Did we cover any scheduling technologies that could do this? So far we have been unable to schedule work like this and had to resort to interleaving/cutting up the work.
HingOn
@Berry given the costs of the tasks, we can write a scheduler that does this quite easily. We can implement the scheduler with a min-heap or max-heap to store the tasks, depending on whether you want to always schedule the shorter or longer tasks first.
bwf
@HingOn It would be great if we could write a scheduler like that, however it is often hard to tell how long each task will take to implement. We can make estimates about how long we think a task will take, but we can't always know for sure. Additionally, if you look at the comments on the next slide, using a single data to store your tasks can lead to cases where your worker threads stall if everyone needs to grab work at the same time.
ragnarok451
An example of a way to estimate the remaining time for a task being performed is shown here: http://www.cs.rutgers.edu/~pxk/416/notes/07-scheduling.html. Essentially, by measuring when computation versus data transfer is happening, it is possible to estimate the size of future computation.
caretcaret
In 15-359 Probability and Computing, we learned that many tasks have sizes that follow the Pareto distribution. Often, task sizes are modeled with an exponential distribution because it's more tractable.
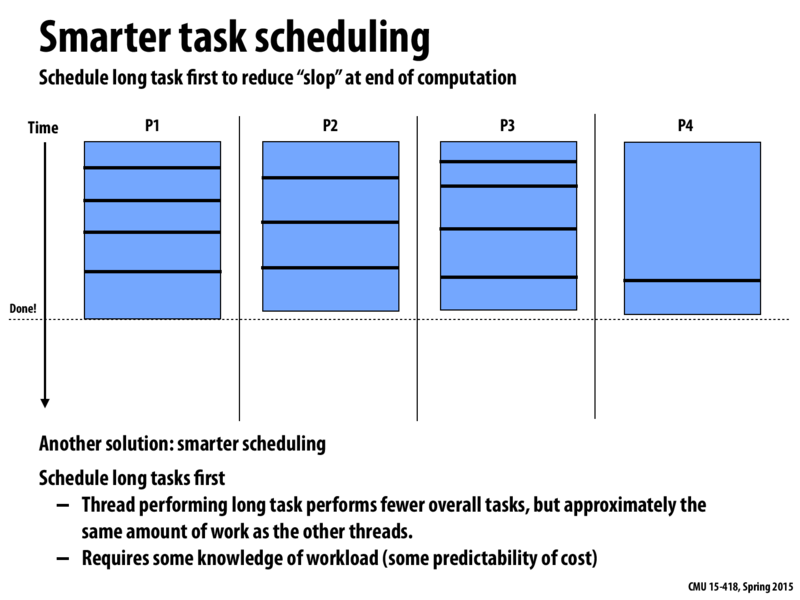
Did we cover any scheduling technologies that could do this? So far we have been unable to schedule work like this and had to resort to interleaving/cutting up the work.
@Berry given the costs of the tasks, we can write a scheduler that does this quite easily. We can implement the scheduler with a min-heap or max-heap to store the tasks, depending on whether you want to always schedule the shorter or longer tasks first.
@HingOn It would be great if we could write a scheduler like that, however it is often hard to tell how long each task will take to implement. We can make estimates about how long we think a task will take, but we can't always know for sure. Additionally, if you look at the comments on the next slide, using a single data to store your tasks can lead to cases where your worker threads stall if everyone needs to grab work at the same time.
An example of a way to estimate the remaining time for a task being performed is shown here: http://www.cs.rutgers.edu/~pxk/416/notes/07-scheduling.html. Essentially, by measuring when computation versus data transfer is happening, it is possible to estimate the size of future computation.
In 15-359 Probability and Computing, we learned that many tasks have sizes that follow the Pareto distribution. Often, task sizes are modeled with an exponential distribution because it's more tractable.