So how would one go about "exploiting locality" in a NUMA model as opposed to the traditional of way using locality for caching and such? Or in other words, what would a programmer do differently in a NUMA model to gain performance?
Zarathustra
This is where the increased programmer effort would come in, I would think. If two cores need to share information across the interconnect, and they have non uniform access to memory, then I would think that something like considering which memory addresses were faster to access for each core and then storing shared data in some compromise location would be required. That said, if virtual memory were being used (very likely), this becomes very difficult since know where exactly the information you're storing is becomes next to impossible. So maybe that's where the "finding" part of exploiting locality comes in - figure out which memory which cores can access fast, and use that information to keep access to memory as fast as you can with respect to all the cores that need access to it.
sgbowen
So, on that note, how exactly does the programmer "find" or know what memory is local for a given core? Are there library calls which makes this information available, or does the programmer have to test different locations and measure latency on their own?
Also, are the latency/bandwidth changes continuous based on physical distance between a particular section of memory and a given core? Or is it more like some memory is "local" with latency x, and some memory is "non-local" with latency y (so that it's divided into only two classes)?
arjunh
@everyone Great question! It turns out that there are API's that allow programmers to further specify where threads get executed/where memory is allocated.
For instance, you can define the 'affinity' of a thread to a particular node (avoiding situations where a thread gets 'migrated' to another node, which would lead to severe performance issues due to the NUMA processor layout).
A programmer can also configure the location of memory page allocations, either implicitly via 'hints' to the OS (with appropriately designed memory access patterns) or explicitly, using API's such as libnuma.
Of course, you have to really know what you're doing once you start tinkering at this level, since most OS's do a pretty good job of managing these resources. But if you're working on the kernel of a supercomputer, you definitely need this level of control.
For more details, see this. There is also an amazing paper that talk more about this here. Jump to the section on NUMA programming (although the entire paper is incredibly relevant to this class, albeit in greater detail in some sections and with more emphasis on the actual API's available to programmers).
xwenwenwen
I'm not sure about the idea of "scalable". Does it just mean bandwidth? If it is, then how NUMA design provides more scalability? In other words, how bandwidth scales with the number of nodes(is it equivalent to processors?) given that the access time is not uniform? I'm still a little bit confused with the second bullet point.
afa4
@xwenwenwen: The question here is does a particular implementation of shared address space scale with the number of Processors?
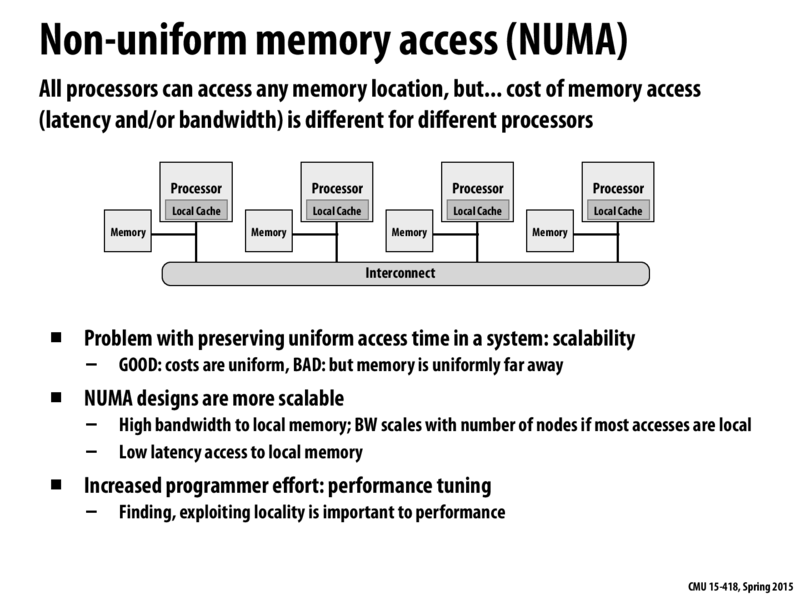
In case of Uniform Memory Access, all processors are connected to the memory via a shared bus or crossbar. Now this is fine if we only have a few processors. As the number of processors go on increasing to say a few thousands (like in supercomputers) this design of shared memory will not perform well because the shared memory bus will soon become a bottleneck.
As against this, in NUMA architecture all the processors can still access all of the memory and with some intelligent programming you can have most of your memory requests serviced from the processors' local memory. That's what the second bullet point means: NUMA designs have high BW and low latency access to local memory and scale well with the number of nodes/processors
So how would one go about "exploiting locality" in a NUMA model as opposed to the traditional of way using locality for caching and such? Or in other words, what would a programmer do differently in a NUMA model to gain performance?
This is where the increased programmer effort would come in, I would think. If two cores need to share information across the interconnect, and they have non uniform access to memory, then I would think that something like considering which memory addresses were faster to access for each core and then storing shared data in some compromise location would be required. That said, if virtual memory were being used (very likely), this becomes very difficult since know where exactly the information you're storing is becomes next to impossible. So maybe that's where the "finding" part of exploiting locality comes in - figure out which memory which cores can access fast, and use that information to keep access to memory as fast as you can with respect to all the cores that need access to it.
So, on that note, how exactly does the programmer "find" or know what memory is local for a given core? Are there library calls which makes this information available, or does the programmer have to test different locations and measure latency on their own?
Also, are the latency/bandwidth changes continuous based on physical distance between a particular section of memory and a given core? Or is it more like some memory is "local" with latency x, and some memory is "non-local" with latency y (so that it's divided into only two classes)?
@everyone Great question! It turns out that there are API's that allow programmers to further specify where threads get executed/where memory is allocated.
For instance, you can define the 'affinity' of a thread to a particular node (avoiding situations where a thread gets 'migrated' to another node, which would lead to severe performance issues due to the NUMA processor layout).
A programmer can also configure the location of memory page allocations, either implicitly via 'hints' to the OS (with appropriately designed memory access patterns) or explicitly, using API's such as libnuma.
Of course, you have to really know what you're doing once you start tinkering at this level, since most OS's do a pretty good job of managing these resources. But if you're working on the kernel of a supercomputer, you definitely need this level of control.
For more details, see this. There is also an amazing paper that talk more about this here. Jump to the section on NUMA programming (although the entire paper is incredibly relevant to this class, albeit in greater detail in some sections and with more emphasis on the actual API's available to programmers).
I'm not sure about the idea of "scalable". Does it just mean bandwidth? If it is, then how NUMA design provides more scalability? In other words, how bandwidth scales with the number of nodes(is it equivalent to processors?) given that the access time is not uniform? I'm still a little bit confused with the second bullet point.
@xwenwenwen: The question here is does a particular implementation of shared address space scale with the number of Processors?
In case of Uniform Memory Access, all processors are connected to the memory via a shared bus or crossbar. Now this is fine if we only have a few processors. As the number of processors go on increasing to say a few thousands (like in supercomputers) this design of shared memory will not perform well because the shared memory bus will soon become a bottleneck.
As against this, in NUMA architecture all the processors can still access all of the memory and with some intelligent programming you can have most of your memory requests serviced from the processors' local memory. That's what the second bullet point means: NUMA designs have high BW and low latency access to local memory and scale well with the number of nodes/processors