Is it possible to assign each processor to each of the 4 quadrants? By doing so, it seems like we could reduce the data sent to each processor each iteration to just n (where n is the length of the row).
bochet
@williamx I think you are right, each processor only needs to broadcast the boundary pixels to neighboring processors. Dividing into quadrants reduce the bound pixel to n (one pixel is broadcast twice).
Update:
It's not a mistake, I didn't notice in interleaved assignment, there are multiple P2s. Thanks @Cake.
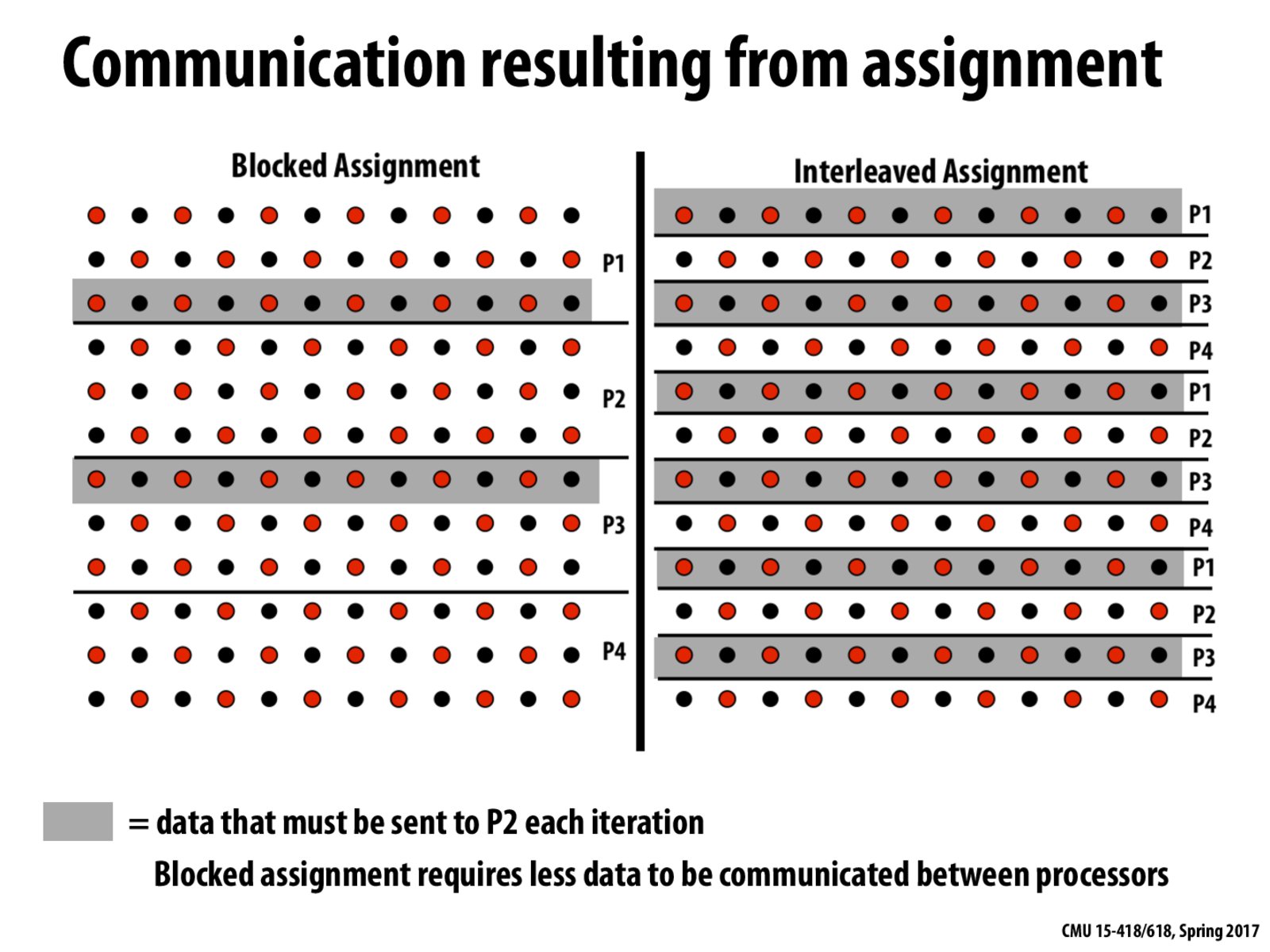
A slide mistake:
dark shadow means "data that must be sent to P2 each iteration",
but in interleaved assignment, only P1 and P3 need to send information to P2
Cake
@bochet Could you clarify this? I don't see the mistake here. All the information P2 needs for computation in each iteration (which isn't already assigned to it) is highlighted in dark in both the blocked and interleaved assignments.
slowloris
So, from a previous lecture, we had the situation where interleaving the tasks assigned to each processor was good because it allowed greater utilization of the cache. However, it seems like this slide is implying that blocked assignment is better in this case because the processors need to share less data this way. Are we to take it as a given that the benefit of sharing less information from the blocked assignment outweighs the benefit of increased cache usage from the interleaved assignment?
paracon
@slowloris Some discussion on why blocked assignment is better in this case is given on the comment thread here.
Cache usage depends a lot on cache parameters like associativity, number of sets, number of lines, placement policy et al. I believe the previous discussion we had about blocked vs interleaved (here) had to do with the efficiency of packed_load over the not-yet-available gather instruction.
holard
Would it be possible to partition the data along diagonal lines? In the above illustration, we can partition the data into 4 triangles (boundaries are diagonals of the square), resulting in assignments where each processor only has one color on its edge. This means that for each communication phase, each processor only needs to either send or receive information, not both. Would this potentially decrease the communication overhead?
efang
@holard Theoretically I see no barrier to partitioning data along diagonal lines, it will be down to the data structure used essentially. However one critical note is that the standard data structure used by these grids, row major 2d arrays, highly disadvantage anything other than row major access, you may reduce communications overhead, but cache miss I think will be a far bigger concern
Is it possible to assign each processor to each of the 4 quadrants? By doing so, it seems like we could reduce the data sent to each processor each iteration to just n (where n is the length of the row).
@williamx I think you are right, each processor only needs to broadcast the boundary pixels to neighboring processors. Dividing into quadrants reduce the bound pixel to n (one pixel is broadcast twice).
Update: It's not a mistake, I didn't notice in interleaved assignment, there are multiple P2s. Thanks @Cake.
A slide mistake: dark shadow means "data that must be sent to P2 each iteration", but in interleaved assignment, only P1 and P3 need to send information to P2
@bochet Could you clarify this? I don't see the mistake here. All the information P2 needs for computation in each iteration (which isn't already assigned to it) is highlighted in dark in both the blocked and interleaved assignments.
So, from a previous lecture, we had the situation where interleaving the tasks assigned to each processor was good because it allowed greater utilization of the cache. However, it seems like this slide is implying that blocked assignment is better in this case because the processors need to share less data this way. Are we to take it as a given that the benefit of sharing less information from the blocked assignment outweighs the benefit of increased cache usage from the interleaved assignment?
@slowloris Some discussion on why blocked assignment is better in this case is given on the comment thread here.
Cache usage depends a lot on cache parameters like associativity, number of sets, number of lines, placement policy et al. I believe the previous discussion we had about blocked vs interleaved (here) had to do with the efficiency of packed_load over the not-yet-available gather instruction.
Would it be possible to partition the data along diagonal lines? In the above illustration, we can partition the data into 4 triangles (boundaries are diagonals of the square), resulting in assignments where each processor only has one color on its edge. This means that for each communication phase, each processor only needs to either send or receive information, not both. Would this potentially decrease the communication overhead?
@holard Theoretically I see no barrier to partitioning data along diagonal lines, it will be down to the data structure used essentially. However one critical note is that the standard data structure used by these grids, row major 2d arrays, highly disadvantage anything other than row major access, you may reduce communications overhead, but cache miss I think will be a far bigger concern