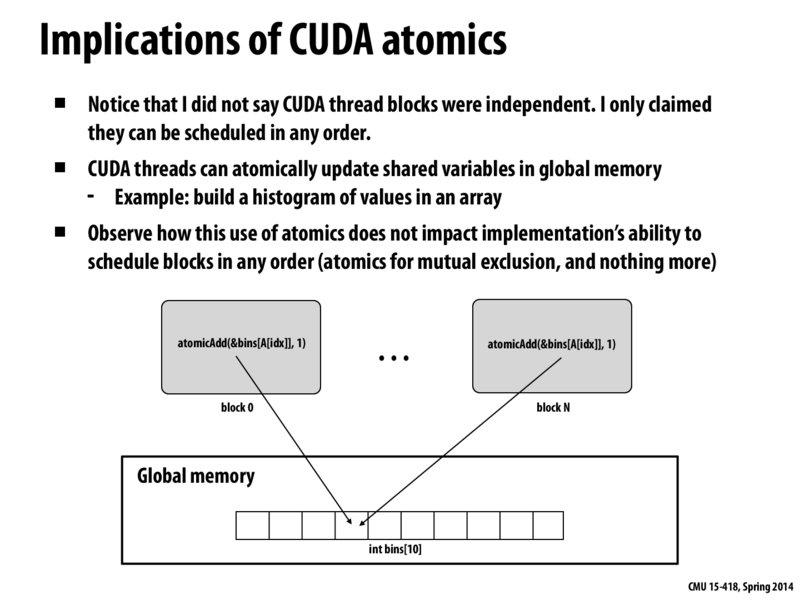
What exactly is the difference between blocks being independent and being scheduled in any order? Does independence imply some strong condition about the state of the threads which isn't true in the implementation of CUDA?
How can one ensure atomicity in memory updates among different cores? If you have two cores each running different CUDA blocks that want to update the same region of shared memory, what kind of communication has to happen to avoid race conditions?
This comment was marked helpful 0 times.
bxb
@wcrichto
If you take a look at the CUDA Toolkit Documentation - Thread Hierarchy it implies that because thread blocks are required to execute independently they can be scheduled in any order. Independence refers to control/data dependency; a block cannot rely on the results of another block in order to operate independently.
There is no one simple way to synchronize across all blocks. The best I could come up with was to launch a kernel, cudaThreadSynchronize() and launch another kernel. You could also check out some of the atomic operations in the Toolkit Documentation and perhaps use it to implement a mutex or semaphore. I have not looked too much into it but a host of __threadfence() operations also support memory ordering of sorts.
A few questions:
What exactly is the difference between blocks being independent and being scheduled in any order? Does independence imply some strong condition about the state of the threads which isn't true in the implementation of CUDA?
How can one ensure atomicity in memory updates among different cores? If you have two cores each running different CUDA blocks that want to update the same region of shared memory, what kind of communication has to happen to avoid race conditions?
This comment was marked helpful 0 times.
@wcrichto
If you take a look at the CUDA Toolkit Documentation - Thread Hierarchy it implies that because thread blocks are required to execute independently they can be scheduled in any order. Independence refers to control/data dependency; a block cannot rely on the results of another block in order to operate independently.
There is no one simple way to synchronize across all blocks. The best I could come up with was to launch a kernel, cudaThreadSynchronize() and launch another kernel. You could also check out some of the atomic operations in the Toolkit Documentation and perhaps use it to implement a mutex or semaphore. I have not looked too much into it but a host of __threadfence() operations also support memory ordering of sorts.
This comment was marked helpful 0 times.