Just wanted to point out that this is representative of many dynamic programming algorithms as well. For example, take Longest common subsequence (not contiguous). One way to solve it would be to make a 2d array where A[i, j] = longest common subsequence of X_[0, i], and Y_[0, j]. There are some interesting ways to solve these problems with good parallelism other than using the diagonals. Those are a bit complicated to explain on a comment and may not necessarily address the bad points in this slide so I won't go over them here.
Orangensaft
If we wanted to actually compute the values without using an approximation like what it says a few slides later, how should we go about doing it? Would we just try to parallelize it based on the diagnols and take the risk of cache misses? Or would it be faster to map it to another array, and try to compute it from there?
jcarchi
Mapping to another array wouldn't help since to compute the value A[i, j], you would need to compute both the values of A[i-1,j] and A[i, j-1] first. If avoiding cache misses is your goal, then a divide and conquer solution would work.
We can divide the N x N array into 4 (2x2) quadrants of N/2 x N/2. We can then recursively solve each quadrant (shown by purple lines). We need to solve quadrant 1 first. Quadrant 2 and 3 can be solved in any order, or in parallel. We solve quadrant 4 last. Once we reach a threshold (ie a quadrant of size 100x100 elements), we can just solve that quadrant with a serial algorithm, sweeping from top to bottom, left to right.
Note that we can divide the N x N array into more than 4 quadrants. Any k x k division will work.
fgomezfr
@orangensaft Good point about optimizing cache layouts (if you plan on parallelizing along diagonals, you should probably arrange diagonally adjacent elements together in memory) but I think the issues here are more about the computational organization.
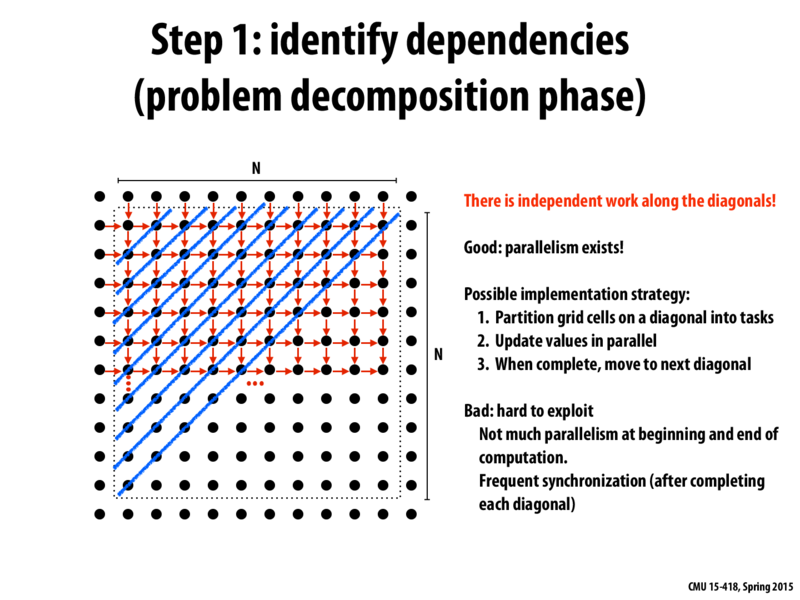
The problems mentioned on the slide are that there is not much parallelism early - the diagonals are not the same length, the first few are very short - and if you plan to do each diagonal as one parallel task, you need a barrier after each one (to sync up data for the next diagonal).
If you are targeting a high SIMD-width machine (like a GPU) and you have a large array (so you don't care too much about the first/last few diagonals) you might just go ahead and do each diagonal (e.g. as a CUDA block) but again you need to deal with barriers.
@jcarchi's idea is promising, but you can take it a step further. The recursive division doesn't gain you much, because you always need to process the top-left quadrant first, then spread outwards. But you've noted that quadrants two and three are independent, given that quadrant one is finished. More generally, you can always sweep a section left-to-right without stopping as long as everything above is already done; and you can sweep top-to-bottom as long as everything to the left is finished. So you might do something on a multi-core CPU like spawn a thread which processes the first row (or several), sweeping left-to-right. Once the first column (or several, with a SIMD machine) are finished, you can spawn a second thread which sweeps top-to-bottom along the left edge. You can continue in this fashion, filling in stripes in the middle, but each thread has to be careful not to get ahead of previous threads.
There are different strategies, but the important part is that the top-to-bottom, left-to-right dependency limits parallelism, not the memory layout (which you can control).
Just wanted to point out that this is representative of many dynamic programming algorithms as well. For example, take Longest common subsequence (not contiguous). One way to solve it would be to make a 2d array where A[i, j] = longest common subsequence of X_[0, i], and Y_[0, j]. There are some interesting ways to solve these problems with good parallelism other than using the diagonals. Those are a bit complicated to explain on a comment and may not necessarily address the bad points in this slide so I won't go over them here.
If we wanted to actually compute the values without using an approximation like what it says a few slides later, how should we go about doing it? Would we just try to parallelize it based on the diagnols and take the risk of cache misses? Or would it be faster to map it to another array, and try to compute it from there?
Mapping to another array wouldn't help since to compute the value A[i, j], you would need to compute both the values of A[i-1,j] and A[i, j-1] first. If avoiding cache misses is your goal, then a divide and conquer solution would work.
Take a look at this figure: http://imgur.com/PkLxEuD
We can divide the N x N array into 4 (2x2) quadrants of N/2 x N/2. We can then recursively solve each quadrant (shown by purple lines). We need to solve quadrant 1 first. Quadrant 2 and 3 can be solved in any order, or in parallel. We solve quadrant 4 last. Once we reach a threshold (ie a quadrant of size 100x100 elements), we can just solve that quadrant with a serial algorithm, sweeping from top to bottom, left to right.
Note that we can divide the N x N array into more than 4 quadrants. Any k x k division will work.
@orangensaft Good point about optimizing cache layouts (if you plan on parallelizing along diagonals, you should probably arrange diagonally adjacent elements together in memory) but I think the issues here are more about the computational organization.
The problems mentioned on the slide are that there is not much parallelism early - the diagonals are not the same length, the first few are very short - and if you plan to do each diagonal as one parallel task, you need a barrier after each one (to sync up data for the next diagonal).
If you are targeting a high SIMD-width machine (like a GPU) and you have a large array (so you don't care too much about the first/last few diagonals) you might just go ahead and do each diagonal (e.g. as a CUDA block) but again you need to deal with barriers.
@jcarchi's idea is promising, but you can take it a step further. The recursive division doesn't gain you much, because you always need to process the top-left quadrant first, then spread outwards. But you've noted that quadrants two and three are independent, given that quadrant one is finished. More generally, you can always sweep a section left-to-right without stopping as long as everything above is already done; and you can sweep top-to-bottom as long as everything to the left is finished. So you might do something on a multi-core CPU like spawn a thread which processes the first row (or several), sweeping left-to-right. Once the first column (or several, with a SIMD machine) are finished, you can spawn a second thread which sweeps top-to-bottom along the left edge. You can continue in this fashion, filling in stripes in the middle, but each thread has to be careful not to get ahead of previous threads.
There are different strategies, but the important part is that the top-to-bottom, left-to-right dependency limits parallelism, not the memory layout (which you can control).