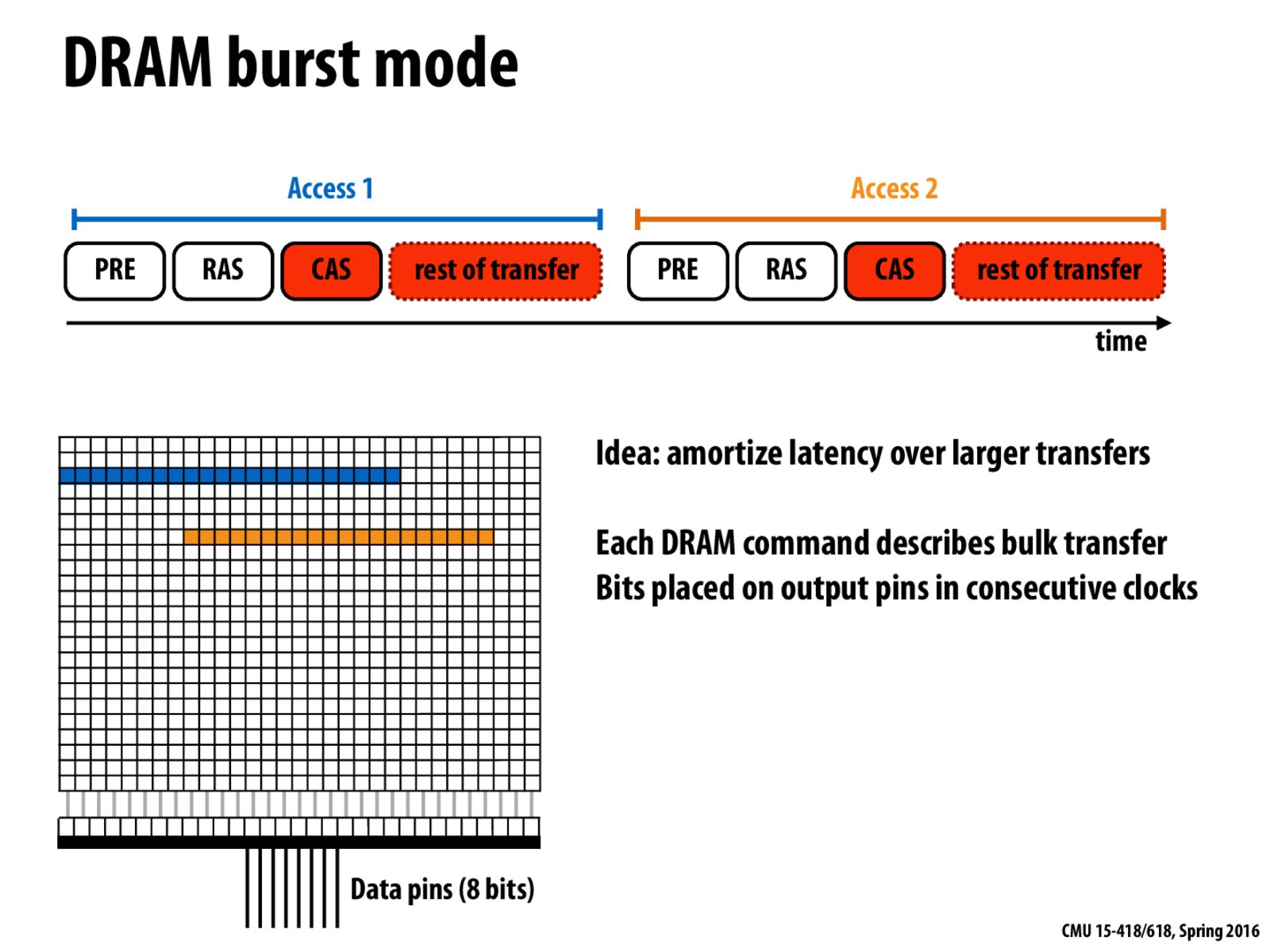
I'm a little confused as to how this reduces latency, for instance isn't the time to get the first bit out increased now because of more column accesses?
makingthingsfast
It was mentioned in class that this method increases throughput and decreases the latency of the entire operation. It does not decrease the latency of the arrival of the first bit though.
pavelkang
What are we doing differently from the last slide? Are we simply accessing a larger chunk of data?
hofstee
@pavelkang You send your data request along with the additional information that tells the memory system you want to read more of the data. So before we would do 16 requests of 8 bytes, now we do one request of 128 bytes in whatever manner the memory system requires. Where before, we would have to do CAS ... receive data, CAS ... receive data, CAS ... receive data, now we can do CAS ... receive data receive data receive data receive data. All the latency of the intermediate CAS signals is gone.
kayvonf
@hofstee. Good answer. But the latency of the "intermediate CAS" signals is not hidden, those operations are simply not there anymore. I'd say they were hidden if the controlled sent a CAS, but that the latency of that operation was overlapped with transfer from other banks, such as the example on the next slide.
hofstee
@kayvonf whoops, forgot for DDR you just send a read command instead of toggling CAS.
mallocanswer
Why can't we overlap the PRE and the rest of transfer? I think two operations will not interfere with each other.
hofstee
@mallocanswer the precharge also takes care of closing the row and putting the row back into the DIMMs where it belongs, so if we precharged before we were done reading the data we would no longer have the data.
mallocanswer
@hofstee, you are right. I missed this part. Thanks for your explanation.
monkeyking
Do I need to take advantage of this feature explicitly or does DRAM do it for me implicitly? I mean, if I want to read byte 0 from row 0, then byte 0 from row 1 then byte 1 from row 0 then byte 1 from row 1, which one of the following two is true?
I need to send request "read byte 0-1 from row 0" first and then request "read byte 0-1 from row 1".
I send request "read byte 0 from row 0, byte 0 from row 1, byte 1 from row 0, byte 1 from row 1". And then DRAM realizes that it can read byte 0-1 from row 0 first and then byte 0-1 from row 1. So it does so.
hofstee
@monkeyking all this stuff is handled by the memory controller. If your memory controller is smart, you don't need to worry about this. If the memory controller reorders commands, case number 2. The DRAM itself just responds to whatever commands you send.
PandaX
DRAM burst mode essentially transfers more data. The question is what if we only need one byte at that row? The following data transferred would just be wasted.
qqkk
@PandaX Yes, it's just that latency is amortized over large transfers. Usually space locality is common and prefetch can help reduce the latency. For some memory access pattern the additional data will just be wasted.
maxdecmeridius
What does the "rest of transfer" block represent? Is it just the additional time it takes to send the rest of the block over the 8 pins?
Lawliet
So if we have an access pattern like the previous slide where we access only one byte per line before switching, this access pattern would take even longer than before.
I'm a little confused as to how this reduces latency, for instance isn't the time to get the first bit out increased now because of more column accesses?
It was mentioned in class that this method increases throughput and decreases the latency of the entire operation. It does not decrease the latency of the arrival of the first bit though.
What are we doing differently from the last slide? Are we simply accessing a larger chunk of data?
@pavelkang You send your data request along with the additional information that tells the memory system you want to read more of the data. So before we would do 16 requests of 8 bytes, now we do one request of 128 bytes in whatever manner the memory system requires. Where before, we would have to do CAS ... receive data, CAS ... receive data, CAS ... receive data, now we can do CAS ... receive data receive data receive data receive data. All the latency of the intermediate CAS signals is gone.
@hofstee. Good answer. But the latency of the "intermediate CAS" signals is not hidden, those operations are simply not there anymore. I'd say they were hidden if the controlled sent a CAS, but that the latency of that operation was overlapped with transfer from other banks, such as the example on the next slide.
@kayvonf whoops, forgot for DDR you just send a read command instead of toggling CAS.
Why can't we overlap the PRE and the rest of transfer? I think two operations will not interfere with each other.
@mallocanswer the precharge also takes care of closing the row and putting the row back into the DIMMs where it belongs, so if we precharged before we were done reading the data we would no longer have the data.
@hofstee, you are right. I missed this part. Thanks for your explanation.
Do I need to take advantage of this feature explicitly or does DRAM do it for me implicitly? I mean, if I want to read byte 0 from row 0, then byte 0 from row 1 then byte 1 from row 0 then byte 1 from row 1, which one of the following two is true?
@monkeyking all this stuff is handled by the memory controller. If your memory controller is smart, you don't need to worry about this. If the memory controller reorders commands, case number 2. The DRAM itself just responds to whatever commands you send.
DRAM burst mode essentially transfers more data. The question is what if we only need one byte at that row? The following data transferred would just be wasted.
@PandaX Yes, it's just that latency is amortized over large transfers. Usually space locality is common and prefetch can help reduce the latency. For some memory access pattern the additional data will just be wasted.
What does the "rest of transfer" block represent? Is it just the additional time it takes to send the rest of the block over the 8 pins?
So if we have an access pattern like the previous slide where we access only one byte per line before switching, this access pattern would take even longer than before.