The key insight that makes parallelization possible here is that work for each cell only depends on the cells immediately to the left and above. Thus, by doing work in diagonals from the bottom left to the upper right, anytime we do work on a cell, we know that the cells above and to the left of it have already been updated in previous diagonals. Additionally, since within each diagonal, no cell is directly above or directly to the left of any other cell, we can update each of those cells in parallel.
This comment was marked helpful 1 times.
achugh
If the processing of pixels took variable (and large) time, a better algorithm would be to spawn a thread of execution for each pixel and each pixel would wait on its two dependencies before executing (using mutexes?). This way we make sure that every no core has to sit idle while a diagonal is finished.
This comment was marked helpful 0 times.
kayvonf
@achugh: let's say this grid was of modest size, say a mere 1000x1000. What might the problem be with creating one million threads?
This comment was marked helpful 0 times.
achugh
Maybe not all at the same time. You could use some smart look ahead scheme. Like say, when a pixel is getting processed- its grandchildren in the dependency graph get spawned. You would also need to avoid duplicate threads for a pixel. If performance is really important you may be ready to deal with the complexity. And on first look, this doesn't seem totally intractable.
This comment was marked helpful 0 times.
yetianx
A guy mentioned a cool idea that we can use different threads to calculate different iterations. Another guy said we cannot make sure the second iteration runs slower than the first iteration.
Maybe we can do this with some synchronization.
Suppose we have 2 threads, 2 semaphore: sem1 init to 0, sem2 init to n/2(n is the num of rows).
Thread 1
while(some condition){
foreach row {
P(&sem2;)
starts to process two rows
V(&sem1;)
}
}
Thread 2
while(some condition){
foreach row {
P(&sem1;)
starts to process two rows
V(&sem2;)
}
}
Is that a possible solution?
@achugh: sem2 is needed when thread 1 finishes the whole matrix and begin the next iteration, when it has to wait until thread 2 goes ahead of it. Otherwise, if one thread only handle one iteration, we have to use as many threads as the total iteration times.
I did not notice there should be 2 rows between two iterations. So now two rows are processed between P and V. But I'm not confident about its correctness. Could someone give me ideas on this?
This comment was marked helpful 0 times.
achugh
I didn't completely understand the code, can you explain why is sem2 needed? Does it ever cause a wait?
Also, a cell the new Gauss-Seidel iteration would depend on the on the old iteration's cell on the right and the cell below it. So the old iteration needs to be 2 rows ahead of the new one.
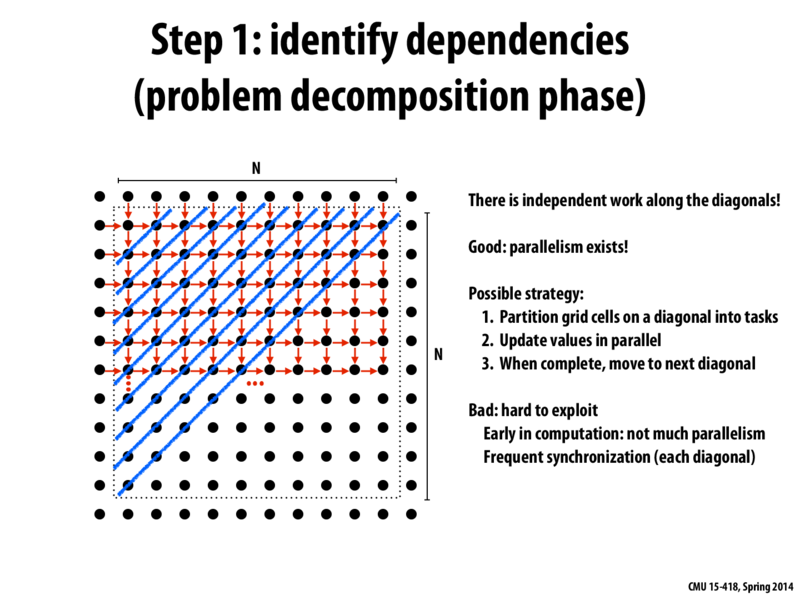
The key insight that makes parallelization possible here is that work for each cell only depends on the cells immediately to the left and above. Thus, by doing work in diagonals from the bottom left to the upper right, anytime we do work on a cell, we know that the cells above and to the left of it have already been updated in previous diagonals. Additionally, since within each diagonal, no cell is directly above or directly to the left of any other cell, we can update each of those cells in parallel.
This comment was marked helpful 1 times.
If the processing of pixels took variable (and large) time, a better algorithm would be to spawn a thread of execution for each pixel and each pixel would wait on its two dependencies before executing (using mutexes?). This way we make sure that every no core has to sit idle while a diagonal is finished.
This comment was marked helpful 0 times.
@achugh: let's say this grid was of modest size, say a mere 1000x1000. What might the problem be with creating one million threads?
This comment was marked helpful 0 times.
Maybe not all at the same time. You could use some smart look ahead scheme. Like say, when a pixel is getting processed- its grandchildren in the dependency graph get spawned. You would also need to avoid duplicate threads for a pixel. If performance is really important you may be ready to deal with the complexity. And on first look, this doesn't seem totally intractable.
This comment was marked helpful 0 times.
A guy mentioned a cool idea that we can use different threads to calculate different iterations. Another guy said we cannot make sure the second iteration runs slower than the first iteration.
Maybe we can do this with some synchronization.
Suppose we have 2 threads, 2 semaphore: sem1 init to 0, sem2 init to n/2(n is the num of rows).
Thread 1
Thread 2
Is that a possible solution?
@achugh: sem2 is needed when thread 1 finishes the whole matrix and begin the next iteration, when it has to wait until thread 2 goes ahead of it. Otherwise, if one thread only handle one iteration, we have to use as many threads as the total iteration times.
I did not notice there should be 2 rows between two iterations. So now two rows are processed between P and V. But I'm not confident about its correctness. Could someone give me ideas on this?
This comment was marked helpful 0 times.
I didn't completely understand the code, can you explain why is sem2 needed? Does it ever cause a wait?
Also, a cell the new Gauss-Seidel iteration would depend on the on the old iteration's cell on the right and the cell below it. So the old iteration needs to be 2 rows ahead of the new one.
This comment was marked helpful 0 times.