nparts + 1))
PARTITION_METIS
Partitions the graph using the METIS graph partitioning package. A modified version of METIS is included with GraphLab, so contact us if you encounter any issues.
PARTITION_BFS
Partitions the graph using Breadth First Searches. A random root vertex is selected and inserted into the first partition. Additional vertices are inserted into the partition by starting a BFS from the root vertex. When the partition reaches capacity: (vertices / nparts), the procedure restarts with a next partition with a new random root vertex.
PARTITION_EDGE_NUM
Partitions the vertices such that every partition has roughly the same number of edges.
yuel1
What level of consistency would be required for the pagerank algorithm on the previous slides?
ankit1990
I maybe wrong but I think it should be edge consistency.
yuel1
@ankit1990 given there is no data residing on the edges, wouldn't vertex consistency be valid as well?
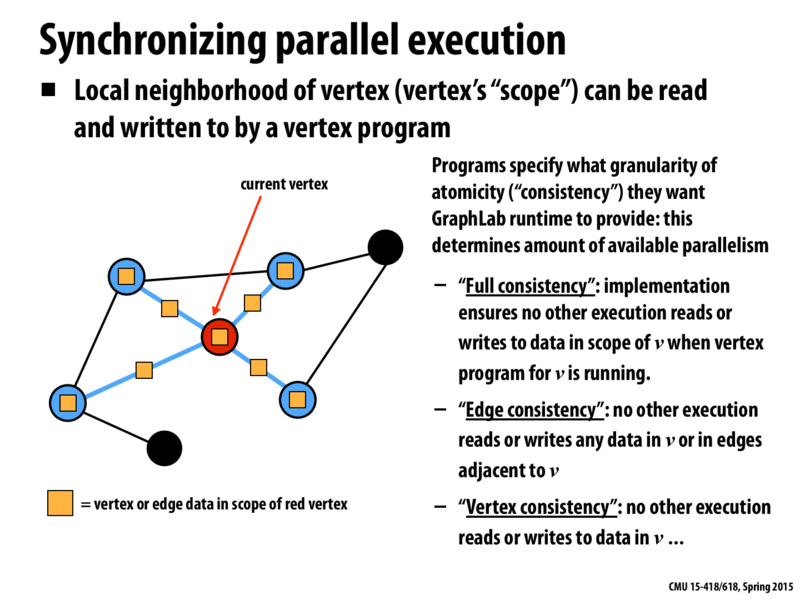
I wonder how do they partition the graphs into several machines. Do existing systems just use the greedy algorithm to partition the graph? Take this graph for instance, what if some scope of the current vertex is partitioned onto different machine, then the update for current vertex will be slow.
It seems from a later slide that these might be used for a graph on a single machine. I'd assume that these should scale somehow to multiple machines too though, so I'm also curious about partitioning.
I looked through some of the documentation.
It seems that if you want to run your graph on a cluster, you over partition your graph in to "atoms" so that the number of atoms is bigger than the largest cluster you will ever run on. A disk_graph is the composition of these atoms.
This describes the distributed graph data structures, and some things about how graphs are partitioned:
The default graph class, which is for in memory graphs, contains a number of partition methods which are given by this enum
I've copied the relevant documentation here
PARTITION_RANDOM
Vertices are randomly assigned to partitions. Every partition will have roughly the same number of vertices. (between vertices / nparts and (vertices / nparts + 1))
PARTITION_METIS
Partitions the graph using the METIS graph partitioning package. A modified version of METIS is included with GraphLab, so contact us if you encounter any issues.
PARTITION_BFS
Partitions the graph using Breadth First Searches. A random root vertex is selected and inserted into the first partition. Additional vertices are inserted into the partition by starting a BFS from the root vertex. When the partition reaches capacity: (vertices / nparts), the procedure restarts with a next partition with a new random root vertex.
PARTITION_EDGE_NUM
Partitions the vertices such that every partition has roughly the same number of edges.
What level of consistency would be required for the pagerank algorithm on the previous slides?
I maybe wrong but I think it should be edge consistency.
@ankit1990 given there is no data residing on the edges, wouldn't vertex consistency be valid as well?