Question: I am very confused on the implementation of Radix sort from this slide.
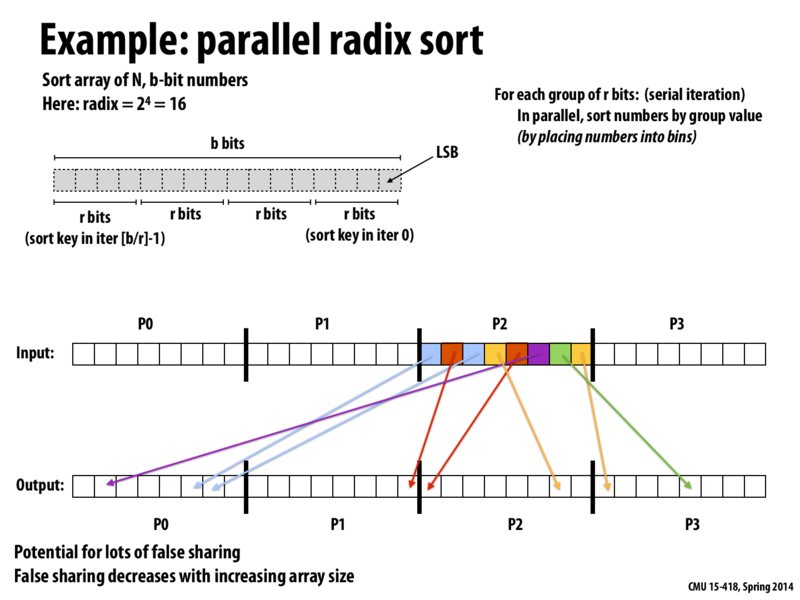
Here is my understanding that is possibly wrong: each square represents a number and their color represent the bin it belongs to. Take the first blue square in P2 for example. My question is that how does P2 know to put it at index 5 instead of 4 or some other places in the bin? Does the processors coordinate to agree on which chunk of the bin each processor can write to?
Thanks :D
This comment was marked helpful 0 times.
spilledmilk
This confused me for a really long time too, but I think I finally understand it now.
I believe that everything you've written out is correct. As for how the processors know where to put the numbers in the final bin, from what I understand, that process would be similar to how we implemented find_repeats. The entire process would go as follows:
In parallel, make a thread for each element and find the bin each element should go into. This could very easily be done as a bitmask (0xF in this case).
In parallel, make a thread for each bin and map each element to 1 if it is in the bin, 0 if it is not. Then, run prefix-sum exclusive scan over these lists of 1's and 0's.
Given the bin number $b$ and the index $i$ of an element in the overall array, take the scan result for the $b$-th bin and index $i$ of that result will tell you where in that bin to put the element.
This comment was marked helpful 0 times.
kayvonf
Yes, @spilledmilk is correct. To clarify and summarize:
Step 1. Each processor bins the elements it is responsible for. Each processor now has counts for each bin.
Step 2. Aggregate all those counts to get per-processor offsets into each bin.
Step 3. "Scatter" the elements to the correct offsets. Each processor will write a contiguous chunk of offsets into each bin, as illustrated by the arrows on the slide.
If someone wanted to try their hand and some basic pseudocode, that might help others. For low processor counts, it would be quite reasonable to perform the offset calculations serially on one node, and not implement a data-parallel scheme.
This comment was marked helpful 0 times.
kayvonf
I'd like to clarify why false sharing occurs in this example. The figure illustrates how, in each round of the radix sort, each processor will compute the bin in the output array that its input array elements should be moved to (elements assigned to P2 are colored according to their bin). Given the mapping of elements to bins, the algorithm then computes the precise output location each element should be moved to. Each processor then scatters its elements to the appropriate location in the output array (as shown by the arrows in the figure).
By the nature of a stable radix sort, each process P writes its elements that belong to the same bin to a contiguous region of the output array. In this example, P2 never writes more than two consecutive elements to the output, since it is not assigned more than two elements mapping to the same bin. Noe remember that P0, P1, and P3 are also scattering their elements into the output. The result is an access pattern where each processor is scattering data all over memory.
Now recall that to perform a write, a processor must first obtain exclusive access to the cache line containing the address. In the case of radix sort above, many processors might end up writing to the same cache line (since it's likely all processors have elements falling in each bin). This will cause the cache line to bounce all around the machine. There is no inherent communication between the processors in the scatter step of the algorithm, so the extra cache invalidations during the scatter are due to false sharing.
Notice that if the array to sort is very large, each processor is responsible for more data, and it is more likely that each processor will write larger ranges of contiguous elements to the output array. This decreases false sharing by dropping the likelihood multiple processors write to the same line. Conversely, if the number of processors is large, the number of elements per processor decreases, leading again to few contiguous writes per processor, and thus more false sharing.
Question: I am very confused on the implementation of Radix sort from this slide.
Here is my understanding that is possibly wrong: each square represents a number and their color represent the bin it belongs to. Take the first blue square in P2 for example. My question is that how does P2 know to put it at index 5 instead of 4 or some other places in the bin? Does the processors coordinate to agree on which chunk of the bin each processor can write to?
Thanks :D
This comment was marked helpful 0 times.
This confused me for a really long time too, but I think I finally understand it now.
I believe that everything you've written out is correct. As for how the processors know where to put the numbers in the final bin, from what I understand, that process would be similar to how we implemented
find_repeats. The entire process would go as follows:0xFin this case).This comment was marked helpful 0 times.
Yes, @spilledmilk is correct. To clarify and summarize:
Step 1. Each processor bins the elements it is responsible for. Each processor now has counts for each bin.
Step 2. Aggregate all those counts to get per-processor offsets into each bin.
Step 3. "Scatter" the elements to the correct offsets. Each processor will write a contiguous chunk of offsets into each bin, as illustrated by the arrows on the slide.
If someone wanted to try their hand and some basic pseudocode, that might help others. For low processor counts, it would be quite reasonable to perform the offset calculations serially on one node, and not implement a data-parallel scheme.
This comment was marked helpful 0 times.
I'd like to clarify why false sharing occurs in this example. The figure illustrates how, in each round of the radix sort, each processor will compute the bin in the output array that its input array elements should be moved to (elements assigned to P2 are colored according to their bin). Given the mapping of elements to bins, the algorithm then computes the precise output location each element should be moved to. Each processor then scatters its elements to the appropriate location in the output array (as shown by the arrows in the figure).
By the nature of a stable radix sort, each process P writes its elements that belong to the same bin to a contiguous region of the output array. In this example, P2 never writes more than two consecutive elements to the output, since it is not assigned more than two elements mapping to the same bin. Noe remember that P0, P1, and P3 are also scattering their elements into the output. The result is an access pattern where each processor is scattering data all over memory.
Now recall that to perform a write, a processor must first obtain exclusive access to the cache line containing the address. In the case of radix sort above, many processors might end up writing to the same cache line (since it's likely all processors have elements falling in each bin). This will cause the cache line to bounce all around the machine. There is no inherent communication between the processors in the scatter step of the algorithm, so the extra cache invalidations during the scatter are due to false sharing.
Notice that if the array to sort is very large, each processor is responsible for more data, and it is more likely that each processor will write larger ranges of contiguous elements to the output array. This decreases false sharing by dropping the likelihood multiple processors write to the same line. Conversely, if the number of processors is large, the number of elements per processor decreases, leading again to few contiguous writes per processor, and thus more false sharing.
This comment was marked helpful 0 times.