1) I am bit uneasy with this analysis of the dependencies. I agree it was the dependencies of the code, but it only was because we chose to loop in row major order. It would feel cleaner to me to have the dependencies be independent of how we loop. Is that better, or is that making it a bit too high level? (if we had done the general dependencies, we would still come to the eventual checkerboard solution)
2) For this problem in general, wouldn't it be better to have two boards, the previous step and the current step we are computing? That way, the computation of the current board could be done in an arbitrary order (say, one to exploit the cache and fact that the program is only reading) and then on the next iteration just swap board roles? Or is the adding of memory outside of the problems scope?
rohitban
Why do each of the points depend on on the points right above and to the left of them?
Shouldn't they depend on the 4 adjacent points or do the top and left dependencies arise from the order in which we traverse the loop?
ESINNG
@rohitban You should read the code before seeing this dependency, because this is the dependency according to the code in the last slide.
In the loop, the main calculation is as following:
A[i,j] = 0.2f * (A[i,j] + A[i,j-1] + A[i-1,j] + A[i,j+1] + A[i+1,j]);
Because before doing this calculation, the value of A[i,j-1] + A[i-1,j] has been updated and the value of A[i,j+1] + A[i+1,j] is not updated, so the update of A[i,j] must precede updating A[i,j+1] and A[i+1,j] but after updating A[i,j-1] + A[i-1,j].
rbcarlso
@himmelnetz: On question 2: I actually got confused by this slide at first because I just assumed there would be two boards, which is much easier to parallelize and is a more accurate model for the actual thing that this program tries to model. I wouldn't say that allocating more memory is outside the scope of the problem--it's a legitimate decision to make as a programmer tasked with this problem--but there are cases where it'd be a bad idea to use two boards (small cache, want to minimize memory operations, &c.), and when we assume using one board is preferable we get different and valuable insights (diagonalizing vs. redblack approaches).
I think a good takeaway from the one board vs. two boards issue is that, like Kayvon said in lecture, when the problem itself is already an approximation for a real-world phenomenon, we can choose slightly different ways of approximating and still get correct (though different) results. Depending on the system you're using and your particular goals, you may have to think about how to get the best performance out of either approach.
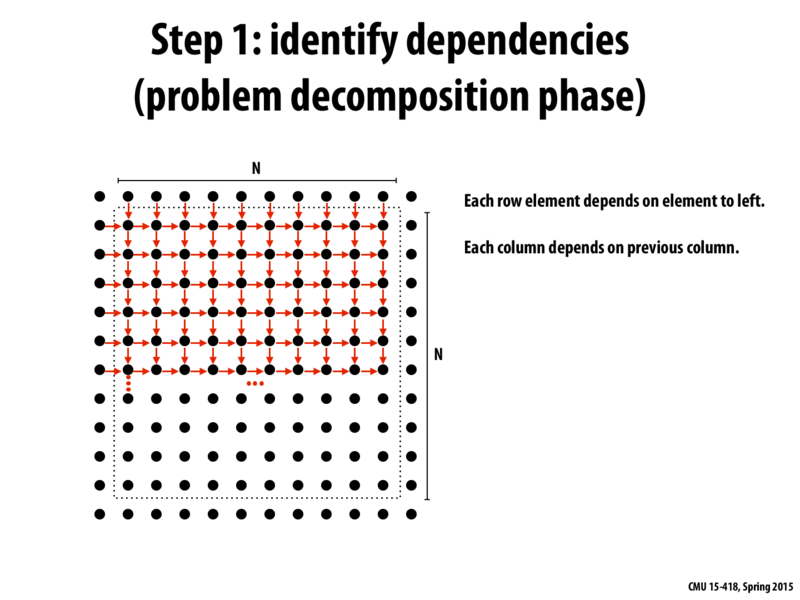
I had two comments/questions on this slide
1) I am bit uneasy with this analysis of the dependencies. I agree it was the dependencies of the code, but it only was because we chose to loop in row major order. It would feel cleaner to me to have the dependencies be independent of how we loop. Is that better, or is that making it a bit too high level? (if we had done the general dependencies, we would still come to the eventual checkerboard solution)
2) For this problem in general, wouldn't it be better to have two boards, the previous step and the current step we are computing? That way, the computation of the current board could be done in an arbitrary order (say, one to exploit the cache and fact that the program is only reading) and then on the next iteration just swap board roles? Or is the adding of memory outside of the problems scope?
Why do each of the points depend on on the points right above and to the left of them? Shouldn't they depend on the 4 adjacent points or do the top and left dependencies arise from the order in which we traverse the loop?
@rohitban You should read the code before seeing this dependency, because this is the dependency according to the code in the last slide. In the loop, the main calculation is as following: A[i,j] = 0.2f * (A[i,j] + A[i,j-1] + A[i-1,j] + A[i,j+1] + A[i+1,j]);
Because before doing this calculation, the value of A[i,j-1] + A[i-1,j] has been updated and the value of A[i,j+1] + A[i+1,j] is not updated, so the update of A[i,j] must precede updating A[i,j+1] and A[i+1,j] but after updating A[i,j-1] + A[i-1,j].
@himmelnetz: On question 2: I actually got confused by this slide at first because I just assumed there would be two boards, which is much easier to parallelize and is a more accurate model for the actual thing that this program tries to model. I wouldn't say that allocating more memory is outside the scope of the problem--it's a legitimate decision to make as a programmer tasked with this problem--but there are cases where it'd be a bad idea to use two boards (small cache, want to minimize memory operations, &c.), and when we assume using one board is preferable we get different and valuable insights (diagonalizing vs. redblack approaches).
I think a good takeaway from the one board vs. two boards issue is that, like Kayvon said in lecture, when the problem itself is already an approximation for a real-world phenomenon, we can choose slightly different ways of approximating and still get correct (though different) results. Depending on the system you're using and your particular goals, you may have to think about how to get the best performance out of either approach.