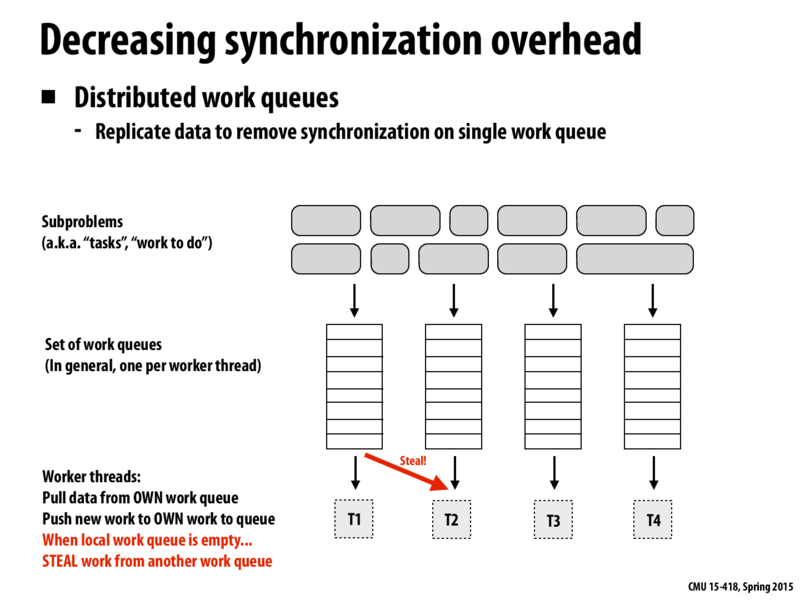
What is the benefit of having queues for each thread instead of having a single pool? It's not the race to secure each new unit of work because that happens with queues anyway when they load up work. So what is it?
paluri
@Berry. If I had to guess, I would suggest that perhaps it is, in fact, "the race to secure each new unit of work." If each worker had its own work queue, then after an initial (perhaps even rough) division of some work to each worker queue, they should never again have to wait for each other in competition for work (with some sort of lock mechanism on the work set). However, with only a single pool, you could imagine a situation (e.g., where all the work chunks are exactly the same size and the workers are exactly equal in speed) where the workers are frequently having to wait for each other to get work from the queue.
ericwang
This method is similar with Hadoop task scheduling design. In Hadoop, such queues are usually used to ensure data locality.
It is also mentioned in next slides that distributed work queues can increase task locality. But I think the locality here is more about memory locality or reducing communication requirement.
afa4
What is the meaning of "replicate data" here? Why do we need to replicate data?
kayvonf
Now that we've talked a bit about contention in class, can you imagine why multiple work queues might be a useful implementation in some circumstances?
lament
Simple one: you have a giant network running tons of threads, and you don't want each thread to have to go fetch from some centralized queue or queues.
aznshodan
Even though this might decrease the synchronization overhead, would there be an increase in scheduling overhead?
What is the benefit of having queues for each thread instead of having a single pool? It's not the race to secure each new unit of work because that happens with queues anyway when they load up work. So what is it?
@Berry. If I had to guess, I would suggest that perhaps it is, in fact, "the race to secure each new unit of work." If each worker had its own work queue, then after an initial (perhaps even rough) division of some work to each worker queue, they should never again have to wait for each other in competition for work (with some sort of lock mechanism on the work set). However, with only a single pool, you could imagine a situation (e.g., where all the work chunks are exactly the same size and the workers are exactly equal in speed) where the workers are frequently having to wait for each other to get work from the queue.
This method is similar with Hadoop task scheduling design. In Hadoop, such queues are usually used to ensure data locality.
It is also mentioned in next slides that distributed work queues can increase task locality. But I think the locality here is more about memory locality or reducing communication requirement.
What is the meaning of "replicate data" here? Why do we need to replicate data?
Now that we've talked a bit about contention in class, can you imagine why multiple work queues might be a useful implementation in some circumstances?
Simple one: you have a giant network running tons of threads, and you don't want each thread to have to go fetch from some centralized queue or queues.
Even though this might decrease the synchronization overhead, would there be an increase in scheduling overhead?