I'm confused about when we do ISPC...do the program instances need to sync up at the beginning of each for loop? It seems like this would be necessary to use a single packed load for a performance boost.
Alternatively, if one instance happens to be given a long input, can the others each loop through several short inputs in the meanwhile?
himmelnetz
@ak47 I believe you might be a little confused as to what ISPC is doing in this situation. What we are doing here is SIMD (single instruction, multiple data) where we apply the same operation (such as calculating sign) on multiple pieces of data. The data itself is always the same size; just an integer. So in this case, we would expect each instance to take the same amount of time.
I believe there could be cases where one programIndex needs to do extra work (i.e. by a conditional), at which point I'm not sure what ISPC will do...I'd be curious as to the answer of that.
ericwang
Thanks @himmelnetz. I used to have the same question. So here we are discussing about the SIMD implementation generated by ISPC compiler. It’s a little confusing though. In ispc.github.io: “ispc compiles a C-based SPMD programming language to run on the SIMD units of CPUs and the Intel Xeon Phi™ architecture”. So I think the programming language is SPMD. But in detail implementation, ispc can take advantage of SIMD units. That's why we talked about memory access in this slide. If it is for SPMD only, I think the steps in different instances will not sync so well.
uncreative
I'm curious: If you wrote something like the following in regular c:
It is safe for doWhatever(a+programCount) to depend on doWhatever(a).
It is also safe for doWhatever(a+programCount+b) to depend on doWhatever(a) as long as b>0.
It seems like the interleaved approach has the first property (that is it is safe for element 4 to depend on element 0). However, it is not clear to me that the abstraction guarantees the second property (it may be unsafe for element 5 to depend on element 0). Is there a way to ensure that this second dependency is safe using ISPC?
kayvonf
@uncreative: I'm assuming you mean if you wrote that code in ISPC?
Yes. The logic in an ISPC function provides the logic for a single instance (although it is executed for all instances). So in your case (1), the program as written performs iteration 0 occurs prior to iteration programCount, so yes, that second iteration can depend on the results computed in the first.
For (2) the answer is tricky. As first you might think that the answer is NO -- that ISPC does not make any statements about the order of concurrent execution of instances in a gang. However, the answer is actually yes due to the "maximally converged guarantee" that ISPC declares is part of it's language semantics. You can read about it here:
Due to this guarantee, you can be sure that all instances have completed their respective first iterations before any instance begins its second iteration.
This is the "one tiny detail" of ISPC that I mentioned that I was avoiding several times in class, and it is the reason why it would be insanely inefficient to implement ISPC program instances in individual pthreads. The pthreads would have to sync up after every instruction to comply with the convergence guarantee.
By giving the programmer a "maximally converged guarantee", ISPC's design basically prevents the possibility of a performant implementation that is not based on SIMD instructions. Off the top of my head I'm not certain what benefits one gets from the guarantee, so I'll have to ask the ISPC designer. (Certainly there is one... otherwise it makes little sense to conflate abstraction and implementation, and prevent alternative implementations in the future.)
fgomezfr
@kayvonf I think the maximal-convergence guarantee helps to simplify data races:
By enforcing a SIMD implementation where all program instances in a gang execute in lockstep, ISPC allows reading from shared memory without worrying about whether another instance has finished writing. By enforcing the maximal-convergence guarantee at a per-instruction level, ISPC knows automatically that instances on the same control path will write and read at the same time.
An implementation on pthreads without the convergence guarantee would have to do a lot of analysis to detect possible race conditions, or require the programmer to identify these and insert memory_barrier() calls, which ISPC tries to avoid using.
Seems like they sacrificed flexibility of implementation to make programming for the most likely implementation a little easier.
kayvonf
Absolutely. I agree.
kayvonf
But race conditions aren't any more prevalent in ISPC code than in pthread code, and programmers have to add sync constructs to avoid race conditions in other systems. It's non 100% clear why Matt Pharr decided to make this decision here. I expect the real reason is to give some performance transparency. ISPC was never intended to abstract over a wide variety of implementations, so they went for performance transparency over a portable abstraction (anticipating that additional portability wasn't a desirable feature.)
But like I said, I've asked Matt. Let's see what he says.
uncreative
@kayvonf Thanks for the explanation! I was initially wondering about how similarly a sequential loop reading from an array and an ISPC implementation of this sequential loop would use the cache. With this guarantee it seems that as long as you can fit four (or whatever the gang size may be) iterations worth of data into the cache, the behavior will be almost identical.
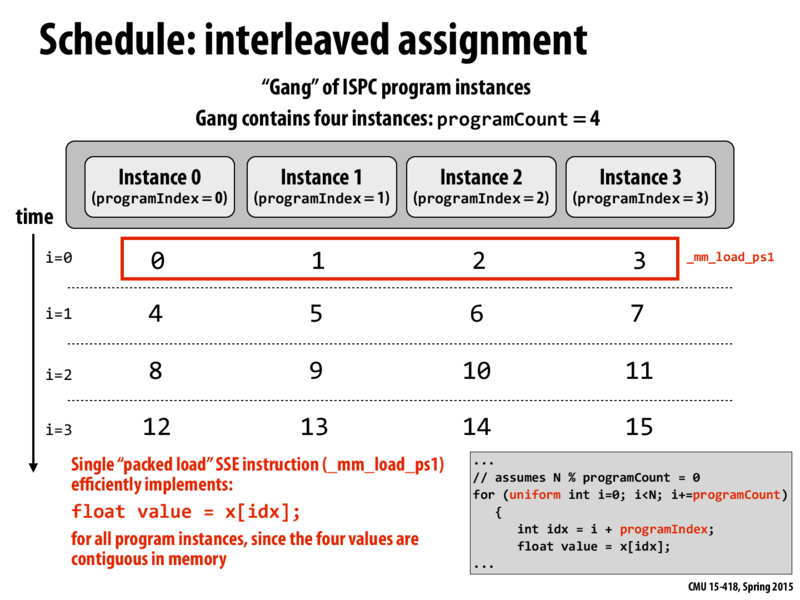
I'm confused about when we do ISPC...do the program instances need to sync up at the beginning of each for loop? It seems like this would be necessary to use a single packed load for a performance boost.
Alternatively, if one instance happens to be given a long input, can the others each loop through several short inputs in the meanwhile?
@ak47 I believe you might be a little confused as to what ISPC is doing in this situation. What we are doing here is SIMD (single instruction, multiple data) where we apply the same operation (such as calculating sign) on multiple pieces of data. The data itself is always the same size; just an integer. So in this case, we would expect each instance to take the same amount of time.
I believe there could be cases where one programIndex needs to do extra work (i.e. by a conditional), at which point I'm not sure what ISPC will do...I'd be curious as to the answer of that.
Thanks @himmelnetz. I used to have the same question. So here we are discussing about the SIMD implementation generated by ISPC compiler. It’s a little confusing though. In ispc.github.io: “ispc compiles a C-based SPMD programming language to run on the SIMD units of CPUs and the Intel Xeon Phi™ architecture”. So I think the programming language is SPMD. But in detail implementation, ispc can take advantage of SIMD units. That's why we talked about memory access in this slide. If it is for SPMD only, I think the steps in different instances will not sync so well.
I'm curious: If you wrote something like the following in regular c:
It is safe for doWhatever(a+programCount) to depend on doWhatever(a).
It is also safe for doWhatever(a+programCount+b) to depend on doWhatever(a) as long as b>0.
It seems like the interleaved approach has the first property (that is it is safe for element 4 to depend on element 0). However, it is not clear to me that the abstraction guarantees the second property (it may be unsafe for element 5 to depend on element 0). Is there a way to ensure that this second dependency is safe using ISPC?
@uncreative: I'm assuming you mean if you wrote that code in ISPC?
Yes. The logic in an ISPC function provides the logic for a single instance (although it is executed for all instances). So in your case (1), the program as written performs iteration 0 occurs prior to iteration
programCount, so yes, that second iteration can depend on the results computed in the first.For (2) the answer is tricky. As first you might think that the answer is NO -- that ISPC does not make any statements about the order of concurrent execution of instances in a gang. However, the answer is actually yes due to the "maximally converged guarantee" that ISPC declares is part of it's language semantics. You can read about it here:
https://ispc.github.io/ispc.html#gang-convergence-guarantees
Due to this guarantee, you can be sure that all instances have completed their respective first iterations before any instance begins its second iteration.
This is the "one tiny detail" of ISPC that I mentioned that I was avoiding several times in class, and it is the reason why it would be insanely inefficient to implement ISPC program instances in individual pthreads. The pthreads would have to sync up after every instruction to comply with the convergence guarantee.
By giving the programmer a "maximally converged guarantee", ISPC's design basically prevents the possibility of a performant implementation that is not based on SIMD instructions. Off the top of my head I'm not certain what benefits one gets from the guarantee, so I'll have to ask the ISPC designer. (Certainly there is one... otherwise it makes little sense to conflate abstraction and implementation, and prevent alternative implementations in the future.)
@kayvonf I think the maximal-convergence guarantee helps to simplify data races:
https://ispc.github.io/ispc.html#data-races-within-a-gang
By enforcing a SIMD implementation where all program instances in a gang execute in lockstep, ISPC allows reading from shared memory without worrying about whether another instance has finished writing. By enforcing the maximal-convergence guarantee at a per-instruction level, ISPC knows automatically that instances on the same control path will write and read at the same time.
An implementation on pthreads without the convergence guarantee would have to do a lot of analysis to detect possible race conditions, or require the programmer to identify these and insert memory_barrier() calls, which ISPC tries to avoid using.
Seems like they sacrificed flexibility of implementation to make programming for the most likely implementation a little easier.
Absolutely. I agree.
But race conditions aren't any more prevalent in ISPC code than in pthread code, and programmers have to add sync constructs to avoid race conditions in other systems. It's non 100% clear why Matt Pharr decided to make this decision here. I expect the real reason is to give some performance transparency. ISPC was never intended to abstract over a wide variety of implementations, so they went for performance transparency over a portable abstraction (anticipating that additional portability wasn't a desirable feature.)
But like I said, I've asked Matt. Let's see what he says.
@kayvonf Thanks for the explanation! I was initially wondering about how similarly a sequential loop reading from an array and an ISPC implementation of this sequential loop would use the cache. With this guarantee it seems that as long as you can fit four (or whatever the gang size may be) iterations worth of data into the cache, the behavior will be almost identical.