As I mentioned in the class, if we assume that we have unlimited (theoretically) number of processors, we can make a tree based reduction (divide and conquer) to decrease the execution time. This would enable us to get a better speedup since this approach decreases the sequential portion of the code.
Kapteyn
It seems like this example produces a speedup equation that is slightly different from that of Amdahl's law.
The law states that the maximum speedup must be less than or equal to 1 / (S + (1-S)p) where S is the fraction of the total work that cannot be parallelized. However, taking the above equation 2n^2/(2n^2/p + p) and dividing both numerator and denominator by 2n^2 (which is the total amount of work in the original sequential program), we get: 1/(1/p + p/2n^2).
This is not the same as the equation 1/(S + (1-S)/p) because by parallelizing the original program, we actually added p more work. Here, the p/2n^2 in the denominator is not the fraction of the original work that could not be parallelized. It is instead a ratio between the additional amount of work in the parallel program to the original total amount of work in the sequential program.
So we have in the denominator 1/p, because we completely parallelized 2n^2 work across p processors, plus p/2n^2.
yuel1
@oulgen , I wonder if there's a point where the overhead of implementing a tree based reduction (divide and conquer) would outweigh the benefits of using such an approach. And if there is such a point I wonder what the correlation between processor count and data size is...
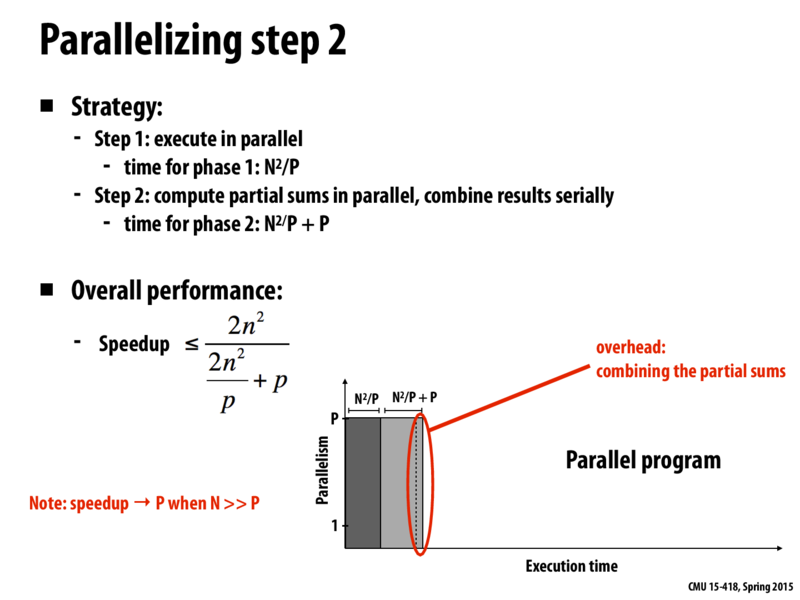
As I mentioned in the class, if we assume that we have unlimited (theoretically) number of processors, we can make a tree based reduction (divide and conquer) to decrease the execution time. This would enable us to get a better speedup since this approach decreases the sequential portion of the code.
It seems like this example produces a speedup equation that is slightly different from that of Amdahl's law.
The law states that the maximum speedup must be less than or equal to 1 / (S + (1-S)p) where S is the fraction of the total work that cannot be parallelized. However, taking the above equation 2n^2/(2n^2/p + p) and dividing both numerator and denominator by 2n^2 (which is the total amount of work in the original sequential program), we get: 1/(1/p + p/2n^2).
This is not the same as the equation 1/(S + (1-S)/p) because by parallelizing the original program, we actually added p more work. Here, the p/2n^2 in the denominator is not the fraction of the original work that could not be parallelized. It is instead a ratio between the additional amount of work in the parallel program to the original total amount of work in the sequential program.
So we have in the denominator 1/p, because we completely parallelized 2n^2 work across p processors, plus p/2n^2.
@oulgen , I wonder if there's a point where the overhead of implementing a tree based reduction (divide and conquer) would outweigh the benefits of using such an approach. And if there is such a point I wonder what the correlation between processor count and data size is...