




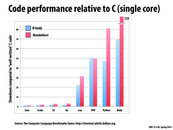

I'm not super familiar with the implementation of Java, but I was under the impression that all compiled bytecode is processed on a virtual machine, which verifies the code before execution. Wouldn't this add at least a moderate amount of slowdown? How is Java so fast on these computations?
This comment was marked helpful 0 times.

This wikipedia article explains optimizations performed in Java in detail and comparison to other languages.
This comment was marked helpful 0 times.

Going back to the discussion we had in lecture about JavaScript and how it compares in this graph, this benchmarking website indicates that JavaScript V8 is only 2-4x slower than C for most of the tests run (and 11x slower on one of the tests). This result puts JavaScript in the same range as Java!
This comment was marked helpful 0 times.

@smkelin JVM uses a lot of optimizations including JIT (Just In Time compilation) which allows the VM to dynamically detect parts of the code that is run frequently, and heavily optimize that part (i.e. produce machine code and optimize that and run on machine). I actually do not know much about this myself, but if interested, http://www.javaworld.com/article/2078623/core-java/jvm-performance-optimization--part-1--a-jvm-technology-primer.html looks like a good primer to high level overview of internals of JVM.
This comment was marked helpful 0 times.
Oh, and http://en.wikipedia.org/wiki/HotSpot looks like the "detection of code that's run frequently" I mentioned.
This comment was marked helpful 0 times.

I'm confused about the (small) differences in performance between Java and Scala. Since Scala is built on the JVM (intended to compile into Java bytecode), shouldn't it exhibit identical performance to Java? The only reason I can think of for this difference is the style of programming (i.e. the functional style of Scala somehow leads to slower code execution), but this doesn't sound too reasonable.
This comment was marked helpful 0 times.

@yrkumar The graph seems to show very small differences. These can probably be explained by the different programming model (functional vs imperative). In a functional model data may need to be copied more frequently instead of being passed by reference. There may be more book keeping if copying is diff based (a constant time copy).
This comment was marked helpful 0 times.

@yrkumar I think important aspect to consider is the compiler. On the one hand, the compiler may apply more optimization as scala is functional and therefore side-effect free. On the other hand, this may add more (possibly unnecessary) constraints and generated less efficient code.
This comment was marked helpful 0 times.










One important aspect of modern programming languages that this graph doesn't hit on is safety. Programmers are, of course, not perfect and hence we write imperfect code. Safety in a language--either through typing, static analysis, or other methods--makes it significantly more viable for use on a production scale. In particular, we want languages that ensure safety while performing concurrent actions. As this class shows, parallelism will only become more important as the future progresses. Race conditions, the most insidious of bugs, can be completely eliminated with the right choice of languages--e.g. Rust.
This comment was marked helpful 0 times.

@wcrichto I think perhaps that safety falls in to productivity. If you do not have to worry about safety with race conditions for instance, then you can save a great deal of time as you will not have to debug as much. It really helps "ease of development."
This comment was marked helpful 0 times.
@ycp Based on the content of lecture, it didn't seem that productivity should be characterized as safety. In fact, safety is actually inimical to productivity--ensuring safety in an unsafe language takes a lot of thinking, and using a safe language takes brain power to understand how to do unsafe things in a safe context. We place Javascript on the axis of productivity and completeness, but I can say from experience that any sort of sufficiently complex JS app is wrought with dangerous race conditions if not coded correctly (and it's single threaded!!!).
On a related note, SML isn't really high performance (not a systems language) or complete (limited side effects). Arguably it's relatively productive since it gives us high-level reasoning about our code, although some people would argue against that. Really, SML is great because of its type system and data immutability which provide safety to its programs.
This comment was marked helpful 0 times.
@wcrichto I agree with what you are saying mostly. Actually, what I was trying to get at was similar to what you said with "..ensuring safety in an unsafe language takes a lot of thinking..." because in a language that requires more thought for safety, takes away from the productivity of the language. As a good programmer is concerned with safety, when he is forced to spend more time on safety, his productivity goes down in terms of lines of code written (but I guess stays high in terms of quality of code written). Moreover, when we think about JS, I think its still fair to say that it is a productive language even though it can be wrought with dangerous race conditions because it has many higher order functions that make many tasks fairly simple. I would imagine that a "complex JS app" that has the potential to be very unsafe could still be much shorter then if written in another language.
This comment was marked helpful 0 times.


I can understand why it would be really difficult to make a language which is both high-performance and productive. As mentioned in other slides, it seems to be mostly because efficiency means knowing the hardware and making extremely detailed and complicated code to extract everything out of the hardware. But it's not immediately clear to me why getting rid of completeness would fix that problem and make code portable between types of hardware.
One reason I can think of is that it could be because the compiler/interpreter will know exactly what the code is doing up to certain parameters and constants. So it will know the most efficient mappings for those problems. But that doesn't really explain it all to me. Do domain-specific languages have to detect whether the computer has SIMD, how many cores it has, what levels its caches are on, etc.? If so, why doesn't that slow it down?
This comment was marked helpful 0 times.

The productivity of the domain specific languages comes from limiting the power of the language. In another word, if there is only a few things you can do with the language, then it is relatively easier to use. In addition, limiting the power of a language allows for more optimizations and therefore the performance gain. With limit power of the language, the implementation of framework or the interpreter can make more assumptions in optimizing the code.
This comment was marked helpful 0 times.

@jmnash say that you have a domain specific graphics language. Then the language knows to look for HW specifics that would be of benefit to graphics processing (things like SIMD, on-board gpus, dedicated texture units and other graphics-dedicated ASIC units). In a generic language, there are just too many variables to take into account when optimizing code according to HW.
This comment was marked helpful 0 times.


It looks like what this lecture is leading towards is a declarative language, where you declare what operations you want to perform and the back-end figures out the most efficient way of doing so. The canonical example (at least to my knowledge) is SQL. Users describe how they want their database to look (the schema) and create queries which are really just a description of how to pull data out of this database. Implementations are free to represent the back-end, the tables, however they would like and this has led to a variety of implementations each with their own strengths and weaknesses.
This comment was marked helpful 1 times.

There are two main ways to implement a Domain-Specific Programming System. The first way is to develop a domain specific language as a standalone language, which in this case would involve a process close to what @tchitten commented on above, and SQL and Matlab are examples of this process. The second method involves embedding the domain specific language in a general programming language, and examples of this process are the C++ library and Lizst which is described in the slides ahead. This second method usually involves facilitation where the compiler can be modified so that the parsing part of the compiling process is utilized, but the optimization and code generation phase is modified.
This comment was marked helpful 0 times.


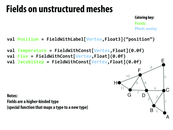

I still don't get what is a field... So in the example above, which types are we mapping from, and which types are we mapping to?
This comment was marked helpful 0 times.

Specifically, Liszt provides the following features:
a) Mesh elements (vertices, cells, faces, edges) b) Sets (for grouping mesh elements, such as cells in a mesh, vertices in a cell, etc) c) Topological relationships (obtain neighboring elements of a mesh element) d) Fields (store data, using a map from all mesh elements of particular type to a value) e) Parallelism (a parallel for-comprehension; this is not a for-loop, as there are no loop-dependencies).
It also constrains the programmer to statically-typed non-recursive functions (presumably to improve/make possible reasoning about the parallelization/locality/synchronization of the program).
This comment was marked helpful 0 times.

The way to read the val Temperature = FieldWithConstVertex,Float is: Define a function from a vertex to a float, which returns the temperature at that vertex. The initializer is the floating point value 0.0f.
This comment was marked helpful 0 times.
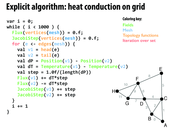
Note: The for loop is implicitly parallel.
Liszt will automatically deal with the race condition between the fields in the steps where it writes to the fields.
This comment was marked helpful 0 times.




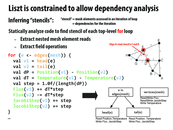


Some of the research I did over the summer involved some data dependency analysis, and one of the first steps of the analysis was to convert the code to a more restricted language to simplify things (SSA, unroll recursion, etc). Definitely would be useful to start off with this, and it's a very interesting problem!
This comment was marked helpful 0 times.


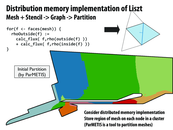
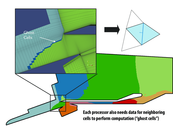
I'm a little confused about the purpose of ghost cells. Are they just cells that aid communication between the different partitions? Would they be the cells along the boundaries?
This comment was marked helpful 0 times.

Remember this implementation is for a distributed address space system (e.g., a cluster of machines). "Ghost cells" are cells that are replicas of cells "owned" by another processor. The ghost cells store a replicated copy of the data on the local processor because this data is a necessary input to computations that actually update data owned by the local processor. Here, consider how in the processor of updating face 6, the update computation might need information from face 15.
In the diagram it's best to consider that all the grey cells, both dark and light are owned by processor P, and that the white ghost cells are owned by remote processors.
This comment was marked helpful 0 times.

Am I right then in saying that ghost cells are like non-exclusive copies of a piece of memory held in the caches of processors other than the one actually performing operations on it?
This comment was marked helpful 0 times.

I think the key point is that the data is the ghost cells is only brought over to another processor because they are necessary to the computation of results on a processor. The only reason that a processor would suffer the communication cost of bring cells over is if the cells are needed for computation
This comment was marked helpful 0 times.
@benchoi: sure, that's a good way to think about it. However, you should understand this is being done by the application, not the hardware. It is not replication of a memory address (e.g., like how a cache transparently replicated data in the address space), it's the application making copies of the data on its own.
This comment was marked helpful 0 times.
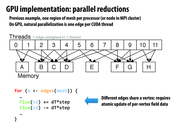
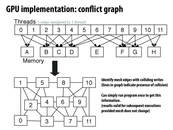

We discussed different strategies for figuring out independent set. If I remember correctly there was a greedy approach, an approach based on Max Independent set and another. Does anyone remember the last one?
This comment was marked helpful 0 times.
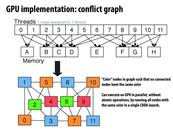

There are several solutions mentioned in the class. A simple way to solve the conflict is to make operations on each node atomic. Yet this solution would make updates sequential. Also, the conflict could be avoided dynamically. Mechanisms like buffering the updates for each node are more efficient than the atomic operations. The third way to solve the conflict problem is static scheduling, like the coloring in this slide. Different colors are run in different rounds in parallel. The potential problem for this method is the time complexity of scheduling, since coloring problem is known as NP problem.
This comment was marked helpful 0 times.

@squidrice, I am wondering why buffering would be mor efficient? So each node has a buffer of changes, but I think buffer index is also like an atomic add.
This comment was marked helpful 0 times.

@squidrice, scheduling is also NP-hard (it's pretty similar to coloring as seen on this slide, and in fact you can reduce 3-coloring to it to prove it NP-hard). But there could still be some efficient approximation that could be used for it, and that's a pretty popular area of research because of how commonly scheduling comes up.
This comment was marked helpful 0 times.
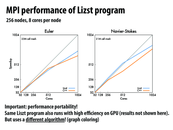

How does Liszt get superlinear speedup on Navier Stokes up to 512 cores? Is the algorithm used simply that much more efficient?
This comment was marked helpful 0 times.

Hmm... does the speedup here refer to speedup from the Liszt program running on one core or the speedup from some baseline C++ program on one core?
This comment was marked helpful 0 times.




I don't understand the last comment about recomputing intermediate values. Any pointers?
This comment was marked helpful 0 times.

This code implements integer division (for which there is surprisingly no SSE/AVX intrinsic) by integer multiplication. This is a very cool trick called " Division by invariant integers using multiplication", published in 1994 (citation below) and built into GCC. There's a blog post explaining the method here.
Granlund, Torbjörn, and Peter L. Montgomery. "Division by invariant integers using multiplication." ACM SIGPLAN Notices. Vol. 29. No. 6. ACM, 1994.
This comment was marked helpful 0 times.

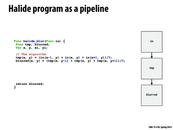

I believe that the schedule lines should be written with blurred and tmp swapped to make the code analogous to the C++ version.
EDIT: Actually nevermind, looks like the operations can be done either way. The code on the Halide website looks familiar though.
This comment was marked helpful 0 times.



I saw three questions from a paper and was confused about why do following questions matter to performance. 1. When and where should the value at each coordinate in each function be computed? 2. Where should they be stored? 3. How long are values cached and communicated across multiple consumers, and when are they independently recomputed by each?
This comment was marked helpful 0 times.

I actually read the same paper - link for those curious (I think Kayvon may have gotten some of the figures from there e.g. Figure 4) : http://people.csail.mit.edu/jrk/halide-pldi13.pdf.
Something that baffles me is that I can't really seem to find any examples/explanations of the 5th primitive reuse. In this paper, they give a nice visualizations over the four scheduling examples listed here, but no sign of "reuse". Is there a reason why reuse is used less/not spoken about as much?
Also, as for your question, I believe they have a really nice example a little further down (the one Kayvon used in class) with blurx and out where they talk about tradeoffs between all the different scheduling techniques.
This comment was marked helpful 0 times.



I'm confused at why Halide is 2x faster than CUDA. My understanding is that both Halide (with the right scheduling) and CUDA both use the same processors and threads as efficiently as possible. Where does the 2x speedup come from then?
This comment was marked helpful 0 times.

One reason could be that it's theoretically possible to write CUDA code by hand that is as fast as Halide, but that it's impractical (e.g. would take thousands of lines of illegible code). Halide is specifically designed to generate machine code that is as efficient as possible for a very constrained domain, whereas CUDA is much more general-purpose.
Another reason could be because Halide uses JIT compiliation. This means that a program in Halide can generate new machine code while it's running, which isn't really possible just using CUDA. JIT compilation is what makes the JVM interpreter as fast as (and sometimes faster) than machine code compiled from C++.
This comment was marked helpful 0 times.

I'm surprised by the camera RAW processing pipeline results. Is the hand-tuned ARM assembly code that has generated from C++ and then hand-tuned? And what does 2.75x less code mean? 2.75x fewer lines of Halide code compared to the lines of assembly? It seems a bit magical that the result is 5% faster than a hand-tuned assembly implementation.
This comment was marked helpful 0 times.

Another reason for the 2x speedup over hand-written CUDA is that Halide, from what I've read on it, doesn't just use the GPU. If all of the low level code that the Halide compiler generated was in CUDA, I suspect the implementations would be similar in speed. However, Halide leverages more resources out of the computer by vectorizing code, multithreading, and using the GPU. Here's a quote from the Halide paper the scheduling pictures from a few slides back: "The implementation is multithreaded and vectorized according to the schedule, internally manages the alloca- tion of all intermediate storage, and optionally includes synthesized GPU kernels which it also manages automatically".
This comment was marked helpful 0 times.
Also, in general, a good compiler is much better at optimization than mostly any human hand-writing code, which could be responsible for at least some of the speedup.
This comment was marked helpful 0 times.


Note both hadoop and model-view-controller paradigm for web-apps embed the dsl into generic programming languages (java and whatever web-language used)
This comment was marked helpful 0 times.


There's actually a really neat startup in Seattle called Intentional Software working on making domain-specific languages more available. Their goal is to provide a "meta-language" using which domain experts can write their own domain-specific languages for fun and profit. It still has a ways to go before hitting it big, but it's a really neat idea.
This comment was marked helpful 0 times.



http://en.wikipedia.org/wiki/Domain-specific_language#Advantages_and_disadvantages
Additional advantages of DSL: better maintainability and reusability of code due to how specific the language is. Domain specific languages may also help to abstract the problem better so that programming is easier (perhaps so we don't have to worry about the internals of the computer since the language has taken care of it for us).
Some disadvantages of DSL: less people in the world know these languages, so support (stackoverflow/examples) is harder to get. Also, integration with the rest of the code could possibly be problematic (we sometimes can't load the DSL onto systems with less amounts of memory, such as trying to load MATLAB onto an embedded system)
This comment was marked helpful 0 times.


I wrote OpenGL before, the syntax of OpenGL is not strange if developer has basic knowledge of other programming language. And some simple API can complete complex job, such as rendering the texture of an object. The only strange thing to me is the code need to write in the reverse way in which the object to be built.
This comment was marked helpful 0 times.
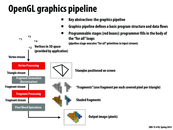



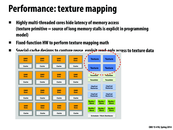
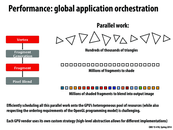


There are many ways to even further optimize the performance in openGL. This article goes into some of the basics :
Basics of optimizing performance in openGL
This comment was marked helpful 0 times.
In addition to chip area and power, are there other relevant constraints when trying to maximize the potential computation ability? One that comes to mind is cost associated with the parts of the chip.
This comment was marked helpful 0 times.