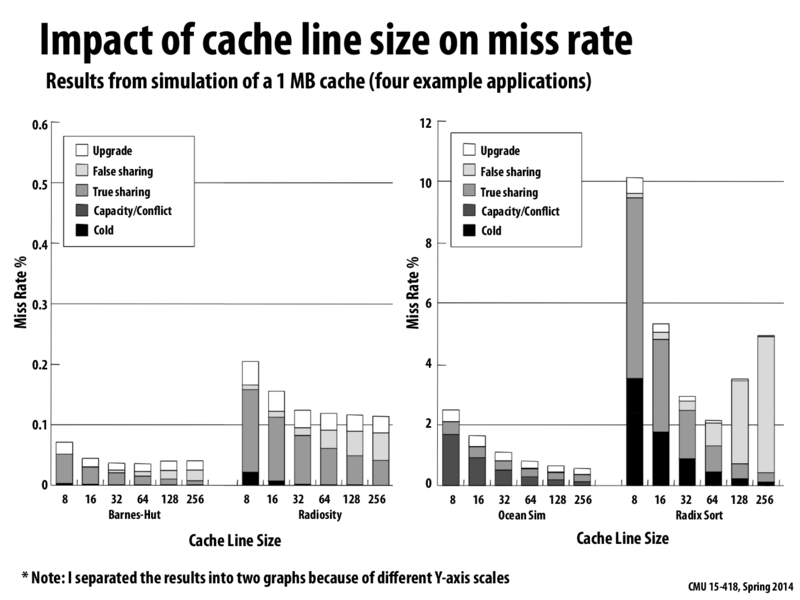
I think the assumption here is that only the cache line size increases, so the total size of cache remains the same. In this case, either the associativity decrease or the number of sets decrease.
The reason that the miss rate decreases is that since each cache line size increases, for the same amount of data (suppose good locality), each miss would bring more useful data than smaller cache line size. It is also the reason that the true sharing decreases, since there is less coherence traffic.
This comment was marked helpful 0 times.
aew
This might be irrelevant, but what are the "Upgrade" misses (and why do they decrease more on Radix Sort)? Thanks!
This comment was marked helpful 0 times.
kayvonf
@aew: upgrade miss is when a line in the S state is "upgraded" to the M state when the processor wants to write to it. This involves an announcement of the intent to write, but doesn't require data to be fetched from memory since the data in the S state in the cache is valid. This is a small optimization on the basic MSI protocol as we discussed in class. However, notice that my diagram technically says movement from S to M triggers a BusRdX just like movement from I to M. In that lecture, BusRdX meant send the request for exclusive access on the interconnect and read the data from memory. Really all that's necessary is to make sure the exclusive access request is broadcast -- that's the bus upgrade. In fact, it's such an obvious thing to do it was clear from a couple of questions in class that students were assuming this was the case in the MSI protocol, although technically it does not include this optimization.
This comment was marked helpful 1 times.
RICEric22
The reason why we see a larger bar for larger cache line sizes in Radix sort is because the majority of the misses are false sharing misses. Since the cache lines are so large, it even more likely for multiple threads to be accessing the same cache line.
This comment was marked helpful 0 times.
jmnash
There are a few things I notice about these graphs:
In all cases, increasing line size decreases cold misses, because each miss brings in a larger amount of data
It also decreases true sharing misses for the same reason, because there are fewer cache lines to bounce back and forth when two processors share the same data
It also seems to decrease conflict and capacity misses (although Ocean Sim is the only application that has any), probably because the application will repeatedly use different parts of the larger cache line, rather than continuously dropping and picking up smaller parts of it because a different part was being used
However, increased cache line size increases false sharing misses, because with a larger line size there is a higher probability that more than one processor will want the data on that cache line
Because of the last point, there is a certain line size that is ideal for most of the applications, and if you go above that false sharing misses increase too much. However, for Ocean Sim, since it has no false sharing misses that is not the case and larger cache lines always result in fewer overall misses.
I think the assumption here is that only the cache line size increases, so the total size of cache remains the same. In this case, either the associativity decrease or the number of sets decrease.
The reason that the miss rate decreases is that since each cache line size increases, for the same amount of data (suppose good locality), each miss would bring more useful data than smaller cache line size. It is also the reason that the true sharing decreases, since there is less coherence traffic.
This comment was marked helpful 0 times.
This might be irrelevant, but what are the "Upgrade" misses (and why do they decrease more on Radix Sort)? Thanks!
This comment was marked helpful 0 times.
@aew: upgrade miss is when a line in the S state is "upgraded" to the M state when the processor wants to write to it. This involves an announcement of the intent to write, but doesn't require data to be fetched from memory since the data in the S state in the cache is valid. This is a small optimization on the basic MSI protocol as we discussed in class. However, notice that my diagram technically says movement from S to M triggers a BusRdX just like movement from I to M. In that lecture, BusRdX meant send the request for exclusive access on the interconnect and read the data from memory. Really all that's necessary is to make sure the exclusive access request is broadcast -- that's the bus upgrade. In fact, it's such an obvious thing to do it was clear from a couple of questions in class that students were assuming this was the case in the MSI protocol, although technically it does not include this optimization.
This comment was marked helpful 1 times.
The reason why we see a larger bar for larger cache line sizes in Radix sort is because the majority of the misses are false sharing misses. Since the cache lines are so large, it even more likely for multiple threads to be accessing the same cache line.
This comment was marked helpful 0 times.
There are a few things I notice about these graphs:
Because of the last point, there is a certain line size that is ideal for most of the applications, and if you go above that false sharing misses increase too much. However, for Ocean Sim, since it has no false sharing misses that is not the case and larger cache lines always result in fewer overall misses.
This comment was marked helpful 0 times.