(1-f)/perf(r) is the time taken for the sequential part of the program (running on the big single core).
f/(perf(r)+n-r) is the time taken for the parallel part of the program.
williamx
This hybrid processor allows us to run completely sequential code as fast as Processor A from the previous slide, and completely parallel code over 75% as fast as Processor B.
BestBunny
How does a program get efficiently mapped to a heterogeneous system? In the above mentioned case, what makes the sequential part of the program run on the big single core? Is this done by the scheduler or does the programmer play a larger role in scheduling by indicating what parts of the program require what features of the system?
Penguin
The programmer does have the ability to tell the processor to run a thread on a specific core but I'm sure kernels written for heterogeneous systems will try to prioritize the more powerful cores when necessary because of the improved performance.
ask
(1 - f)/perf(r) corresponds to the sequential part of the program. The sequential part of most programs forms a considerable chunk of the overall computation to be performed in the program. Hence, it is important to also get the sequential part running faster by potentially using a the large core with a greater perf(r) in order to achieve a better overall performance.
sushi
In this equation, r = 4, corresponds to the resource of the one core. The idea is that for the part that can not be paralleled, the larger core can be used which can gain perf(r)x speedup. For the paralleled part, all cores can be involved in the computation and the overall computation compacity is perf(r) + (n-r). In a more general way, if there are two types each with resource $r_a$, $r_b$ with $r_a > r_b$ and the total resource dedicated to each of the two types are $n_a$, $n_b$. The the speedup of using $n = n_a + n_b$ can be $1 \over {{1-f} \over {perf(r_a)}}+{f \over {{{n_{a}\over r_a} perf(r_a)}}+{n_b \over r_b }perf(r_b)}$
unparalleled
The assumption here is that the entire fraction of sequential part of the program is scheduled on the big fat core, and the parallel part of the program is distributed among all the cores (both fat and thin).
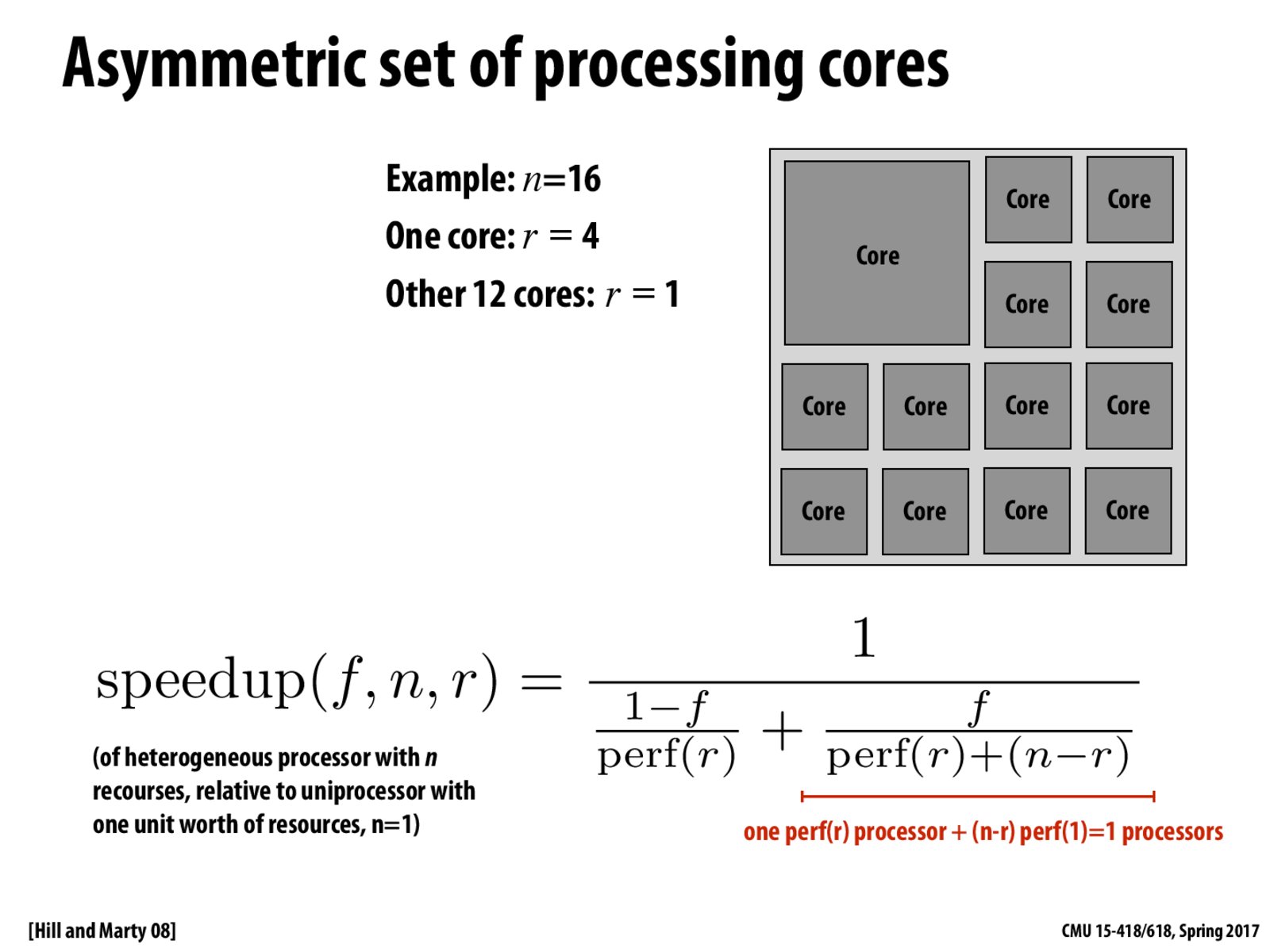
(1-f)/perf(r) is the time taken for the sequential part of the program (running on the big single core).
f/(perf(r)+n-r) is the time taken for the parallel part of the program.
This hybrid processor allows us to run completely sequential code as fast as Processor A from the previous slide, and completely parallel code over 75% as fast as Processor B.
How does a program get efficiently mapped to a heterogeneous system? In the above mentioned case, what makes the sequential part of the program run on the big single core? Is this done by the scheduler or does the programmer play a larger role in scheduling by indicating what parts of the program require what features of the system?
The programmer does have the ability to tell the processor to run a thread on a specific core but I'm sure kernels written for heterogeneous systems will try to prioritize the more powerful cores when necessary because of the improved performance.
(1 - f)/perf(r) corresponds to the sequential part of the program. The sequential part of most programs forms a considerable chunk of the overall computation to be performed in the program. Hence, it is important to also get the sequential part running faster by potentially using a the large core with a greater perf(r) in order to achieve a better overall performance.
In this equation, r = 4, corresponds to the resource of the one core. The idea is that for the part that can not be paralleled, the larger core can be used which can gain perf(r)x speedup. For the paralleled part, all cores can be involved in the computation and the overall computation compacity is perf(r) + (n-r). In a more general way, if there are two types each with resource $r_a$, $r_b$ with $r_a > r_b$ and the total resource dedicated to each of the two types are $n_a$, $n_b$. The the speedup of using $n = n_a + n_b$ can be $1 \over {{1-f} \over {perf(r_a)}}+{f \over {{{n_{a}\over r_a} perf(r_a)}}+{n_b \over r_b }perf(r_b)}$
The assumption here is that the entire fraction of sequential part of the program is scheduled on the big fat core, and the parallel part of the program is distributed among all the cores (both fat and thin).