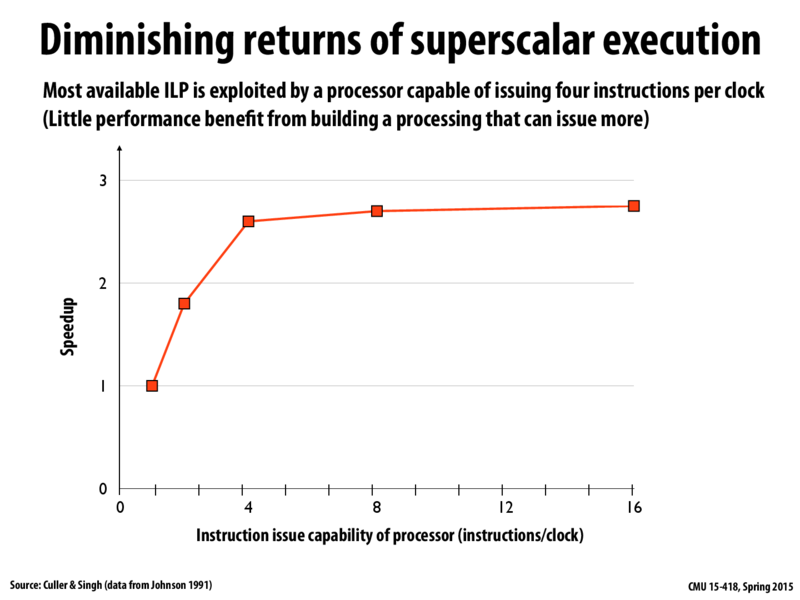
I have a question here. Is there any reason why it improves less when the the instruction issue capability of processors is greater than 4?
kayvonf
@ESINNG: How does the example on the previous slide shed light on your question? (someone can jump in an help us with an answer)
BigFish
@ESINNG In my point of view, when there are more processors, the time taken to synchronize the work between different processors grow more expensive quickly. Also, it may takes much more time to exchange messages when there are many processors. So although each individual processor may finish faster due to less work, the time taken to synchronize work can make the speedup improve less.
kayvonf
@BigFish: this graph's horizontal access is the number of execution units present in a single processor, not the number of processors in a multi-processor system. Another way to say say it is:
The maximum amount of operations that can be executed in a single clock, OR...
Question for @BigFish: Does this change your answer at all?
Question for anyone: Can someone give me a good definition of what I mean by "how much ILP a processor is about to exploit?"
TypicalChazz
I think data dependency is what you're referring to. Instruction level parallelism will always be limited by the data dependencies set forth by the programmer in his/her source code. The hardware is contractually bound to obey these data dependencies. Since most programs(if not all) have some sort of data dependencies, it makes sense that there would be a limit to how much ILP a process could exploit.
rbcarlso
@kayvonf: "How much ILP a processor is about to exploit" means the number of (contiguous? almost contiguous?) upcoming instructions that are independent from each other, which means they could be executed in arbitrary order and produce the same behavior. For example
INC A
INC B
is no different than
INC B
INC A
so the single CPU can have two execution units execute both lines at the same time. The amount of ILP in this example is 2.
@ESINNG: The diminishing returns come from the fact that most sequential programs are inherently sequential. If the result from step 10 depends on the result from step 8, you cannot perform steps 10 and 8 in parallel, they must be done in sequence. The idea is that the ability to do 16 things at once is worthless if you almost never have more than four things that you can do at a time without changing the result.
ESINNG
@rbcarlso, @kayvonf : Yes, I know it. And thank you for explaining it.
But my question is that why we almost never have more than four things at a time without changing the result? Is it because that the compiler can't optimize the program well or something else? Can we do something to improve it?
@TypicalChazz: Maybe, you are right and it's just a common law for the programs we write.
Thank you all.
kayvonf
@ESINNG. Yup, you've got it now. As @rbcarlso notes, this graph reports that across a selection of benchmark programs, in practice, the available ILP in the programs was rarely greater than four. Therefore, a processor that had the capability to look for and execute more than four operations per clock would not fully utilize its capability. (That capability goes to waste.)
BigFish
@ESINNG @kayvonf Sorry for misunderstood the question! Yes, I agree with @rbcarlso. It has something to do with the program logic. Many instructions of a program are actually dependent so that they cannot be executed parallelly. Maybe four is a magic number here to get the most tradeoff between speedup and efficiency.
jslone
It seems that if sequential programs were written with ILP in mind and data dependencies were minimized we would start to get diminishing returns much later. I wonder if this was taken into account when the data was collected, or if the benchmarks were based off existing code.
kayvonf
@jslone: "It seems that if sequential programs were written with ILP in mind..." True, but a critical design point of superscalar execution is for the processor to "find the parallelism automatically" without any changes to a program. No recompiles, no knowledge of the underlying architecture, etc.
If you're willing to modify software so that it runs faster given details of the parallel hardware, you're now parallel programming! (So your suggestion is right on, but it does entail software changes.)
evanl
Is this graph based on the running of a single process? Also, would it be possible to apply ILP to multiple processes (e.g. run two different instructions from two different processes on the same processor in parallel)?
jslone
@kayvonf Right, it just seems like a shame to limit the hardware based on software not completely utilizing it. It seems like ILP would have less overhead than a lot of other parallel methods since the single processor would be sharing the same registers and L1 cache, and synchronization is being handled by the hardware.
top
@jslone It seems to me that trying to program with ILP in mind would be just as hard if not harder than doing so with typical methods such as CUDA or other languages we will learn in the class. I think getting rid of this complexity was a design goal and it seems the hardware designers achieved it with then only caveat that we live with 4 being a sort of magic number here. I'm sure if someone REALLY needed the speedup though it would not be a bad idea to look into ILP after using other parallel methods as well.
Berry
If the key takeaway from lecture 1 was that synchronizing communication between "workers" is the primary cause of less than perfect parallelization then why is it that spending the resources to facilitate ILP's is more efficient than spending them on getting really good at sequential evaluation? After all the parallelism provides significant speedups at the cost of significantly more resources. All of this points towards ILP's somehow accounting for a similar "ghz barrier" equivalent exiting in the realm of instructions. If so what is it?
toutou
I have some questions here. Is pipeline an ILP? If so, why the pipeline stages of a microprocessor can be up to 30 since there is little performance improvement from 4 instructions per clock?
MediumPepsi
@toutou I think pipeline is different from ILP. Pipeline is like the drive through in McDonalds. A person handles the order of the first customer, another is the cashier for the second customer and the other gives the third customer the food. This improves the throughput. If you have the three people standing at the same window serving the same customer, two of them will have nothing to do. The same is true in CPU. While on instruction is writing to memory, the next one can be executed by ALU. So pipeline is to let different CPU component work at the same time, and there's no parallelism in pipeline. ILP is to let several copies of the same CPU component work at the same time. For example, three ALUs execute three independent instructions simultaneously. Someone corrects me if I'm wrong.
I have a question here. Is there any reason why it improves less when the the instruction issue capability of processors is greater than 4?
@ESINNG: How does the example on the previous slide shed light on your question? (someone can jump in an help us with an answer)
@ESINNG In my point of view, when there are more processors, the time taken to synchronize the work between different processors grow more expensive quickly. Also, it may takes much more time to exchange messages when there are many processors. So although each individual processor may finish faster due to less work, the time taken to synchronize work can make the speedup improve less.
@BigFish: this graph's horizontal access is the number of execution units present in a single processor, not the number of processors in a multi-processor system. Another way to say say it is:
Question for @BigFish: Does this change your answer at all?
Question for anyone: Can someone give me a good definition of what I mean by "how much ILP a processor is about to exploit?"
I think data dependency is what you're referring to. Instruction level parallelism will always be limited by the data dependencies set forth by the programmer in his/her source code. The hardware is contractually bound to obey these data dependencies. Since most programs(if not all) have some sort of data dependencies, it makes sense that there would be a limit to how much ILP a process could exploit.
@kayvonf: "How much ILP a processor is about to exploit" means the number of (contiguous? almost contiguous?) upcoming instructions that are independent from each other, which means they could be executed in arbitrary order and produce the same behavior. For example
INC A INC B
is no different than
INC B INC A
so the single CPU can have two execution units execute both lines at the same time. The amount of ILP in this example is 2.
@ESINNG: The diminishing returns come from the fact that most sequential programs are inherently sequential. If the result from step 10 depends on the result from step 8, you cannot perform steps 10 and 8 in parallel, they must be done in sequence. The idea is that the ability to do 16 things at once is worthless if you almost never have more than four things that you can do at a time without changing the result.
@rbcarlso, @kayvonf : Yes, I know it. And thank you for explaining it. But my question is that why we almost never have more than four things at a time without changing the result? Is it because that the compiler can't optimize the program well or something else? Can we do something to improve it?
@TypicalChazz: Maybe, you are right and it's just a common law for the programs we write.
Thank you all.
@ESINNG. Yup, you've got it now. As @rbcarlso notes, this graph reports that across a selection of benchmark programs, in practice, the available ILP in the programs was rarely greater than four. Therefore, a processor that had the capability to look for and execute more than four operations per clock would not fully utilize its capability. (That capability goes to waste.)
@ESINNG @kayvonf Sorry for misunderstood the question! Yes, I agree with @rbcarlso. It has something to do with the program logic. Many instructions of a program are actually dependent so that they cannot be executed parallelly. Maybe four is a magic number here to get the most tradeoff between speedup and efficiency.
It seems that if sequential programs were written with ILP in mind and data dependencies were minimized we would start to get diminishing returns much later. I wonder if this was taken into account when the data was collected, or if the benchmarks were based off existing code.
@jslone: "It seems that if sequential programs were written with ILP in mind..." True, but a critical design point of superscalar execution is for the processor to "find the parallelism automatically" without any changes to a program. No recompiles, no knowledge of the underlying architecture, etc.
If you're willing to modify software so that it runs faster given details of the parallel hardware, you're now parallel programming! (So your suggestion is right on, but it does entail software changes.)
Is this graph based on the running of a single process? Also, would it be possible to apply ILP to multiple processes (e.g. run two different instructions from two different processes on the same processor in parallel)?
@kayvonf Right, it just seems like a shame to limit the hardware based on software not completely utilizing it. It seems like ILP would have less overhead than a lot of other parallel methods since the single processor would be sharing the same registers and L1 cache, and synchronization is being handled by the hardware.
@jslone It seems to me that trying to program with ILP in mind would be just as hard if not harder than doing so with typical methods such as CUDA or other languages we will learn in the class. I think getting rid of this complexity was a design goal and it seems the hardware designers achieved it with then only caveat that we live with 4 being a sort of magic number here. I'm sure if someone REALLY needed the speedup though it would not be a bad idea to look into ILP after using other parallel methods as well.
If the key takeaway from lecture 1 was that synchronizing communication between "workers" is the primary cause of less than perfect parallelization then why is it that spending the resources to facilitate ILP's is more efficient than spending them on getting really good at sequential evaluation? After all the parallelism provides significant speedups at the cost of significantly more resources. All of this points towards ILP's somehow accounting for a similar "ghz barrier" equivalent exiting in the realm of instructions. If so what is it?
I have some questions here. Is pipeline an ILP? If so, why the pipeline stages of a microprocessor can be up to 30 since there is little performance improvement from 4 instructions per clock?
@toutou I think pipeline is different from ILP. Pipeline is like the drive through in McDonalds. A person handles the order of the first customer, another is the cashier for the second customer and the other gives the third customer the food. This improves the throughput. If you have the three people standing at the same window serving the same customer, two of them will have nothing to do. The same is true in CPU. While on instruction is writing to memory, the next one can be executed by ALU. So pipeline is to let different CPU component work at the same time, and there's no parallelism in pipeline. ILP is to let several copies of the same CPU component work at the same time. For example, three ALUs execute three independent instructions simultaneously. Someone corrects me if I'm wrong.