How is the throughput 1 instruction per cycle in this case? Is it because in one vertical section (one clock cycle) the maximum number of instructions possible is 4? Or is that the bandwidth?
arcticx
@captainFlint: Just look at the time of the end of execution of each instruction, we can see that at each timestamp, there will be one instruction finish. Therefore, the throughput is 1.
randomized
Can anyone please explain pipelining for the load statements (load X[j]) by the 2 worker threads for parts (A) and (B) of Exercise 1?
PandaX
Another good example is GPU rendering pipeline!
bmperez
Well, @randomized, for parts (A) and (B) of exercise 1 that isn't actually pipelining. That is an example of hardware multithreading, which is an orthogonal concept to pipelining.
Pipelining is for a single instruction stream, or "thread". Pipelining works by separating the sub-tasks required to execute an instruction into separate stages. This allows for the latency of individual instructions to be hidden. While one instruction executes, another can begin executing. The purpose of pipelining is to increase the clock frequency, because the amount of work that needs to be done per clock cycle is lower.
Hardware multi-threading, on the other hand, is for multiple instruction streams. This is when the processor shares its resources among 2 or more instruction streams. The basic idea is to have the processor fetch instructions from multiple instruction streams (in an interleaved manner, or at the same time if the processor is superscalar). Then, when one of the threads gets stalled for whatever reason (e.g. cache miss), the other thread can begin running to hide the latency of the first thread. Thus, the processor remains running even if one of the threads is stalled.
In Exercise 1, whenever one of the threads stalled on a cache miss, the other thread began running, using the processor's resources. This allows the latency of the cache miss to be hidden, because the second thread keeps the processor doing useful work while the first thread waits for the memory request to be serviced.
grizt
So just to be clear, what happens with this pipeline when you have a set of threads in a warp that are supposed to all execute in a SIMD-like fashion, and then there is a divergence in the code path? For example,
We saw that the above would perform much slower because of code divergence since it can no longer act in SIMD. What exactly is happening? Does it just try to execute the threads sequentially, or does it try to partition it into threads that have the same codepath? With respect to the slide above, if "doing something" takes only one cycle, do we see a 4x slowdown, or do the instructions on different threads still get pipelined together so that it only results in the loss of a single cycle per thread?
teamG
I've been thinking about whether breaking an instruction into more subtasks will actually improve the throughput, cause if we were to use the analogy, seems like intuitively, if more cars can be packed closer together, then the throughput is definitely higher.
However, thinking about it using the example above, seems like if were to have 5 smaller tasks, it actually decreases the throughput?
Also, as a followup question, @arcticx, shouldn't the throughput be 9/6? since there were 9 cycles and only 6 instructions finished during that frame?
kayvonf
@teamG. Good question.
If you broke the problem of executing an instruction into, say, 10 smaller steps, then each of those steps could get done in a shorter amount of time. Because of this, architects would be able to increase the clock rate of the processor (shorter clock period) and thus throughput would increase (you'd still be completing one instruction per clock, but the clock rate is higher).
So in the analogy with driving, cutting the road up into many little pieces (aka letting the cars runs closer together) would be like breaking an instruction into many small steps. Each step takes a small amount of time, much like how a car traverses a small part of the road in a short amount of time.
lol
@teamG The throughput is 1 instruction / cycle. You want to look at the steady-state rate, i.e. the limit when you do a large number of instructions. N instructions will complete in N + 3 cycles, so the throughput is N / (N + 3) which in the limit is 1.
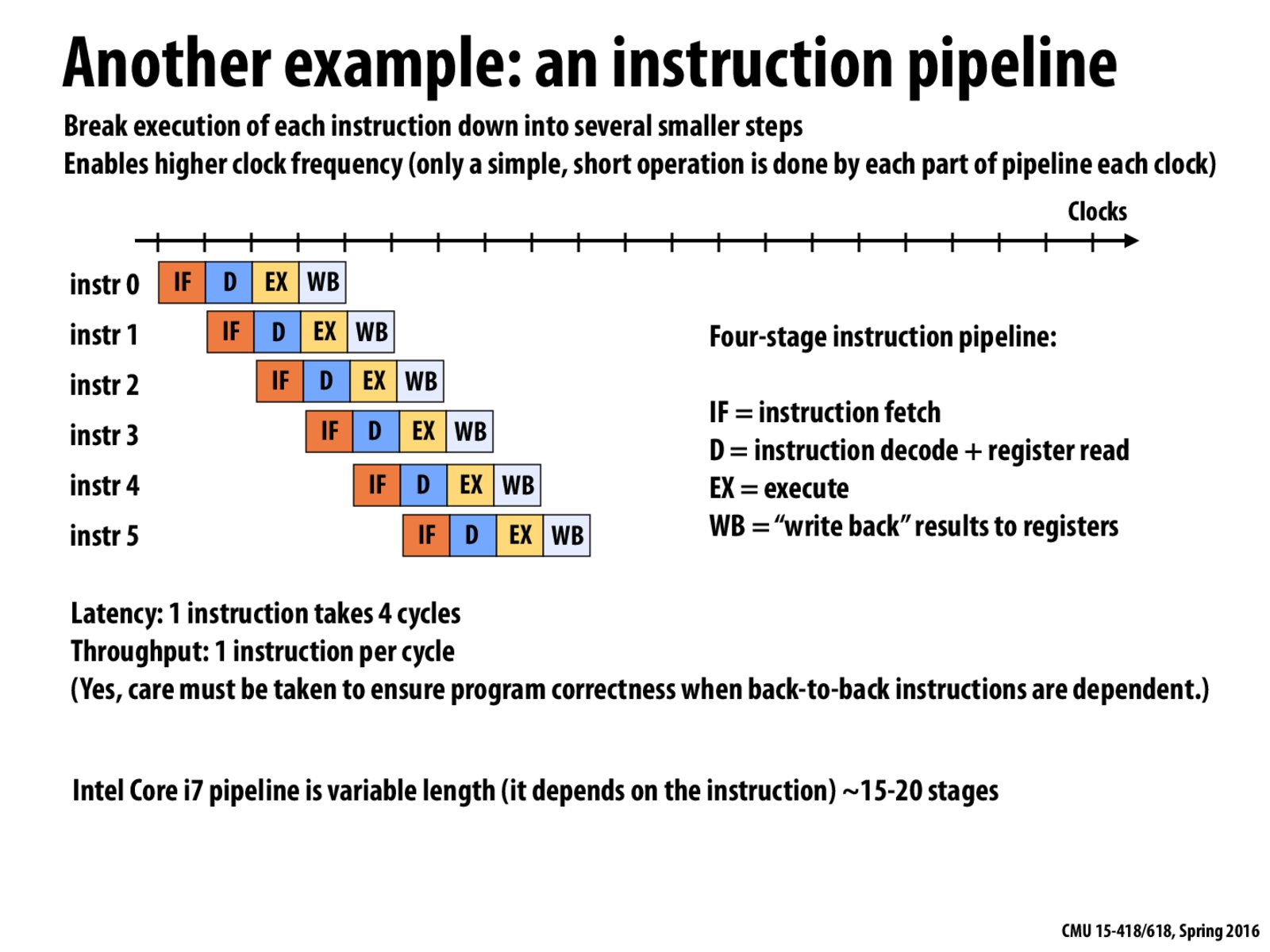
How is the throughput 1 instruction per cycle in this case? Is it because in one vertical section (one clock cycle) the maximum number of instructions possible is 4? Or is that the bandwidth?
@captainFlint: Just look at the time of the end of execution of each instruction, we can see that at each timestamp, there will be one instruction finish. Therefore, the throughput is 1.
Can anyone please explain pipelining for the load statements (load X[j]) by the 2 worker threads for parts (A) and (B) of Exercise 1?
Another good example is GPU rendering pipeline!
Well, @randomized, for parts (A) and (B) of exercise 1 that isn't actually pipelining. That is an example of hardware multithreading, which is an orthogonal concept to pipelining.
Pipelining is for a single instruction stream, or "thread". Pipelining works by separating the sub-tasks required to execute an instruction into separate stages. This allows for the latency of individual instructions to be hidden. While one instruction executes, another can begin executing. The purpose of pipelining is to increase the clock frequency, because the amount of work that needs to be done per clock cycle is lower.
Hardware multi-threading, on the other hand, is for multiple instruction streams. This is when the processor shares its resources among 2 or more instruction streams. The basic idea is to have the processor fetch instructions from multiple instruction streams (in an interleaved manner, or at the same time if the processor is superscalar). Then, when one of the threads gets stalled for whatever reason (e.g. cache miss), the other thread can begin running to hide the latency of the first thread. Thus, the processor remains running even if one of the threads is stalled.
In Exercise 1, whenever one of the threads stalled on a cache miss, the other thread began running, using the processor's resources. This allows the latency of the cache miss to be hidden, because the second thread keeps the processor doing useful work while the first thread waits for the memory request to be serviced.
So just to be clear, what happens with this pipeline when you have a set of threads in a warp that are supposed to all execute in a SIMD-like fashion, and then there is a divergence in the code path? For example,
We saw that the above would perform much slower because of code divergence since it can no longer act in SIMD. What exactly is happening? Does it just try to execute the threads sequentially, or does it try to partition it into threads that have the same codepath? With respect to the slide above, if "doing something" takes only one cycle, do we see a 4x slowdown, or do the instructions on different threads still get pipelined together so that it only results in the loss of a single cycle per thread?
I've been thinking about whether breaking an instruction into more subtasks will actually improve the throughput, cause if we were to use the analogy, seems like intuitively, if more cars can be packed closer together, then the throughput is definitely higher.
However, thinking about it using the example above, seems like if were to have 5 smaller tasks, it actually decreases the throughput?
Also, as a followup question, @arcticx, shouldn't the throughput be 9/6? since there were 9 cycles and only 6 instructions finished during that frame?
@teamG. Good question.
If you broke the problem of executing an instruction into, say, 10 smaller steps, then each of those steps could get done in a shorter amount of time. Because of this, architects would be able to increase the clock rate of the processor (shorter clock period) and thus throughput would increase (you'd still be completing one instruction per clock, but the clock rate is higher).
So in the analogy with driving, cutting the road up into many little pieces (aka letting the cars runs closer together) would be like breaking an instruction into many small steps. Each step takes a small amount of time, much like how a car traverses a small part of the road in a short amount of time.
@teamG The throughput is 1 instruction / cycle. You want to look at the steady-state rate, i.e. the limit when you do a large number of instructions. N instructions will complete in N + 3 cycles, so the throughput is N / (N + 3) which in the limit is 1.