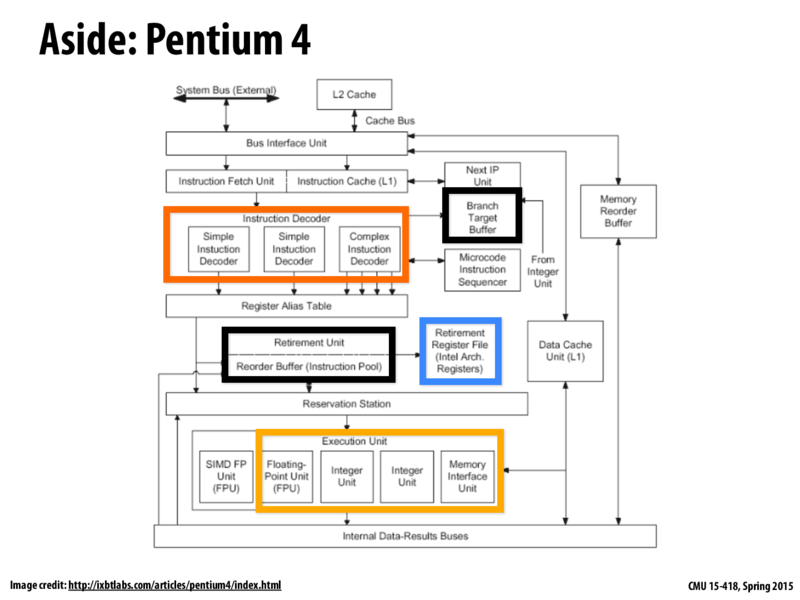
Question: Anyone want to take a stab at explaining what the outlined units in the diagram above actually do/how they work with each other?
sam
Instruction decoder basically decodes the instruction to figure out what it is supposed to do.
Execution unit is basically performing the required operation on the operands as determined by the Instruction decoder.
Role of reorder buffer is to make sure that instructions retire in program order. This is needed here because of the presence of multiple execution units which can do out of order execution of instructions.
Retirement Register File denotes the architected state of the machine. When reorder buffer retires any instruction, it updates the corresponding registers, which is required for correct execution of the program.
Branch Target Buffer is small memory which contains the target addresses for different branches. So if the branch is taken the next instruction is fetched from the address given by Branch target buffer.
byeongcp
I see that the instruction decoders are separated into "simple instruction decoder" and "complex instruction decoder." What instruction constitutes as a "complex instruction?" What kind of code produces instructions that can only be decoded by a complex instruction decoder?
It seems like the number of complex instruction decoders are likely to be less than the number of simple instruction decoders, which means the number of complex instructions could potentially limit the speedup. This might be an extreme scenario, but would it be possible for a person like me (who is not aware of complex instructions) somehow write code that produces excessive number of complex instructions, or are modern compilers smart enough to make up for my ignorance?
Azerty
@byeongcp I think "Complex Instructions" stands for instructions that "imply" other instructions (in CISC architecture). No need for the compiler to set any load/store instruction and to manipulate any register to do a multiplying operation for instance, it would directly use memory addresses. The processor would then take care of using the appropriate registers to store the value, and store the results.
It is different from a "Simple Instructions" approach (which RISC architecture only uses) which requires the compiler to explicitly tell every instruction step by step.
gryffolyon
Am a bit late at this. But I remember Kayvon saying that the processors are intelligent at finding independent instructions and execute them in parallel. How does the processor designers arrive at how the number of instructions that a processor can execute in parallel? For example, in this slide we see 3 integer execution units, 1 Floating point execution unit and 1 SIMD execution unit. Why are these numbers so?
wtwood
@gryffolyon I would guess it's just trial and error. We saw last week that when you get above four instructions per clock, you don't get much speed-up. Presumably they have similar graphs for the different combinations of execution units and found that two integer, one floating point, and one memory access was pretty near optimal.
kayvonf
@gryffolyon, they'll perform workload analyses, such as the one illustrated in the ILP graph in lecture 1. Then an architect can make decisions about the benefits that would be observed with varying number of resources, and way them against the cost of adding them. Weighing various benefits and costs to design efficient systems is a major theme of this course!
Question: Anyone want to take a stab at explaining what the outlined units in the diagram above actually do/how they work with each other?
I see that the instruction decoders are separated into "simple instruction decoder" and "complex instruction decoder." What instruction constitutes as a "complex instruction?" What kind of code produces instructions that can only be decoded by a complex instruction decoder?
It seems like the number of complex instruction decoders are likely to be less than the number of simple instruction decoders, which means the number of complex instructions could potentially limit the speedup. This might be an extreme scenario, but would it be possible for a person like me (who is not aware of complex instructions) somehow write code that produces excessive number of complex instructions, or are modern compilers smart enough to make up for my ignorance?
@byeongcp I think "Complex Instructions" stands for instructions that "imply" other instructions (in CISC architecture). No need for the compiler to set any load/store instruction and to manipulate any register to do a multiplying operation for instance, it would directly use memory addresses. The processor would then take care of using the appropriate registers to store the value, and store the results. It is different from a "Simple Instructions" approach (which RISC architecture only uses) which requires the compiler to explicitly tell every instruction step by step.
Am a bit late at this. But I remember Kayvon saying that the processors are intelligent at finding independent instructions and execute them in parallel. How does the processor designers arrive at how the number of instructions that a processor can execute in parallel? For example, in this slide we see 3 integer execution units, 1 Floating point execution unit and 1 SIMD execution unit. Why are these numbers so?
@gryffolyon I would guess it's just trial and error. We saw last week that when you get above four instructions per clock, you don't get much speed-up. Presumably they have similar graphs for the different combinations of execution units and found that two integer, one floating point, and one memory access was pretty near optimal.
@gryffolyon, they'll perform workload analyses, such as the one illustrated in the ILP graph in lecture 1. Then an architect can make decisions about the benefits that would be observed with varying number of resources, and way them against the cost of adding them. Weighing various benefits and costs to design efficient systems is a major theme of this course!