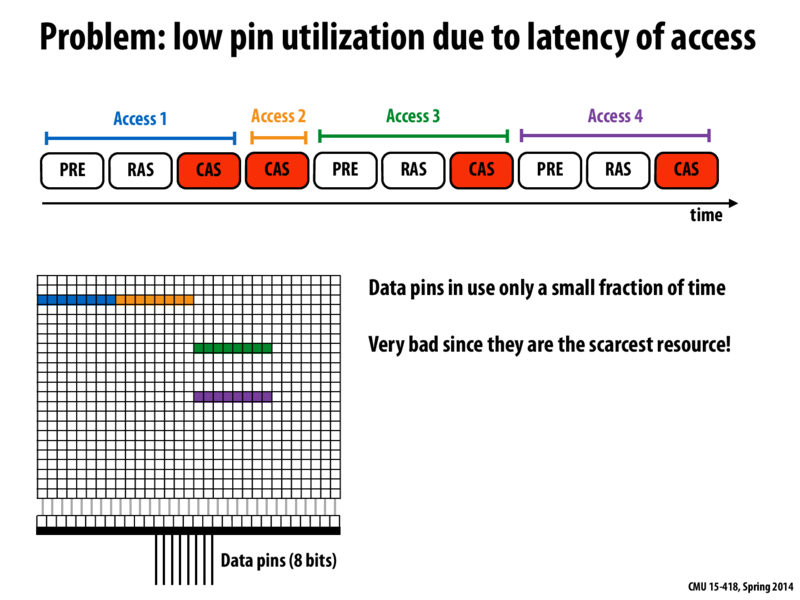
My understanding of this slide is that if you're just performing these memory accesses in sequence, if we have a lot of different rows being accessed then we're only using the data pins about a third of the time to read 8 bits. The rest of the time is spent waiting for the other steps, like pre-loading a row and putting the row into the row buffer. So, we need to try to use the pins more since they are the scarcest resource and the bandwidth bottleneck.
I'm confused about one thing though: I thought that generally you would always load up a whole cache line from memory at a time upon a cache miss. Why is it that these accesses are just 8 bits at a time, and then move on to different rows in DRAM? Or is it actually for this reason that we load a whole cache line from memory at a time, using the 8-chip mechanism described later?
This comment was marked helpful 0 times.
kayvonf
@arsenal: Correct. This slide is simply illustrating how DRAM works (what it's capabilities are).
In a real system, we are often only requesting cache line sized chunks of memory from the memory system, and that bulk granularity is key to enabling higher performance access to memory. Later in the lecture we talk about mapping cache lines to chips in a DIMM.
My understanding of this slide is that if you're just performing these memory accesses in sequence, if we have a lot of different rows being accessed then we're only using the data pins about a third of the time to read 8 bits. The rest of the time is spent waiting for the other steps, like pre-loading a row and putting the row into the row buffer. So, we need to try to use the pins more since they are the scarcest resource and the bandwidth bottleneck.
I'm confused about one thing though: I thought that generally you would always load up a whole cache line from memory at a time upon a cache miss. Why is it that these accesses are just 8 bits at a time, and then move on to different rows in DRAM? Or is it actually for this reason that we load a whole cache line from memory at a time, using the 8-chip mechanism described later?
This comment was marked helpful 0 times.
@arsenal: Correct. This slide is simply illustrating how DRAM works (what it's capabilities are).
In a real system, we are often only requesting cache line sized chunks of memory from the memory system, and that bulk granularity is key to enabling higher performance access to memory. Later in the lecture we talk about mapping cache lines to chips in a DIMM.
This comment was marked helpful 0 times.