I am assuming that loading from a different row will "de"charge the bits and that only one row may be charged at the same time. Thus, it is wise to read all of the bits that are charged at the same time, instead of reading different segments in an interleaved fashion.
gryffolyon
As Kayvon says in the comments of this slide here, while its beneficial to read all of the bits, we can enable pipelining while we access these banks. When one bank is doing a pre-charge or an activation, we can have another bank that can be transferring the data over the bus
ak47
This question came up in class but I wasn't sure of the answer:
Wouldn't it be advantageous to this structure be as wide as possible? Wouldn't that increase our number of "line hits?"
gryffolyon
I guess that adds more cost to the hardware, your chip sizes increase etc
BryceToTheCore
@ak47 It also makes it more difficult to fully utilize the all of the activated bytes. This is kind of like if we increased the cache line size of a machine, that would be more expensive and would incur more memory movement per line read, which would require programs with broader and broader locality regions to make it worth the extra performance and economic costs.
iZac
Also penalty for row miss will increase, higher latency for precharge and activation.
aznshodan
Think of Row Buffer as cache. From spatial locality you can potentially have more cache or row buffer hits. But at the same time, if there is a miss, a bigger cache line or a bigger row buffer will take longer to replace than a smaller cache line or a smaller row buffer.
flyne
Also, making it as wide as possible would also increase energy consumption
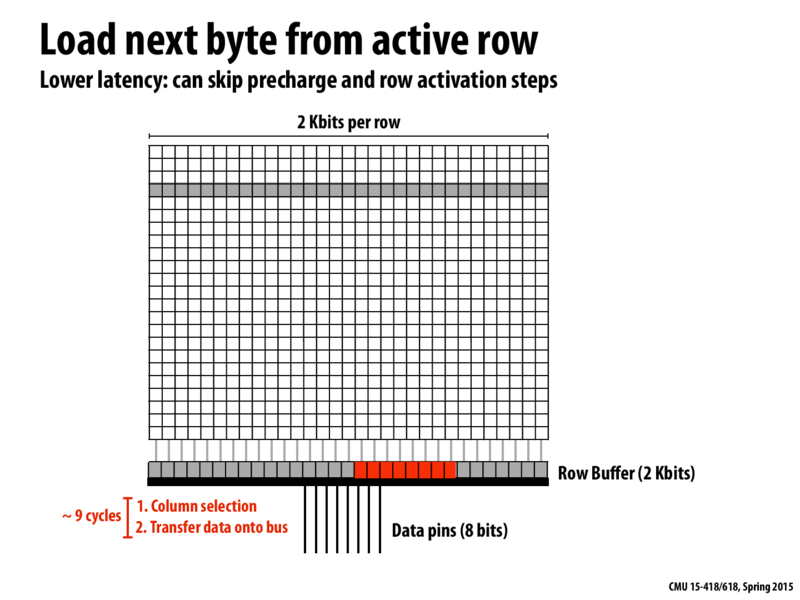
I am assuming that loading from a different row will "de"charge the bits and that only one row may be charged at the same time. Thus, it is wise to read all of the bits that are charged at the same time, instead of reading different segments in an interleaved fashion.
As Kayvon says in the comments of this slide here, while its beneficial to read all of the bits, we can enable pipelining while we access these banks. When one bank is doing a pre-charge or an activation, we can have another bank that can be transferring the data over the bus
This question came up in class but I wasn't sure of the answer: Wouldn't it be advantageous to this structure be as wide as possible? Wouldn't that increase our number of "line hits?"
I guess that adds more cost to the hardware, your chip sizes increase etc
@ak47 It also makes it more difficult to fully utilize the all of the activated bytes. This is kind of like if we increased the cache line size of a machine, that would be more expensive and would incur more memory movement per line read, which would require programs with broader and broader locality regions to make it worth the extra performance and economic costs.
Also penalty for row miss will increase, higher latency for precharge and activation.
Think of Row Buffer as cache. From spatial locality you can potentially have more cache or row buffer hits. But at the same time, if there is a miss, a bigger cache line or a bigger row buffer will take longer to replace than a smaller cache line or a smaller row buffer.
Also, making it as wide as possible would also increase energy consumption