










The write buffer (post retirement store/write buffer) is a common design in modern processors. The idea is that store (write) operation does not need to perform immediately, so we can put them into some buffers to reduce memory traffic while check the buffer for later load instructions to guarantee correctness.
But the write buffer could cause these memory instructions to be seen by others processors out-of-order, which relates to the memory consistency. For example, for TSO, a FIFO write buffer could be used for each processor for performance. While for PSO, a non-FIFO coalescing write buffer could be used as the store instructions are not ordered.
This comment was marked helpful 0 times.

So if we were to access X, do we need to check the buffer for any writes to X that are waiting? What are the performance implications of this?
This comment was marked helpful 0 times.

@uhkiv: Absolutely. A subsequent read of X needs to check both the cache and the write buffer to determine where the most recent copy of the value is. These checks would almost certainly be carried out in parallel.
This comment was marked helpful 0 times.



Program one:
Since we are NOT violating W --> W, the flag must be set to "one" before we can get out of the while loop and print A. Thus, A is always one, in SC, TSO, and PC.
Program two:
According to SC, we could print the following values for A, B -- (0, 0), (1, 1), and (0, 1). It is impossible to print (1, 0), since we are writing to B after we write to A. If "B" is printed as "1", then "A" MUST be set to "1" as well. Any other ordering would violate W --> W.
Program three:
According to SC, thread 1 triggers thread 2, which triggers thread 3, causing A to be printed as "1".
In TSO, we match SC. This is because thread 1's write to A must be passed to ALL OTHER PROCESSORS. No one can see A as anything other than "one".
In PC, we don't necessarily match SC. This is because the processor running thread 2 can see the write from thread one, but the processor running thread 3 can avoid seeing the write to A. Long story short -- A = 1 propagates to T2, not T3. T2's write to B propagates to T3. T3 still thinks A is zero.
Program four:
According to SC - We can see all combinations of A, B OTHER than (0, 0). Logically, ONE of A or B must be set to one before anything can be printed.
According to TSO or PC, either of the reads (prints) could be moved up. From the perspective of T1, it thinks "Oh, I can print B. I'm writing to A, but that's not B, we can relax the R --> W ordering". The same logic applies to T2, with A/B switched. This could result in (0, 0) being printed, which doesn't match S.C.
This comment was marked helpful 5 times.

@smklein - nice explanation.
In the 4th program, it was mentioned in class and also in @smklein's comment that the SC version can produce all outputs except (0, 0). It's clear to me how (1, 1) and (0, 1) can be produced, but I don't see any way to interleave the statements to get the (1, 0) output. What am I missing?
This comment was marked helpful 0 times.
@dfarrow
To get the A = 1, B = 0 output:
START (A = 0, B = 0 at start)
T1:
A = 1
Print B
(Result : B = 0)
T2: B = 1
Print A
(Result : A = 1)
END
This comment was marked helpful 1 times.
Ah, I misunderstood the notation. I thought a (1, 0) output meant that a 1 was printed first and then a 0 was printed second. But now I see it means that A is "1" and B is 0. Thanks for clearing that up.
This comment was marked helpful 0 times.

I feel like I may have forgotten stuff since lecture. My question is if TSO and PC both are not the same as our basic perception of memory consistency, then why do we use them? I guess latency hiding is the answer, but is it the sole reason? Also, to what extent are TSO or PC used in the real world as generally, I assume, people do not think about memory like this at all?
This comment was marked helpful 0 times.

The goal is definitely latency hiding. The two cases in which the TSO and PC diverge from intuitive explanation are situations where they're attempting to replicate something that should be done using primitives to ensure Sequential Consistency.
See slide 14 for an example of primitives that might be employed.
This comment was marked helpful 0 times.

TSO is a more stringent ordering than PC, so it seems like when a program fails to match SC under the TSO ordering, it will fail to match SC under the PC ordering as well. Is this correct?
This comment was marked helpful 0 times.

I believe that's correct. Or, more specifically, if a program fails to match SC under the TSO ordering, it is possible that it will fail to match SC under the PC ordering.
This comment was marked helpful 0 times.



One thing I was curious about on this slide was what was the difference between the FENCE instruction used here, and the barriers we usually use to make sure that all threads are done executing before we use what they were supposed to be computing. I looked it up, and it seems as if a memory fence is something the programmer never has to explicitly call, it is a concept only in the hardware. In fact, in one post I read on stackoverflow, it said that memory fences are what the hardware uses to implement things like mutexes, locks, and semaphores. I thought this was interesting and it makes sense because those things can all be expressed by blocking access to memory at certain times.
This comment was marked helpful 0 times.

@jmnash: Memory fences (on x86 at least) are implemented by the CPU but are called by software (with assembly instructions like MFENCE or SFENCE). You probably only ever need to deal with calling those instructions directly if you're, say, implementing mutexes, but they are something that is explicitly called by programmers.
This comment was marked helpful 0 times.

Are there any modern processors that use weak ordering? From what I could find when looking it up, they seem to be a thing for only old 1990s computers.
This comment was marked helpful 0 times.
@jmnash: A fence instruction simply says do not move memory accesses around this instruction. It is assigning constraints to the order in which memory instructions in one instruction stream can be executed as well as how they appear to execute to all other processors.
A barrier is a mechanism to synchronize many threads of control. No thread can move beyond the barrier until the specified number of threads have reached it.
This comment was marked helpful 0 times.


Question: How do the Android and iPhone operating systems deal with the relaxed consistency model? When developing for these devices, it seems as if the consistency model is no different than when developing for x86/64.
This comment was marked helpful 0 times.
You probably used synchronization primitives (OS provided messaging channels, locks, semaphores, etc.) to share data between threads, not just loads and stores to shared variables. The implementation of these mechanisms uses the appropriate fence or other synchronization mechanisms to make sure your program remained properly synchronized.
This comment was marked helpful 1 times.

On this slide SC stands for sequential consistency.
This comment was marked helpful 0 times.


Interesting aside, there's no read buffer as all reads produces a value to be used by the processor right away.
This comment was marked helpful 0 times.

What are the MP3D, LU, and PTHOR referenced here?
This comment was marked helpful 0 times.

@retterermoore different programs used as benchmarks. [src]
This comment was marked helpful 0 times.



Sequential consistency (and even some weaker forms of consistency) are far too expensive at web scales, since waiting for a write to propagate to hundreds or thousands of machines before allowing any reads is far too slow. Thus, we exchange perfect consistency for faster writes and reads, which is a reasonable tradeoff in large-scale distributed systems.
This comment was marked helpful 1 times.

Regarding the previous comment, what happens if perfect consistency is required by some of the machines in the large scale system? Is it possible to perhaps guarantee an order in which the changes are propogated such that priority machines that must have the most up-to-date info receive that information first?
This comment was marked helpful 0 times.

As mentioned in class perfect consistency would involve ignoring all requests until a write propagated throughout all of facebook's database mirrors. This could take a long time as their mirrors are in different locations around the globe. This is why an eventually consistent model is used. The eventual consistency will actually be pretty quick (however it is just not sequentially consistent, or even TSO or PC). As a user using facebook it is not really noticeable. If using a chat client, it would ensure quick delivery to select nodes (that other chatters are connected to) by prioritizing updates to those nodes.
This comment was marked helpful 0 times.

Sometimes, I feel like eventual consistency is too slow - for example, I can sometimes see some posts to some facebook groups before someone sitting next to me does. It's kind of interesting that two people sitting next to each other don't use the same Facebook DB mirror.
Another problem that eventual consistency brings about is how to merge different databases together, as multiple databases try to create one consistent view - for example, when Google Hangouts rolled out, it was often that people observed a bug where their phone's view of the conversation was different from on a web browser. Even now, enabling a data connection on my phone causes each individual hangouts message to get pushed, at about 1 message a second. This is extremely painful if I've had a lot of messages since my phone last connected to the internet.
This comment was marked helpful 0 times.





I forgot what does "Diminishing returns when trying to further exploit ILP" mean. Does it indicates that ILP diminishes benefits of parallelism when a single core with higher and higher clock frequency? If so I cannot remember why this is happening?
This comment was marked helpful 0 times.
It really just means that there is only so much parallelism you can get from pipelining chunks of instructions on a single core. Splitting only single independent instructions provides an extremely small playing field for parallelism, especially in comparison to multi-core potential. With multiple cores, your CPU doesn't need to be smart enough to strip apart independent instructions and data dependencies from a single instruction stream.
This comment was marked helpful 1 times.

As @smklein mentions, there is only so much ILP you can find. I think the diminishing returns refers to the fact that trying to find more instructions that could benefit from ILP actually takes more time than what is saved performing the instructions in parallel.
This leads me to another question I've been wondering: it seems like we could benefit from having compilers do more in terms of finding ILP, somehow marking those instructions so the hardware can easily find them without having to do the extra work. Is there any reason this isn't the case?
This comment was marked helpful 0 times.

Is ILP implemented by utilizing the multiple ALUs on a core? Would we lose ILP if we try to use SIMD?
This comment was marked helpful 0 times.

@benchoi Well, it uses multiple functional units at the same time, which may or may not be ALUs. They could also be FPUs, or any other part of the CPU. As for whether or not that conflicts with SIMD or not, I haven't thought about that. But if you're getting the full parallelism/ computing power out of your processor, it shouldn't matter what you use to get it.
This comment was marked helpful 0 times.

@benchoi you might find this lecture 2, slide 11 helpful. There are more decoders, and many other hardware units that make ILP happen.
This comment was marked helpful 0 times.


In superscalar execution, there is not necessarily any explicit parallelism written into the instruction stream by the programmer. Instead, the hardware looks at the instructions and finds those that are independent to be executed at the same time on the processor. Processors that support this allow a higher throughput of instructions that therefore reduces the overall average latency of completing the instructions without necessarily requiring the programmer to do extra work (see next slide).
This comment was marked helpful 0 times.
Clarification. There is instruction-level parallelism in the instruction stream. However, there is not an explicit declaration of independent operations in the program. The program does not declare "these operations are independent". The program simply defines a sequence of instructions and the hardware implementation discovered which are independent.
This comment was marked helpful 0 times.


Multi-threading as described on the previous slide were hardware threads. On this slide multi-threading is made out to be like pthreads or some similar construct ala multi-core execution. To the programmer it looks the same, ie. they're all threads interleaved amongst one another, but the difference is in multi-threaded execution the CPU interleaves threads within a core.
This comment was marked helpful 0 times.



A summary of an execution cycle:
Each of the Warp Selectors (light orange) selects a single warp from the set of available warps in the SMX core. Once a warp is selected, up to two independent instructions are selected from it by the fetch/decode units (dark orange) for execution. These 8 selected instructions are then mapped to the 8 blocks of execution units (yellow/red/blue). In an ideal world the 8 instructions selected would be composed of 6 typical ALU operations (yellow blocks), 1 special ALU operation (red blocks), and 1 memory load/store (blue blocks). In reality this may not be the case and thus only a subset of these instructions may be executed resulting in lower than ideal occupancy.
This comment was marked helpful 0 times.




By Amdahl's Law in previous slide, we can say that it is hard or almost impossible to achieve 5x speedup with given resources. However, the inherently serial operations could run faster due to lot's of cache locality, ILP and etc and we might be able to achieve the desired speed-up.
This comment was marked helpful 0 times.

I agree, by the previous slide, because $s = 0.25$ and $p = 6$, the maximum speedup by Amdahl's law is $\leq \frac{1}{.25 + \frac{.75}{6}} \approx 2.667$. However, as @taegyunk mentioned, it may be possible to achieve the 5x speedup through other methods.
This comment was marked helpful 0 times.


I was just talking to cluster services earlier (doing a project about computing clusters) and they brought up how if a person ssh's into Linux or unix, instead of specifying an actual number, they have a program set up that automatically directs them to the one machine that balances out workload across all machines the best. Just an interesting note to share
This comment was marked helpful 0 times.
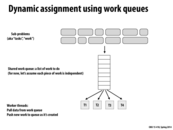

This method of work distribution is the most ideal when there is an unpredictable varied data set or if the data set is imbalanced in regards to the amount of work that needs to be done on each element. Essentially, on a P processor system, the task master assign P random tasks to the P processors. When a processor signals the task master that it has completed its task, the task master sends the processor a new piece of work that needs to be completed.
The main advantages of this scheme over static assignment is that dynamic assignment can overcome some of the negative effects of workload imbalance. The disadvantages of this scheme include increased complexity of the execution of a program, as well as an inability to improve performance if tasks are not divided up into appropriately small units. (Take the initial performance of Mandelbrot when divided into blocks instead of rows).
This work distribution scheme is the scheme used by ISPC to distribute tasks to processors.
This comment was marked helpful 0 times.


Artifactual Communication comes from the fact that whatever abstraction presented to the program, the actual details of implementation might be different.
This comment was marked helpful 1 times.



I have learnt 'write-after-read' (WAR) dependency when I was undergraduate, which describes a situation that a write instruction must be executed after a read operation, for example they are dealing with the same variable. However, in this lecture, this dependency can be relaxed by TSO or PC, it's because we suppose that we are dealing with different variable.
This comment was marked helpful 0 times.