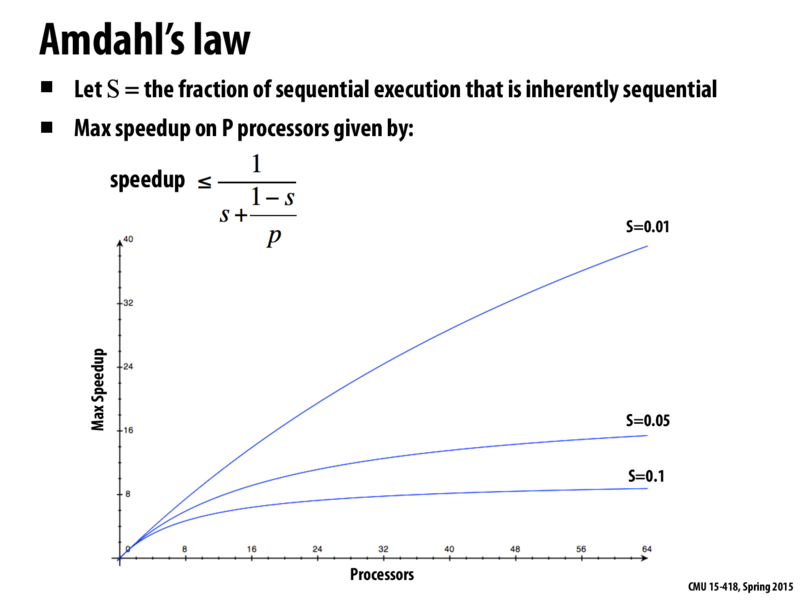
Is this kind of formula something we might need for an exam? Or will most of the problems be more about our understanding of a concept, such as Quiz 1 (though I suppose a true understanding of this concept would allow us to re-derive this formula)?
afzhang
@ekr: Well, Kavyon mentioned that quiz 1 was pulled from last year's midterm, so I would assume that our exams will follow a similar format.
Also, breaking down that formula:
s: the fraction of work that has to be sequential
(1-s)/p: the fraction of work that does not have to be sequential divided by the number of processors we have to do work
So we're just adding together s + (1-s)/p to get the total amount of work done now that we're doing part of it in parallel, and the speedup is the inverse of that.
sgbowen
I think this places an interesting restriction/bound on the speed of some programs...
We talked about how single core CPU computations can only be so fast (to avoid burning out the actual hardware), but this seems to show that, for some programs, even parallel implementations can only be so fast. Yes, the function continues to grow, but at a rate that quickly becomes negligible--especially given the tradeoff in cost of having/running more processors.
So are we just out of luck for some programs--or is there anything else we can do? Are there any examples for when this bound in speedup has been a huge problem? Or is the bound so high that it hasn't bothered us yet?
cacay
A related concept in complexity theory is the P vs. NC problem. P is the class of problems that can be solved in polynomial time. NC stand for "Nick's Class": problems that can be solved efficiently on a parallel computer. It is still unknown if P = NC but most people suspect it isn't. This would mean there are problems that are inherently sequential.
TypicalChazz
@sgbowen: I think that's pretty much the biggest challenge of parallel computing: attempting to phrase/tackle a problem in a manner that lends itself to parallelism, while minimizing the serial nature of the problem. I think that there's always going to be some limit to parallel performance given the serial nature of certain aspects of a problem.
sanchuah
to summarize this page: speedup is bound by 1/ [(s) + (1-s)/p] (where s is the portion of code is sequential) because of following reason: assume the execution time of sequential execution is (s) + (1-s). The parallelized execution time = sequential code execution time + parallelizable code execution time (assuming P resources can speedup Px) = s + (1-s)/ p. So the total speedup = 1 / [(s) + (1-s)/p]
Is this kind of formula something we might need for an exam? Or will most of the problems be more about our understanding of a concept, such as Quiz 1 (though I suppose a true understanding of this concept would allow us to re-derive this formula)?
@ekr: Well, Kavyon mentioned that quiz 1 was pulled from last year's midterm, so I would assume that our exams will follow a similar format.
Also, breaking down that formula:
s: the fraction of work that has to be sequential
(1-s)/p: the fraction of work that does not have to be sequential divided by the number of processors we have to do work
So we're just adding together s + (1-s)/p to get the total amount of work done now that we're doing part of it in parallel, and the speedup is the inverse of that.
I think this places an interesting restriction/bound on the speed of some programs...
We talked about how single core CPU computations can only be so fast (to avoid burning out the actual hardware), but this seems to show that, for some programs, even parallel implementations can only be so fast. Yes, the function continues to grow, but at a rate that quickly becomes negligible--especially given the tradeoff in cost of having/running more processors.
So are we just out of luck for some programs--or is there anything else we can do? Are there any examples for when this bound in speedup has been a huge problem? Or is the bound so high that it hasn't bothered us yet?
A related concept in complexity theory is the P vs. NC problem. P is the class of problems that can be solved in polynomial time. NC stand for "Nick's Class": problems that can be solved efficiently on a parallel computer. It is still unknown if P = NC but most people suspect it isn't. This would mean there are problems that are inherently sequential.
@sgbowen: I think that's pretty much the biggest challenge of parallel computing: attempting to phrase/tackle a problem in a manner that lends itself to parallelism, while minimizing the serial nature of the problem. I think that there's always going to be some limit to parallel performance given the serial nature of certain aspects of a problem.
to summarize this page: speedup is bound by 1/ [(s) + (1-s)/p] (where s is the portion of code is sequential) because of following reason: assume the execution time of sequential execution is (s) + (1-s). The parallelized execution time = sequential code execution time + parallelizable code execution time (assuming P resources can speedup Px) = s + (1-s)/ p. So the total speedup = 1 / [(s) + (1-s)/p]