An interesting point was brought up in class regarding how the above design is a trade-off between energy and latency for the memory request. While interleaving the addresses of a single cache line will enable faster data transfer, you are also spending a lot more energy in precharging 8 row buffers instead of 1 (in the case of no interleaving).
sandeep6189
But won't the net energy spent to transfer the entire cache line from DRAM to BUS be same in both the cases (since the number of iterations will increase in case of no interleaving)?
ggm8
Since we are now interleaving bytes between the DRAM chips, we reduce the latency by a factor of 8. Since we can get 64 bits in parallel in 1 cycle now, we only need 8 cycles to receive all 64 bytes of the cache line.
dasteere
What is the process for reading one 64 byte line if it is not in DRAM? Will any request to disk be put in DRAM or is there some protocol to determine what stays in DRAM?
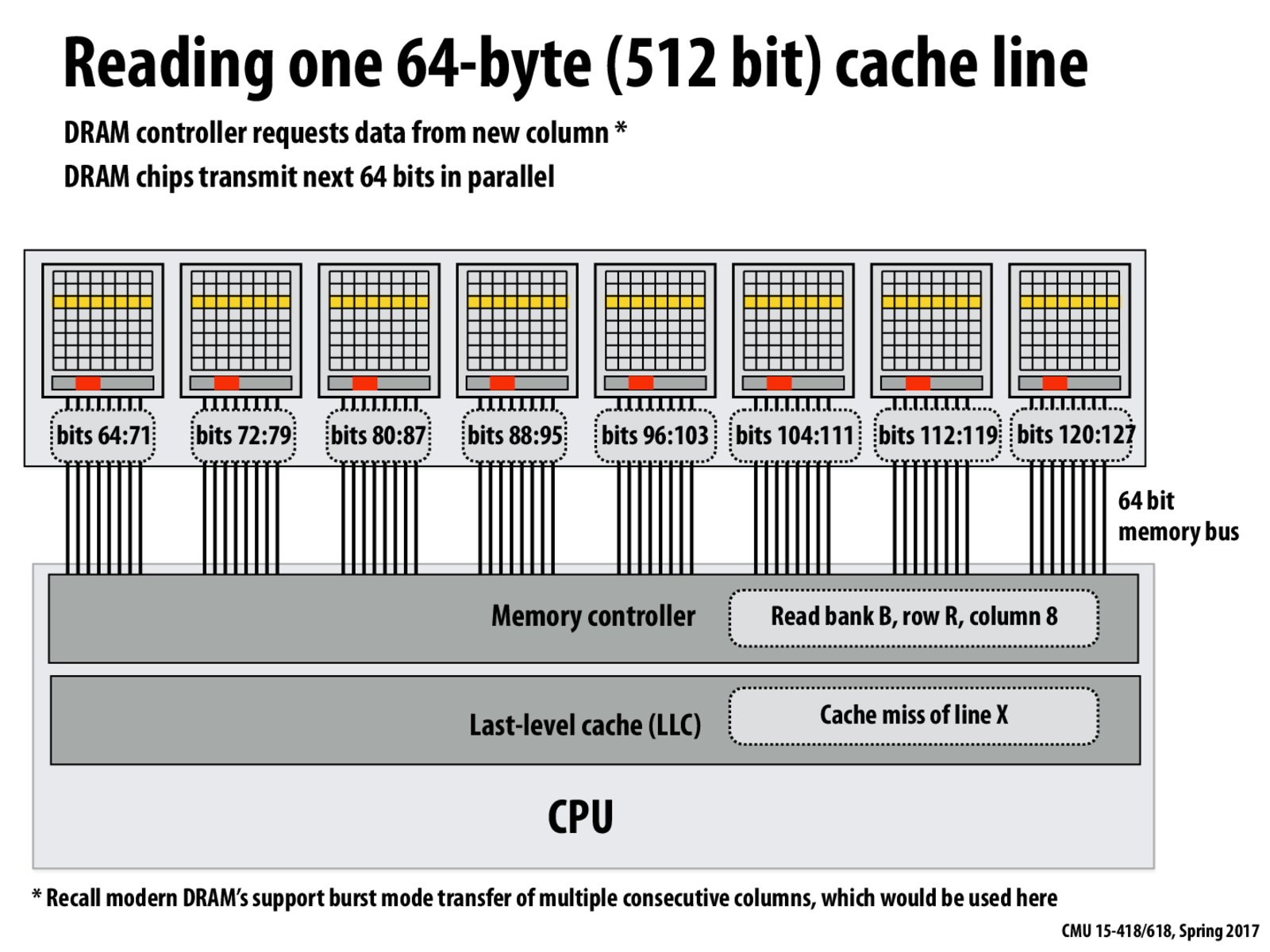
An interesting point was brought up in class regarding how the above design is a trade-off between energy and latency for the memory request. While interleaving the addresses of a single cache line will enable faster data transfer, you are also spending a lot more energy in precharging 8 row buffers instead of 1 (in the case of no interleaving).
But won't the net energy spent to transfer the entire cache line from DRAM to BUS be same in both the cases (since the number of iterations will increase in case of no interleaving)?
Since we are now interleaving bytes between the DRAM chips, we reduce the latency by a factor of 8. Since we can get 64 bits in parallel in 1 cycle now, we only need 8 cycles to receive all 64 bytes of the cache line.
What is the process for reading one 64 byte line if it is not in DRAM? Will any request to disk be put in DRAM or is there some protocol to determine what stays in DRAM?