Could someone help me understand what is going in this slide (and last slide)? Based on my understanding, this slide shows that combining consecutive accesses to the same row into one access leads to lower latency. Is that a reasonable interpretation?
This comment was marked helpful 0 times.
wcrichto
My understanding is that our DRAM should just allow requests for more data than could be transferred out from the data pins in any one clock cycle in order to optimize our latency. So I think you're right, @tomshen.
This comment was marked helpful 0 times.
bstan
A system's bottleneck should never sit idly if one wants to maximize throughput. That's why each DRAM command describes bulk transfer. The controller gets more data than each request. The data pins are kept busy by loading the next lines that may be transferred, even if they don't end up getting used.
This comment was marked helpful 2 times.
asinha
Burst Mode capability of DRAM allows it to skip one of the three following steps when transmitting data in a data transaction to increase data throughput:
1. Waiting for input from another device
2. Waiting for an internal process to terminate before continuing data transfer
3. Transmitting information which would be required for a complete transaction, but which is inherent in the use of burst mode.
This comment was marked helpful 0 times.
paraU
Every time fetching a cache line size of data from the memory to the cache can amortize the overhead cost.
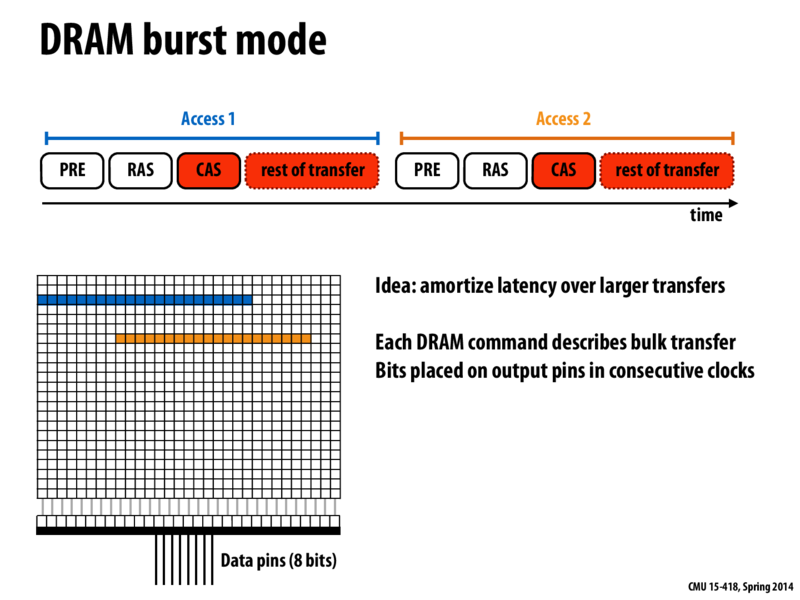
Could someone help me understand what is going in this slide (and last slide)? Based on my understanding, this slide shows that combining consecutive accesses to the same row into one access leads to lower latency. Is that a reasonable interpretation?
This comment was marked helpful 0 times.
My understanding is that our DRAM should just allow requests for more data than could be transferred out from the data pins in any one clock cycle in order to optimize our latency. So I think you're right, @tomshen.
This comment was marked helpful 0 times.
A system's bottleneck should never sit idly if one wants to maximize throughput. That's why each DRAM command describes bulk transfer. The controller gets more data than each request. The data pins are kept busy by loading the next lines that may be transferred, even if they don't end up getting used.
This comment was marked helpful 2 times.
Burst Mode capability of DRAM allows it to skip one of the three following steps when transmitting data in a data transaction to increase data throughput: 1. Waiting for input from another device 2. Waiting for an internal process to terminate before continuing data transfer 3. Transmitting information which would be required for a complete transaction, but which is inherent in the use of burst mode.
This comment was marked helpful 0 times.
Every time fetching a cache line size of data from the memory to the cache can amortize the overhead cost.
This comment was marked helpful 0 times.