Working on copies sounds similar to how higher order functions worked in 15-150 and 15-210. Isn't this incredibly slow? What motivates this design decision? Is it that the input is expected to only fit on disk?
mangocourage
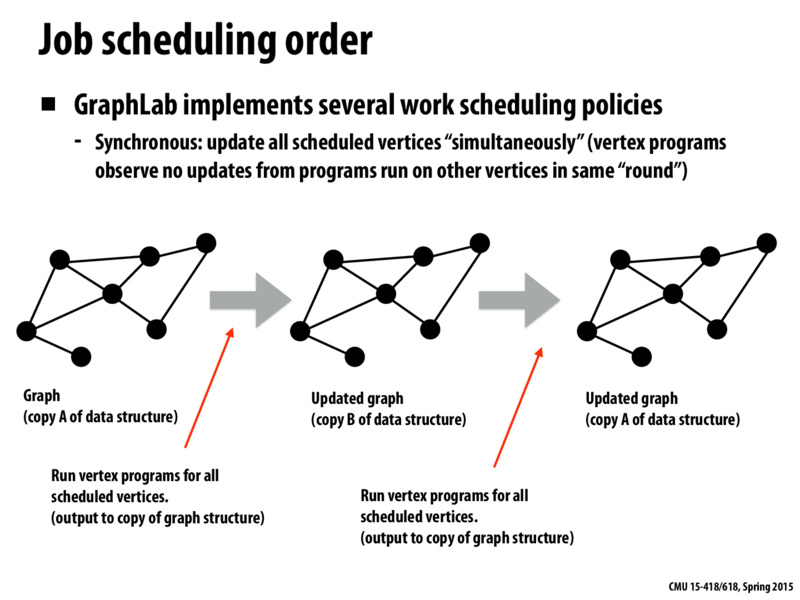
I'm having trouble understanding the diagram. Why do we get back to copy A of the data structure and how is this "synchronous"?
regi
@mangocourage: If I understand correctly, "synchronous" scheduling performs vertex operations in rounds, where at round i each vertex is updated with values from its neighbors from round i-1. The updates are stored in a new graph which is then copied over to the original. This is similar to the 2D grid solver we saw many lectures ago.
russt17
You use two copies so that you can use all the states from time t to calculate all the states at time t+1. If you only used one copy, as you updated individual nodes you'd be changing the inputs to other nodes.
The fact that you go back from copy B to A is just an optimization so that you can go
A -> B -> A -> B ->.....
as opposed to doing
A -> B, copy back to A, A -> B, copy back to A
instead of just copying back to A you may as well process another time step
Working on copies sounds similar to how higher order functions worked in 15-150 and 15-210. Isn't this incredibly slow? What motivates this design decision? Is it that the input is expected to only fit on disk?
I'm having trouble understanding the diagram. Why do we get back to copy A of the data structure and how is this "synchronous"?
@mangocourage: If I understand correctly, "synchronous" scheduling performs vertex operations in rounds, where at round i each vertex is updated with values from its neighbors from round i-1. The updates are stored in a new graph which is then copied over to the original. This is similar to the 2D grid solver we saw many lectures ago.
You use two copies so that you can use all the states from time t to calculate all the states at time t+1. If you only used one copy, as you updated individual nodes you'd be changing the inputs to other nodes.
The fact that you go back from copy B to A is just an optimization so that you can go
A -> B -> A -> B ->.....
as opposed to doing
A -> B, copy back to A, A -> B, copy back to A
instead of just copying back to A you may as well process another time step