In lecture Kayvon talked about how it is possible to get slightly better throughput if we have more than 8 threads on a 4 core hyper-threaded machine by hiding I/O latency.
Can someone explain this again in detail? Specifically, how does having more that 8 threads improve our ability to hide I/O latency if our machine can only support 8 execution contexts (2 per core)?
iZac
If any thread faces long-latency misses (L1-L2 cache misses, Page faults), hardware can swap the thread out and thus help 'hide' the latency incurred, by running some other thread. Throughput would increase but not single thread latency!
kayvonf
@Kapteyn. Please have a look of how we hid "memory latency" using hardware multi-threading in Lecture 2. Now, can someone tell me how this slide is referring to the same concept, but a very different implementation of the same concept.
Kapteyn
I think a rough sketch of the way it is implemented is that the operating system maintains a TCB (thread control block) for each thread each thread which contains the execution context of the thread (stack pointer, program counter, state of thread, thread register values, pointer to process control block). These TCBs are in some queue managed by the OS scheduler
When the scheduler decides to rip a thread off of a core to allow another thread to run on that core (to hide I/O latency for example) there's an interrupt and the kernel stores the execution context of the thread on the kernel stack which exists in protected memory. Then the OS selects a thread from its queue to run on the freed up resources and pushes that thread's TCB from the kernel stack onto the execution context in the hardware.
solovoy
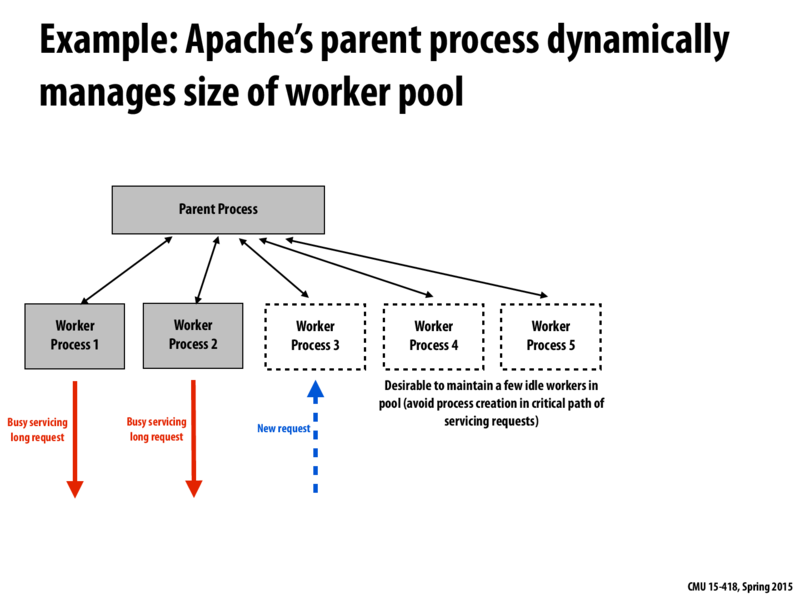
Actually, will Apache server maintain a idle worker pool consistently in real world?
BigFish
The same concept is that they both try to hide latency when there is some long-running requests. However, here it is implemented by processes instead of threads and let the OS to do the context switch.
gryffolyon
@Kapteyn, I guess the answer as Kayvon said in class is to do with hiding I/O if we have more than 8 threads on a 4 core hyper threaded system. This way we can achieve some more throughout. Of course after we certain limit, our footprint might go very large and we might see thrashing and gain nothing at all.
landuo
The concept here is to hide latency(memory, dis I/O, network etc.) by switching between different set of works. However, in lecture2 we discussed doing so using multi-thread execution while in this case the web server assigns each request to a process in order to prevent failure.
gryffolyon
@landuo, yes indeed. Nice distinction. We deal with processes here for all the reasons of security we went over in class
apoms
Most high performance web servers these days use an event driven approach to handling requests. In a traditional web server, every I/O operation (a syscall, disk read, network request) blocks the calling thread until it completes. The workaround for this issue is to oversubscribe our system by launching threads or processes for each request thus allowing the OS to hide the latency by unscheduling those blocked tasks. This approach works great for a small number of concurrent requests because we only need to allocate a few threads or processes at any one time.
However, today's web sites must serve hundreds of thousands of concurrent requests to meet the demands of their users. In a traditional server as described above, this is simply impossible for two main reasons. First, in order to serve 100,000 concurrent requests, the web server must allocate 100,000 thread or process contexts. On a Linux server, the default thread stack size is 2 MB meaning that the web server would need 200 GB of memory JUST to hold the initial thread state -- not even counting all of the other memory required during the execution of the thread. This issue is even worse for a process context. Second, every time a thread finishes or performs some I/O, it must be ripped off the processor using expensive system calls and context switches. Each of these context switches can take hundreds of cycles leading to untenable overhead and the OS now must manage scheduling for thousands of unique threads.
In response to these two issues, web servers now take advantage of special non-blocking operations for performing system calls, disk I/O, network requests, etc to avoid spawning a unique task or process context per request. The main idea here is that we can decouple accepting and responding to web requests from the work to process a request by storing newly accepted requests in a work queue and storing processed request results in an output queue. By explicitly enumerating our outstanding tasks instead of punting them onto the OS we are now free to process these queues in whatever schedule we so desire and using whatever execution resources we want.
There are two main ways to abstract and implement this architecture which I'll go over another time.
In lecture Kayvon talked about how it is possible to get slightly better throughput if we have more than 8 threads on a 4 core hyper-threaded machine by hiding I/O latency.
Can someone explain this again in detail? Specifically, how does having more that 8 threads improve our ability to hide I/O latency if our machine can only support 8 execution contexts (2 per core)?
If any thread faces long-latency misses (L1-L2 cache misses, Page faults), hardware can swap the thread out and thus help 'hide' the latency incurred, by running some other thread. Throughput would increase but not single thread latency!
@Kapteyn. Please have a look of how we hid "memory latency" using hardware multi-threading in Lecture 2. Now, can someone tell me how this slide is referring to the same concept, but a very different implementation of the same concept.
I think a rough sketch of the way it is implemented is that the operating system maintains a TCB (thread control block) for each thread each thread which contains the execution context of the thread (stack pointer, program counter, state of thread, thread register values, pointer to process control block). These TCBs are in some queue managed by the OS scheduler
When the scheduler decides to rip a thread off of a core to allow another thread to run on that core (to hide I/O latency for example) there's an interrupt and the kernel stores the execution context of the thread on the kernel stack which exists in protected memory. Then the OS selects a thread from its queue to run on the freed up resources and pushes that thread's TCB from the kernel stack onto the execution context in the hardware.
Actually, will Apache server maintain a idle worker pool consistently in real world?
The same concept is that they both try to hide latency when there is some long-running requests. However, here it is implemented by processes instead of threads and let the OS to do the context switch.
@Kapteyn, I guess the answer as Kayvon said in class is to do with hiding I/O if we have more than 8 threads on a 4 core hyper threaded system. This way we can achieve some more throughout. Of course after we certain limit, our footprint might go very large and we might see thrashing and gain nothing at all.
The concept here is to hide latency(memory, dis I/O, network etc.) by switching between different set of works. However, in lecture2 we discussed doing so using multi-thread execution while in this case the web server assigns each request to a process in order to prevent failure.
@landuo, yes indeed. Nice distinction. We deal with processes here for all the reasons of security we went over in class
Most high performance web servers these days use an event driven approach to handling requests. In a traditional web server, every I/O operation (a syscall, disk read, network request) blocks the calling thread until it completes. The workaround for this issue is to oversubscribe our system by launching threads or processes for each request thus allowing the OS to hide the latency by unscheduling those blocked tasks. This approach works great for a small number of concurrent requests because we only need to allocate a few threads or processes at any one time.
However, today's web sites must serve hundreds of thousands of concurrent requests to meet the demands of their users. In a traditional server as described above, this is simply impossible for two main reasons. First, in order to serve 100,000 concurrent requests, the web server must allocate 100,000 thread or process contexts. On a Linux server, the default thread stack size is 2 MB meaning that the web server would need 200 GB of memory JUST to hold the initial thread state -- not even counting all of the other memory required during the execution of the thread. This issue is even worse for a process context. Second, every time a thread finishes or performs some I/O, it must be ripped off the processor using expensive system calls and context switches. Each of these context switches can take hundreds of cycles leading to untenable overhead and the OS now must manage scheduling for thousands of unique threads.
In response to these two issues, web servers now take advantage of special non-blocking operations for performing system calls, disk I/O, network requests, etc to avoid spawning a unique task or process context per request. The main idea here is that we can decouple accepting and responding to web requests from the work to process a request by storing newly accepted requests in a work queue and storing processed request results in an output queue. By explicitly enumerating our outstanding tasks instead of punting them onto the OS we are now free to process these queues in whatever schedule we so desire and using whatever execution resources we want.
There are two main ways to abstract and implement this architecture which I'll go over another time.