I am not quite sure about what happened to this equation through ILP. Doesn't it happen because of the compiler made an optimization first? As we know, compilers also can smartly recognize the independence in three multiplies. What are the differences and connections between compiler optimization and ILP?
jiajunbl
@boats I think it is architecture dependent. In the general case, I believe the compiler does play a part in enabling ILP (in a sense that if I made created an execution trace where the values were dependent, then ILP would not take place). However, a compiler does not enable parallelism at a functional unit level, which is done on a hardware logic level. That said there seem to be exceptions such as VLIW, where the compiler is required to explicitly specify it.
I think the logic of ILP is on a similar level as that of branch prediction on a CPU, and part of the pipelining algorithm, but I may be wrong - if someone would like to clarify this.
BigFish
@boats I think the work of compiler is to turn your source code to some low level representation like assembly. However, without ILP the assembly instructions still need to be executed sequentially even given that there may be independence. In my understanding, what ILP does it to exploit this independence and so can execute several different instructions parallelly given the specific hardware setting.
dsaksena
@boats what is shown in this slide is that even though our CPU can perform 3 arithmetic operations per clock cycle, we hardly use it!!! Our mathematical operation itself limits us as to how many operations per cycle we can do.
We do the 3 products first, that is BODMAS, gotta multiply first, nothing to do with poor compiler. Now we must add by taking 2 at a time and that limits us to use 2 more clock cycles which perform only 1 addition in each. The intention behind ILP was to do 3 arithmetic operations per cycle but we obviously have proved that is not the case.
The compiler here simply tries to use ILP best to do the 3 products together. A good question to ponder over is without ILP how many instructions would it take to do this operation?
Kapteyn
As mentioned briefly in class, the sum-reduce algorithm can sum an array of n numbers in O(logn) time with n/2 processors. After performing sum-reduce (the upsweep) on an array of numbers, there is a downsweep algorithm that can calculate the prefix sums for an array of numbers in O(logn) time as well.
Does anyone think that creating an adder than can sum more than two numbers at once would be worth it (as opposed to having several more two number adders)? Let's assume one already exists and it can be easily implemented into any system.
Aarow
@evanl Given that we can get a 3 adder for no extra cost, then why not! But if we take a look at just purely adding numbers in parallel, to add $n$ numbers, we would need $\log_2 n$ for 2-adders and $\log_3 n$ for 3-adders. I would guess that if looking at specialized computations that if the benefit from the constant ~1.5 factor would help then it would be good to look into - subject to the opportunity cost of having the chip and adding support in compilers to optimize it’s use.
hohoho
Still a bit confused here, according to the wikipedia page on superscalar http://en.wikipedia.org/wiki/Superscalar, it seems that the parallelism is achieved by dispatch tasks to different functional units. Does that mean that ILP is hardware limited? It I have 100 multiplications instead of 3 in the example, is it still ILP = 100?
kayvonf
@hohoho: Instruction level parallelism is a property of a program (it is determined by the dependencies between the program's instructions). ILP is a measure of how many instructions can potentially be executed in parallel. A particular processor will only have so many execution resources, and when there is more independent work than execution units to do it, then the processor's capabilities are the limiting factor.
However, as the next slide shows, for many common programs, it's hard to find many independent instructions in a single instruction stream. In these situations, no matter how many execution units a core has, performance will be limited by the fact that the program does not have sufficient parallelism.
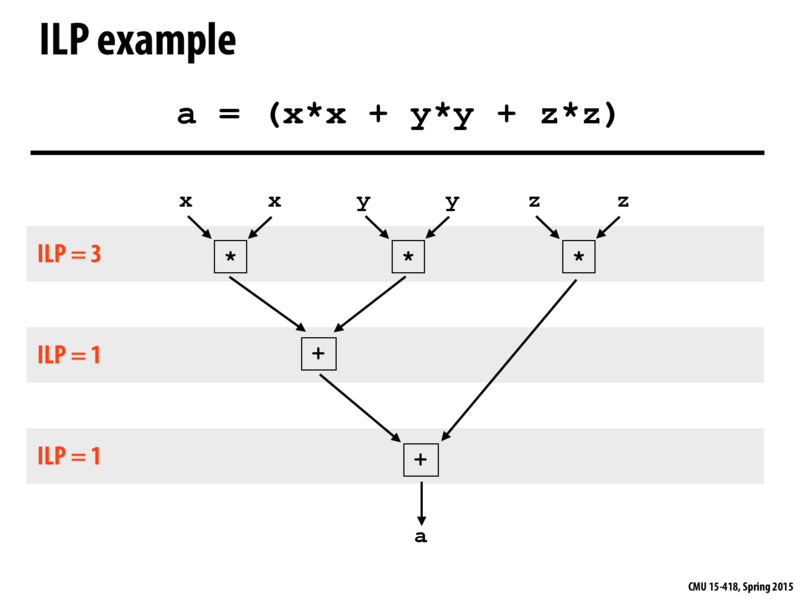
I am not quite sure about what happened to this equation through ILP. Doesn't it happen because of the compiler made an optimization first? As we know, compilers also can smartly recognize the independence in three multiplies. What are the differences and connections between compiler optimization and ILP?
@boats I think it is architecture dependent. In the general case, I believe the compiler does play a part in enabling ILP (in a sense that if I made created an execution trace where the values were dependent, then ILP would not take place). However, a compiler does not enable parallelism at a functional unit level, which is done on a hardware logic level. That said there seem to be exceptions such as VLIW, where the compiler is required to explicitly specify it.
I think the logic of ILP is on a similar level as that of branch prediction on a CPU, and part of the pipelining algorithm, but I may be wrong - if someone would like to clarify this.
@boats I think the work of compiler is to turn your source code to some low level representation like assembly. However, without ILP the assembly instructions still need to be executed sequentially even given that there may be independence. In my understanding, what ILP does it to exploit this independence and so can execute several different instructions parallelly given the specific hardware setting.
@boats what is shown in this slide is that even though our CPU can perform 3 arithmetic operations per clock cycle, we hardly use it!!! Our mathematical operation itself limits us as to how many operations per cycle we can do.
We do the 3 products first, that is BODMAS, gotta multiply first, nothing to do with poor compiler. Now we must add by taking 2 at a time and that limits us to use 2 more clock cycles which perform only 1 addition in each. The intention behind ILP was to do 3 arithmetic operations per cycle but we obviously have proved that is not the case.
The compiler here simply tries to use ILP best to do the 3 products together. A good question to ponder over is without ILP how many instructions would it take to do this operation?
As mentioned briefly in class, the sum-reduce algorithm can sum an array of n numbers in O(logn) time with n/2 processors. After performing sum-reduce (the upsweep) on an array of numbers, there is a downsweep algorithm that can calculate the prefix sums for an array of numbers in O(logn) time as well.
see paper: https://www.cs.cmu.edu/~guyb/papers/Ble93.pdf
Does anyone think that creating an adder than can sum more than two numbers at once would be worth it (as opposed to having several more two number adders)? Let's assume one already exists and it can be easily implemented into any system.
@evanl Given that we can get a 3 adder for no extra cost, then why not! But if we take a look at just purely adding numbers in parallel, to add $n$ numbers, we would need $\log_2 n$ for 2-adders and $\log_3 n$ for 3-adders. I would guess that if looking at specialized computations that if the benefit from the constant ~1.5 factor would help then it would be good to look into - subject to the opportunity cost of having the chip and adding support in compilers to optimize it’s use.
Still a bit confused here, according to the wikipedia page on superscalar http://en.wikipedia.org/wiki/Superscalar, it seems that the parallelism is achieved by dispatch tasks to different functional units. Does that mean that ILP is hardware limited? It I have 100 multiplications instead of 3 in the example, is it still ILP = 100?
@hohoho: Instruction level parallelism is a property of a program (it is determined by the dependencies between the program's instructions). ILP is a measure of how many instructions can potentially be executed in parallel. A particular processor will only have so many execution resources, and when there is more independent work than execution units to do it, then the processor's capabilities are the limiting factor.
However, as the next slide shows, for many common programs, it's hard to find many independent instructions in a single instruction stream. In these situations, no matter how many execution units a core has, performance will be limited by the fact that the program does not have sufficient parallelism.