So how does warp fit into this picture? I want to verify my understanding:
- Blocks are concepts and they don't correspond to any actual hardware. The reason for blocks to exist is for programmers to take advantage of the shared memory within a block.
- When the programmer tells the scheduler to run a block of 128 threads, in the hardware implementation, it maps 4 warps to those blocks. And assign this block to some core.
kayvonf
@pavelkang. Good question, I purposely left warps out of this illustrative sequence to emphasize that they are very much an implementation detail (notice we discuss how warps fit into the picture at the end).
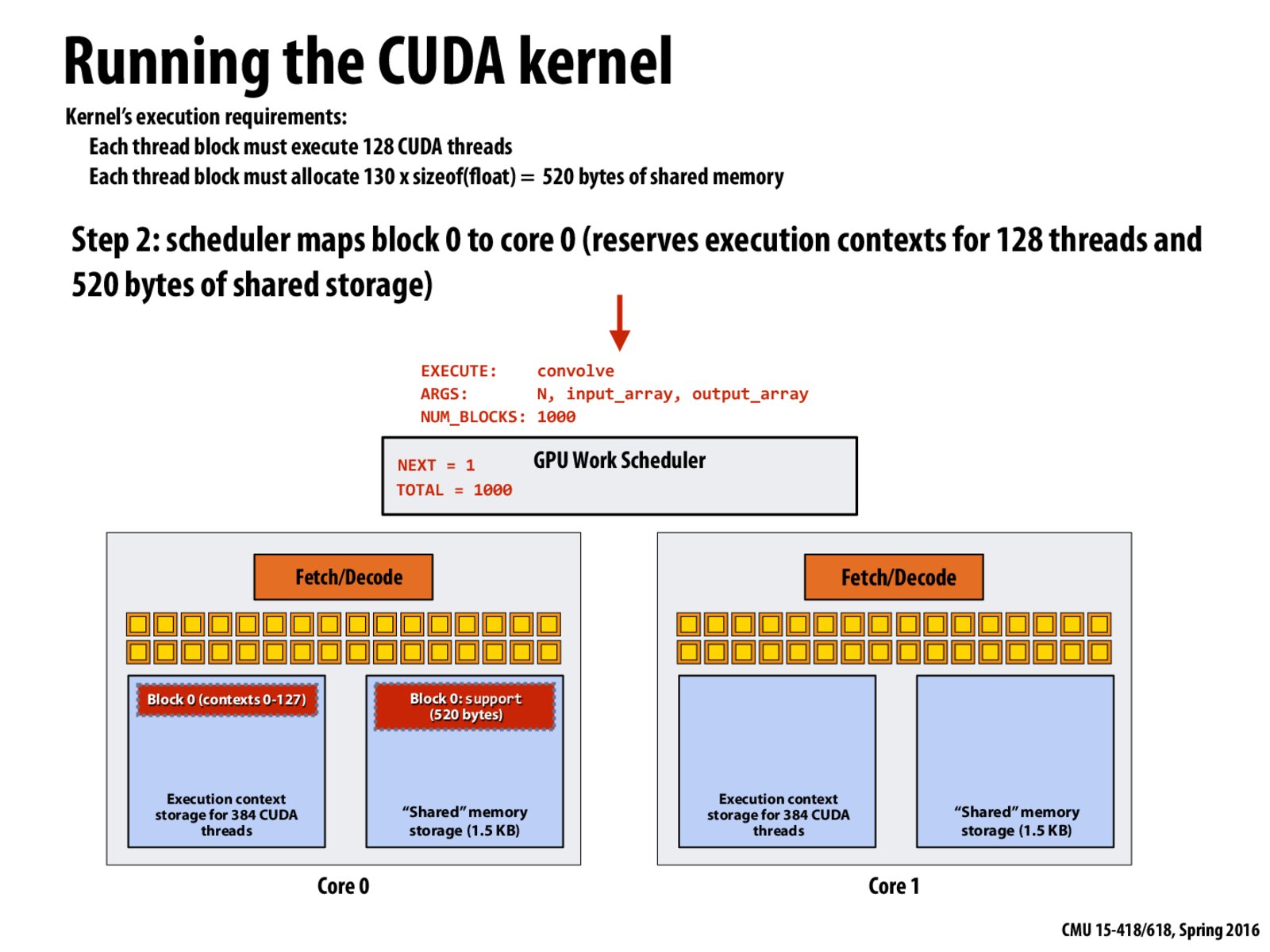
Running a CUDA thread block involves running some number of CUDA threads. In this example, a thread block for the convolve kernel involves 128 CUDA threads. (This number was given in the CUDA program, initially shown on slide 47.)
To run a thread on a piece of hardware, we need an HW execution context to run it. Above, I've illustrated the fact that to map a thread block to a core, the system needs to reserve 128 thread execution contexts.
Groups of 32 consecutive CUDA threads, or said differently, 32 execution contexts share and instruction stream and execute in SIMD fashion. These 32 threads are called a warp. It would be perfectly fine (and equivalent) in this diagram to say that each core supports up to 384/32 = 12 warp execution contexts, and that when mapping a thread block to a core, the GPU reserves four warp execution contexts (rather than 128 CUDA thread execution contexts).
cyl
In CPU and GPU we both execute the SIMD instruction to N contexts. But looks like in GPU we call each context as CUDA threads, is that true?
By the way, is the SIMD contexts in CPU hardware divided?
xingdaz
@kayvonf, to check my understanding, for each "warp" of Block0, does warp0 completes, then warp1 goes and it cascades down to warp11, OR they are interleaved?
kayvonf
@xingdaz. Their execution will be interleaved. In fact, the pipelining example from Lecture 7 suggests one reason why. Given that simple instruction pipeline, after a thread executes an instruction, it takes four cycles for the instruction to complete. This is a latency, much like a memory latency, that can cause stalls if instructions in an instruction stream are dependent. Well, with multi-threading, the core can just switch to a new warp on each cycle, and so there will never be a problem with stalls due to dependent instructions in a warp.
xingdaz
@kayvonf. So "runs to completion" means the core will run block0 to completion and then go to another block. However, within a block, interweaving happens.
kayvonf
@xingdaz. Warps from different blocks can be interleaved on the core at the same time (just jump forward a few slides to slide 64.
However all the resources for a block (e.g., shared memory allocations, execution contexts) and its threads will not be freed until the entire block is complete (that is, all its threads have run to completion). Thats why when a block completes, and its resources are freed, there's now available resources to schedule a new block onto the core.
So how does warp fit into this picture? I want to verify my understanding: - Blocks are concepts and they don't correspond to any actual hardware. The reason for blocks to exist is for programmers to take advantage of the shared memory within a block. - When the programmer tells the scheduler to run a block of 128 threads, in the hardware implementation, it maps 4 warps to those blocks. And assign this block to some core.
@pavelkang. Good question, I purposely left warps out of this illustrative sequence to emphasize that they are very much an implementation detail (notice we discuss how warps fit into the picture at the end).
Running a CUDA thread block involves running some number of CUDA threads. In this example, a thread block for the
convolvekernel involves 128 CUDA threads. (This number was given in the CUDA program, initially shown on slide 47.)To run a thread on a piece of hardware, we need an HW execution context to run it. Above, I've illustrated the fact that to map a thread block to a core, the system needs to reserve 128 thread execution contexts.
Groups of 32 consecutive CUDA threads, or said differently, 32 execution contexts share and instruction stream and execute in SIMD fashion. These 32 threads are called a warp. It would be perfectly fine (and equivalent) in this diagram to say that each core supports up to 384/32 = 12 warp execution contexts, and that when mapping a thread block to a core, the GPU reserves four warp execution contexts (rather than 128 CUDA thread execution contexts).
In CPU and GPU we both execute the SIMD instruction to N contexts. But looks like in GPU we call each context as CUDA threads, is that true?
By the way, is the SIMD contexts in CPU hardware divided?
@kayvonf, to check my understanding, for each "warp" of Block0, does warp0 completes, then warp1 goes and it cascades down to warp11, OR they are interleaved?
@xingdaz. Their execution will be interleaved. In fact, the pipelining example from Lecture 7 suggests one reason why. Given that simple instruction pipeline, after a thread executes an instruction, it takes four cycles for the instruction to complete. This is a latency, much like a memory latency, that can cause stalls if instructions in an instruction stream are dependent. Well, with multi-threading, the core can just switch to a new warp on each cycle, and so there will never be a problem with stalls due to dependent instructions in a warp.
@kayvonf. So "runs to completion" means the core will run block0 to completion and then go to another block. However, within a block, interweaving happens.
@xingdaz. Warps from different blocks can be interleaved on the core at the same time (just jump forward a few slides to slide 64.
And there's much more detail on slide 56.
However all the resources for a block (e.g., shared memory allocations, execution contexts) and its threads will not be freed until the entire block is complete (that is, all its threads have run to completion). Thats why when a block completes, and its resources are freed, there's now available resources to schedule a new block onto the core.