The program on this slide may cause dead lock, but the one on previous slide would not. The reason is that the global variable may change the control on this slide, while the blocks on the previous one are relatively independent to the value of global memory. Though the previous program is safe from dead lock, the value of the global variable is not reliable, if the change is not atomic.
This comment was marked helpful 0 times.
asinha
How are the CUDA atomics implemented? I have 2 ideas that I think I've heard, one is that on a low level the hardware makes sure that the atomic operation occurs in a single clock cycle, and the second idea is of course the use of a mutex. Also, I don't understand the point of atomic operations in terms of only ensuring the integrity of a small set of operations (addition, subtraction, etc.). Why not just put a lock around the operation instead of having to call the CUDA atomics?
This comment was marked helpful 0 times.
kayvonf
Notice that atomic operations (like: atomicAdd, compare_and_swap, test_and_set) synchronize a sequence of loads/stores to a single address. Operations on different addresses can occur independently. To get similar functionality using a mutex, you'd need one mutex per address.
Consider building a histogram in parallel, where threads atomically increment bin counts: e.g., bins[i]++. Imagine if there are thousands of bins. If you wanted the same fine grained synchronization ability, you'd need a mutex per bin.
Processors provide atomic instructions. Mutex implementations are then built using these atomic primitives. We'll talk about how to build higher level synchronization out of atomic operations in a later lecture.
This comment was marked helpful 0 times.
jinsikl
The program in the previous slide will not deadlock since the blocks are not dependent on each other.
In this program, the blocks are dependent on each other. Specifically, we see that block N depends on block 0 having executed first. The problem with this is that it is possible for block N to be scheduled before block 0. If our GPU has a single core, then block N will spin forever, since block 0 will never get scheduled.
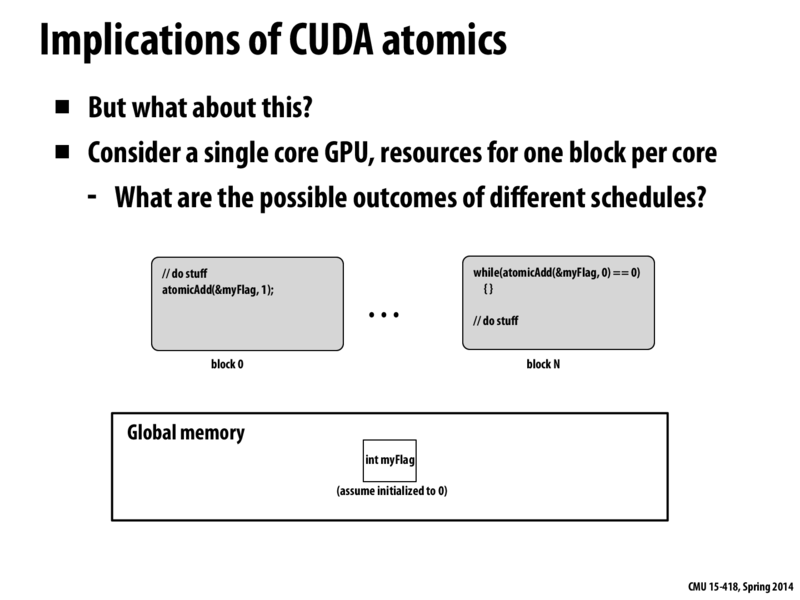
The program on this slide may cause dead lock, but the one on previous slide would not. The reason is that the global variable may change the control on this slide, while the blocks on the previous one are relatively independent to the value of global memory. Though the previous program is safe from dead lock, the value of the global variable is not reliable, if the change is not atomic.
This comment was marked helpful 0 times.
How are the CUDA atomics implemented? I have 2 ideas that I think I've heard, one is that on a low level the hardware makes sure that the atomic operation occurs in a single clock cycle, and the second idea is of course the use of a mutex. Also, I don't understand the point of atomic operations in terms of only ensuring the integrity of a small set of operations (addition, subtraction, etc.). Why not just put a lock around the operation instead of having to call the CUDA atomics?
This comment was marked helpful 0 times.
Notice that atomic operations (like:
atomicAdd,compare_and_swap,test_and_set) synchronize a sequence of loads/stores to a single address. Operations on different addresses can occur independently. To get similar functionality using a mutex, you'd need one mutex per address.Consider building a histogram in parallel, where threads atomically increment bin counts: e.g.,
bins[i]++. Imagine if there are thousands of bins. If you wanted the same fine grained synchronization ability, you'd need a mutex per bin.Processors provide atomic instructions. Mutex implementations are then built using these atomic primitives. We'll talk about how to build higher level synchronization out of atomic operations in a later lecture.
This comment was marked helpful 0 times.
The program in the previous slide will not deadlock since the blocks are not dependent on each other.
In this program, the blocks are dependent on each other. Specifically, we see that block N depends on block 0 having executed first. The problem with this is that it is possible for block N to be scheduled before block 0. If our GPU has a single core, then block N will spin forever, since block 0 will never get scheduled.
This comment was marked helpful 0 times.