I was a little confused about Kayvon's question "How would you actually make the lists from this information?"
Can somebody please summarize what was happening on this slide? Particularly transitioning from Step 2 to 3, and Step 3.
This comment was marked helpful 0 times.
tomshen
The transition from step 2 to step 3 takes place when the code block is run for each element of result (in parallel). This generates the two arrays that you see at the bottom. Then, we can generate a list for each of the cells using the cell_starts and cell_ends arrays. For the ith cell, our list is the elements of the result array from index cell_starts[i] (including this element) to cell_ends[i] (excluding this element). The reason we can just take contiguous portions of our result array as lists is because it's sorted by cell.
This comment was marked helpful 0 times.
yanzhan2
We also need to keep the Particle Index array, right? For example we have for the 4th cell, cell_starts[4] and cell_ends[4] only includes the index 0 and 2, but the actual circle is 3 and 5, which is particle index[0] and particle index[1].
This comment was marked helpful 0 times.
kayvonf
@yanzhan2: correct, particle index array must be kept around. cell_starts and cell_ends refer to elements of particle index. For example, if we wanted to iterate over all particles in cell X:
for (int i=cell_starts[X]; i<cell_ends[X]; i++) {
int index = particle_index[i];
// do stuff ...
}
This comment was marked helpful 0 times.
squidrice
In the step 2, there is a thread at every cell of sorted results. Every thread is responsible for checking whether there is a difference between the previous element and the current one. If there is one, it indicates the end of the previous list and the beginning of the current list. For example, for thread at result[2], it detects the end of 4s and the start of 6s. The special cases here are the first and last cell. Those positions are then written into cell_starts and cell_ends.
This comment was marked helpful 0 times.
Yuyang
LOL this was super helpful for the renderer lab :D
This comment was marked helpful 0 times.
black
@Yuyang, Yeah, I just watch this lecture today too! But I think we should modify it to make this work for Assignment 2. This method requires us to allocate a array with the length of number of particles. However, in A#2, we don't know the number of circles in advance. And we can't put such a huge array in shared memory to accelerate speed...We have to separate circles into groups.
This comment was marked helpful 0 times.
jon
I'm curious if anyone was able to directly apply this method to Assignment 2 (are we allowed to discuss homework solutions here?)
It seems that the main difference between the application in this slide and the circle renderer is that circles can lie in multiple cells. While I see how related data-parallel methods can be applied to circle render (what my partner and I did), it's unclear to me how these precise steps can be followed.
This comment was marked helpful 0 times.
spjames
@jon I did it this way for Assignment 2. If you just assume the worst case, that all circles cover all cells, then you can allocate memory accordingly. The cell size then needs to be chosen to not run out of memory in that worst case. I looped over all of the cells covered by a circle and added them to a global list like in this example.
The thing that surprised me a bit was that while this step might seem like it would be slow because of global memory accesses, atomics, and each circle causing different branching paths, in fact it was quite fast compared to the sorting step. The sort was by far the slowest part of my renderer, even though I was using Thrust's very fast parallel radix sort.
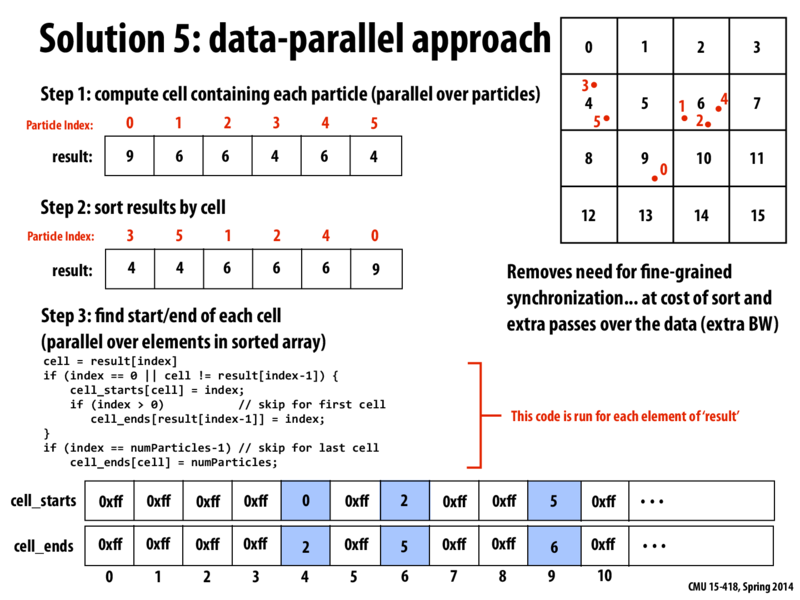
I was a little confused about Kayvon's question "How would you actually make the lists from this information?" Can somebody please summarize what was happening on this slide? Particularly transitioning from Step 2 to 3, and Step 3.
This comment was marked helpful 0 times.
The transition from step 2 to step 3 takes place when the code block is run for each element of result (in parallel). This generates the two arrays that you see at the bottom. Then, we can generate a list for each of the cells using the
cell_startsandcell_endsarrays. For theith cell, our list is the elements of theresultarray from indexcell_starts[i](including this element) tocell_ends[i](excluding this element). The reason we can just take contiguous portions of ourresultarray as lists is because it's sorted by cell.This comment was marked helpful 0 times.
We also need to keep the Particle Index array, right? For example we have for the 4th cell, cell_starts[4] and cell_ends[4] only includes the index 0 and 2, but the actual circle is 3 and 5, which is particle index[0] and particle index[1].
This comment was marked helpful 0 times.
@yanzhan2: correct, particle index array must be kept around.
cell_startsandcell_endsrefer to elements of particle index. For example, if we wanted to iterate over all particles in cell X:This comment was marked helpful 0 times.
In the step 2, there is a thread at every cell of sorted results. Every thread is responsible for checking whether there is a difference between the previous element and the current one. If there is one, it indicates the end of the previous list and the beginning of the current list. For example, for thread at
result[2], it detects the end of 4s and the start of 6s. The special cases here are the first and last cell. Those positions are then written intocell_startsandcell_ends.This comment was marked helpful 0 times.
LOL this was super helpful for the renderer lab :D
This comment was marked helpful 0 times.
@Yuyang, Yeah, I just watch this lecture today too! But I think we should modify it to make this work for Assignment 2. This method requires us to allocate a array with the length of number of particles. However, in A#2, we don't know the number of circles in advance. And we can't put such a huge array in shared memory to accelerate speed...We have to separate circles into groups.
This comment was marked helpful 0 times.
I'm curious if anyone was able to directly apply this method to Assignment 2 (are we allowed to discuss homework solutions here?)
It seems that the main difference between the application in this slide and the circle renderer is that circles can lie in multiple cells. While I see how related data-parallel methods can be applied to circle render (what my partner and I did), it's unclear to me how these precise steps can be followed.
This comment was marked helpful 0 times.
@jon I did it this way for Assignment 2. If you just assume the worst case, that all circles cover all cells, then you can allocate memory accordingly. The cell size then needs to be chosen to not run out of memory in that worst case. I looped over all of the cells covered by a circle and added them to a global list like in this example.
The thing that surprised me a bit was that while this step might seem like it would be slow because of global memory accesses, atomics, and each circle causing different branching paths, in fact it was quite fast compared to the sorting step. The sort was by far the slowest part of my renderer, even though I was using Thrust's very fast parallel radix sort.
This comment was marked helpful 0 times.