So I gather (no pun intended) that scheduling the work this way is less efficient than what we had on the previous slide?
oulgen
That is indeed true. During the lecture, Kayvon mentioned that gather instructions takes a lot resources/time to retrieve the data whereas the load instruction is much cheaper and less intensive. When the entire program executes, they end up doing the same operation but since load operation i.e. <0,1,2,3> as opposed to gather which is <0,4,8,12>, does less work, it would be preferable to use it.
oulgen
One question I would like to add to this point is that when would we want to use gather rather than load?
kayvonf
When it's fundamentally required by the program logic. See slide 63 of this lecture.
zhanpenf
Are there some situations that block assignment will be better? Like will block assignment be better than interleaved assignment when we use multi-core parallelization (like task in ispc)? I think that block assignment has some good properties like good locality of each task, which should help improve cache hit rate and boost the speed.
arjunh
@zhanpenf I'd disagree on the claim that block assignment has better task locality. With interleaved assignment, any one of the program instances operating on a vector of data can load in data for the other program instances. If all the program instances are operating on a cache-line of data, only one program instance will take a cache miss, while the remaining program instances will benefit from cache hits.
On the other hand, a blocked assignment will lead to each program instance loading in potentially different cache lines.
andymochi
@arjunh Do you know if there are any performance benchmarks on the latency of a 'gather' vs. 'packed load'?
I think there are scenarios in which blocked assignment can yield better performance than the interleaved assignment. Consider a scenario in which we have more than onetask running on one core.
In the interleaved assignment, we expect the cache to have 1 miss per line, which will require a packed load each time.
In the blocked assignment, the processor can hide the latency of the gather with multi-threading, and then benefit from three cache hits in a row. I suppose the interleaved assignment could multi-threaded as well in this scenario, but gather seems to load more data in the cache because of latency hiding.
Oh, and I guess all of this assumes no pre-fetching.
rbandlam
Cache line size and program count (gang size) also plays a big role in determining where interleaved assignment or blocked assignment is better because if cache line size is 16 bytes and program count is 16, then in single load we can fetch 16 bytes that can be used by 1 set of gang in interleaved execution and 16 set of gangs in blocked assignment. It also depends of number of parallel tasks running, cache eviction based on address access by other tasks and how much of additional overhead incurred by memory_gather operation over memory_load.
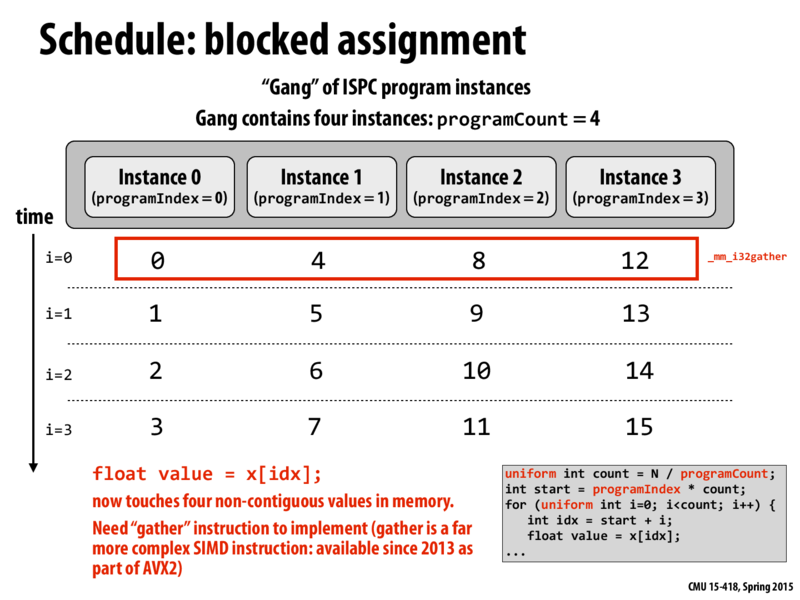
So I gather (no pun intended) that scheduling the work this way is less efficient than what we had on the previous slide?
That is indeed true. During the lecture, Kayvon mentioned that gather instructions takes a lot resources/time to retrieve the data whereas the load instruction is much cheaper and less intensive. When the entire program executes, they end up doing the same operation but since load operation i.e. <0,1,2,3> as opposed to gather which is <0,4,8,12>, does less work, it would be preferable to use it.
One question I would like to add to this point is that when would we want to use gather rather than load?
When it's fundamentally required by the program logic. See slide 63 of this lecture.
Are there some situations that block assignment will be better? Like will block assignment be better than interleaved assignment when we use multi-core parallelization (like task in ispc)? I think that block assignment has some good properties like good locality of each task, which should help improve cache hit rate and boost the speed.
@zhanpenf I'd disagree on the claim that block assignment has better task locality. With interleaved assignment, any one of the program instances operating on a vector of data can load in data for the other program instances. If all the program instances are operating on a cache-line of data, only one program instance will take a cache miss, while the remaining program instances will benefit from cache hits.
On the other hand, a blocked assignment will lead to each program instance loading in potentially different cache lines.
@arjunh Do you know if there are any performance benchmarks on the latency of a 'gather' vs. 'packed load'?
I think there are scenarios in which blocked assignment can yield better performance than the interleaved assignment. Consider a scenario in which we have more than onetask running on one core.
In the interleaved assignment, we expect the cache to have 1 miss per line, which will require a packed load each time.
In the blocked assignment, the processor can hide the latency of the gather with multi-threading, and then benefit from three cache hits in a row. I suppose the interleaved assignment could multi-threaded as well in this scenario, but gather seems to load more data in the cache because of latency hiding.
Oh, and I guess all of this assumes no pre-fetching.
Cache line size and program count (gang size) also plays a big role in determining where interleaved assignment or blocked assignment is better because if cache line size is 16 bytes and program count is 16, then in single load we can fetch 16 bytes that can be used by 1 set of gang in interleaved execution and 16 set of gangs in blocked assignment. It also depends of number of parallel tasks running, cache eviction based on address access by other tasks and how much of additional overhead incurred by memory_gather operation over memory_load.