You can $perf(r)$ as the effective number cores a larger (or smaller) core is equivalent, comparing to some base unit. So if the large core is effectively $perf(r)$ cores, then the total number of effective cores are $(n-r) + perf(r)$. So we get the speedup of $\frac{f}{(n-r) + perf(r)}$.
mperron
I would imagine that as the number of different types of cores increase on a single chip, scheduling would become a more difficult problem. How do modern processors and operating systems make these decisions? Does this complicate things in terms of compilation. For instance, since, presumably Intel integrated graphics and Nvidia GPUs have different instruction sets, Can we write programs which take advantage of Heterogeneity without being aware of particular hardware?
arcticx
Here is how I understand the formula (same idea applies to previous ones):
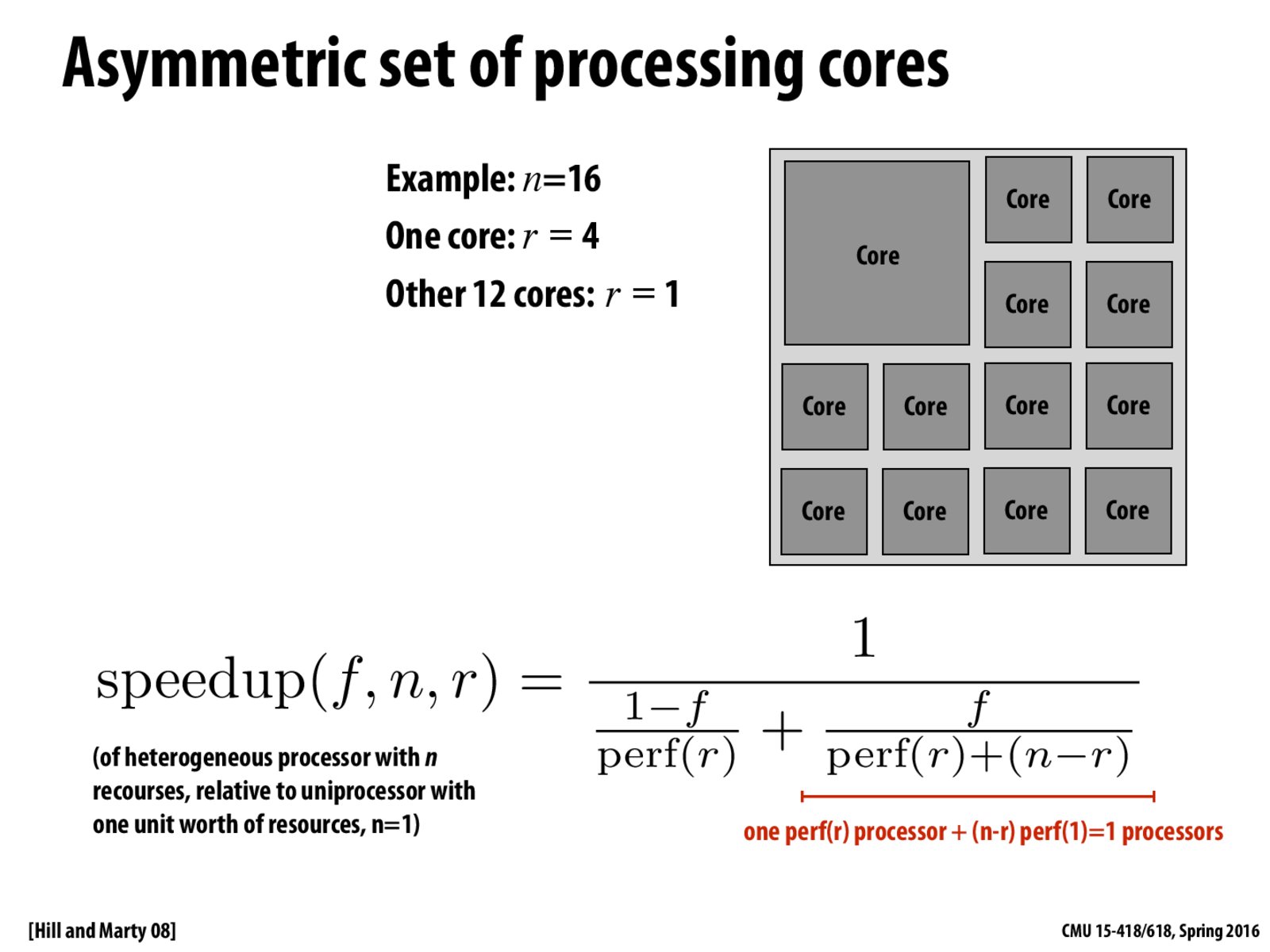
$perf(r)$ is the performance of that single fat core. $r$ here represents how many how many computing resource (transistors) on a core. $perf(r)$ can be $r$ or $<r$ or $>r$, depending on how these $r$ computing resources work in concert.
$(n-r)$ represents the number of the smaller cores, as we are assuming each of those smaller cores only has one computing unit.
Now, the whole formula looks exactly like the original Amdahl's law.
bojianh
I think it is possible to derive a more generalized version of this Amdahl's law for more than 2 types of processors using something like a summation of all the performance from all the cores.
chuangxuean
I am also interested in how the system/programmer is able to make use of the heterogenous nature of the processor. For instance, is there some way the system can identify sequential dependencies in the code and hence assign these tasks to the "fat" core and/or the programmer explicitly assign these tasks to the cores as he wishes to exploit these capabilities.
where $r_{fat}$ and $r_{thin}$ are the resources available to the heterogeneous cores.
Josephus
In reference to sequential operation on one single-resource (r = 1) core,
parallelization over n resources, with one core using r resources and (n-r) cores using 1 resource,
with a fraction f of the runtime parallelized,
achieves a speedup of:
$$speedup(f,n,r) = {1 \over {{1-f} \over perf(r)} + {f \over {perf(r) + (n-r)}}}$$
where perf(r) is the speedup of an sequential operation on one r-resource core over sequential operation on one single-resource core.
yimmyz
@kayvon Just pointing out a minor typo: I think at the bottom-right, the denominator should be $perf(r) + perf(n-r)$.
EDIT: My comment is wrong -- see the two comments below.
lol
No it is correct as stated. $perf(n-r)$ implies there is a core of size $n-r$, but actually there are $n-r$ cores of size $1$.
Josephus
@yimmyz I don't think so - the red text seems to indicate that the denominator should be $1 * perf(r) + (n - r) * perf(1)$, where $perf(1)=1$. $perf$ is the performance of an individual core as a function of its resource count, relative to the performance of a single-resource core.
You can $perf(r)$ as the effective number cores a larger (or smaller) core is equivalent, comparing to some base unit. So if the large core is effectively $perf(r)$ cores, then the total number of effective cores are $(n-r) + perf(r)$. So we get the speedup of $\frac{f}{(n-r) + perf(r)}$.
I would imagine that as the number of different types of cores increase on a single chip, scheduling would become a more difficult problem. How do modern processors and operating systems make these decisions? Does this complicate things in terms of compilation. For instance, since, presumably Intel integrated graphics and Nvidia GPUs have different instruction sets, Can we write programs which take advantage of Heterogeneity without being aware of particular hardware?
Here is how I understand the formula (same idea applies to previous ones):
$perf(r)$ is the performance of that single fat core. $r$ here represents how many how many computing resource (transistors) on a core. $perf(r)$ can be $r$ or $<r$ or $>r$, depending on how these $r$ computing resources work in concert.
$(n-r)$ represents the number of the smaller cores, as we are assuming each of those smaller cores only has one computing unit.
Now, the whole formula looks exactly like the original Amdahl's law.
I think it is possible to derive a more generalized version of this Amdahl's law for more than 2 types of processors using something like a summation of all the performance from all the cores.
I am also interested in how the system/programmer is able to make use of the heterogenous nature of the processor. For instance, is there some way the system can identify sequential dependencies in the code and hence assign these tasks to the "fat" core and/or the programmer explicitly assign these tasks to the cores as he wishes to exploit these capabilities.
Perhaps it is clearer to do state the following:
$$ speedup(f,n,r) = {1 \over {{{1-f} \over perf(r_{fat})} + {f \over {perf(r_{fat}) + {{n-r_{fat}} \over r_{thin}} * perf(r_{thin})}}}} $$
where $r_{fat}$ and $r_{thin}$ are the resources available to the heterogeneous cores.
In reference to sequential operation on one single-resource (r = 1) core, parallelization over n resources, with one core using r resources and (n-r) cores using 1 resource, with a fraction f of the runtime parallelized, achieves a speedup of: $$speedup(f,n,r) = {1 \over {{1-f} \over perf(r)} + {f \over {perf(r) + (n-r)}}}$$ where perf(r) is the speedup of an sequential operation on one r-resource core over sequential operation on one single-resource core.
@kayvon Just pointing out a minor typo: I think at the bottom-right, the denominator should be $perf(r) + perf(n-r)$.
EDIT: My comment is wrong -- see the two comments below.
No it is correct as stated. $perf(n-r)$ implies there is a core of size $n-r$, but actually there are $n-r$ cores of size $1$.
@yimmyz I don't think so - the red text seems to indicate that the denominator should be $1 * perf(r) + (n - r) * perf(1)$, where $perf(1)=1$. $perf$ is the performance of an individual core as a function of its resource count, relative to the performance of a single-resource core.
@lol @Josephus Gotcha, that makes sense. Thanks!