I took an OS course once and learned that the operating system chooses how to schedule threads, and that when one is waiting for memory it's taken off the core and another thread is put in. In this class we have only looked at the hardware of each core choosing which thread to run.
Do these contradict? Or does the OS choose how to fill up the blue boxes in the above diagram, and the core chooses which blue box to run?
kayvonf
@russt17: Exactly! They do not contradict. They are the same idea of using interleaved execution to hide latency, but at different granularities.
The operating system will take thread T1 off the processor and schedule another thread T2 in it's place when it knows T1 is blocked on a very long latency operation such as a disk access. The cost of the OS context switching a thread into an execution context is large -- perhaps 100,000's of cycles. The cost of an OS context switch is way too high for it to be the mechanism to handle stalls due to memory (DRAM) access, which are at most hundreds of cycles. (It's pretty silly to pay 100,000 cycles as a solution to a 100 cycle stall!) Thus, if there is to be context switching to hide memory latency, it must be performed extremely efficiently by the hardware itself. That context switching, to be fast, can't involve much data copying. Thus the processor maintains multiple execution contexts (blue boxes) and chooses which one to run.
russt17
@kayvonf: Thanks, that makes a lot of sense!
andymochi
@kayvonf: Are the 'execution context' blocks in our diagrams implemented in software, hardware or either?
We said on lecture 2, slide 50 that our contexts are stored in the L1 cache of the processor (software threads?), but I'm not sure if this means that we can still support running two simultaneous threads (e.g. hyper-threading). I feel like we'd still need some way to double the read/write bandwidth of the ALU <-> context logic to support this if it is not implemented in hardware.
I think we've come across the notion of 'hardware-implemented' threads before. Does this mean that we can expect there to be two physical register sets for the separate execution contexts?
I'm not entirely sure if the answer to this question matters, but I think it is useful to be able to understand the processor spec sheet here. Under the performance section, it says # threads (which I assumed meant the # of hardware threads available over all of the cores).
kayvonf
This is very important.
The execution context as a component of the hardware. It is on-chip storage.
Do not think of the execution context as data in the L1 cache.
The execution context in this diagram referred to the storage provided by the processor to maintain state required to execute a thread. In class we talked about one major example of this state being registers (including stack pointer, program counter, etc.). This storage is a component of the hardware. A processor that supports hardware-multi-threading, such as the made-up processor in the diagram above, will have storage for multiple execution contexts (e.g, 2 sets of registers as shown above).
In the Intel ARK processor link you mentioned, the specs say the chip has four physical cores but can maintain state for up to eight threads. So yes, that means each core has state for two threads (Which, not surprisingly, is exactly like my fake processor above.) Intel Hyper-threading is the external marketing name for their implementation of maintaining state for two threads on each core at once, and then choosing which instructions to run from those two threads on each clock. A more detailed description of Hyper-Threading is on this slide.
On lecture 2, slide 50, the point I was trying to make is that given a fixed amount of storage on a chip, supporting more threads at once necessarily means that the execution contexts of those threads much be smaller. I see how this could be a bit confusing, especially since we haven't talked about GPU architecture yet, so think about it this way:
On most CPUs, all execution contexts are exactly the same size since the architecture precisely defines that an x86 thread has a specific number of registers, etc. (It's part of the architectural abstraction.) Thus, moving from a single-threaded processor to a two-threaded processor means that the chip mean provide twice as much storage to hold the execution contexts of two threads. However on GPUs, the size of an execution context is actually dynamic based on the program being run. The compiler emits a binary that declares how many registers it needs. Then, the GPU uses this number to figure out how many threads it can run at once on a core based on how many execution contexts it can support from a fixed pool of SRAM storage on the processor.
On lecture 2, slide 50 I put "or L1 cache" in parens just to indicate that this idea of partitioning a fixed pool of store into contexts pertains to both the register storage, but also the working set of the program out in memory. For example, imagine you had one thread that had a working set of 16KB of data, and so most of it's data accesses hit in the L1 cache. However, now imagine you run two threads at the same time on a Hyper-Threaded processor, so the combined working set of the two threads is now 32KB. If the L1 cache of the core was only 16KB, then the two thread case would suffer far more cache misses, something that you might have observed on Exercise 1.
Just keep in mind that running multiple threads at the same time is a good thing because it allows for fine-grained latency hiding to reduce stalls. But there's no free lunch, all the resources on the chip are shared among those threads: including the ALUs and on-chip storage resources (whether that be storage for data in the L1 cache, or storage used to maintain execution contexts).
BigFish
If there are only two execution contexts on a core, the hardware context switch only support two threads? That means if we have more than two threads on a core, we must let OS to do the context switch, which is too costly?
In Exercie 1 question E, I found that using 4 threads on a core can completely hide the memory latency although there is no cache hit, with the assumption that the cost of context switch of these four threads on a single core only takes several cycles. So this assumption cannot hold at all? To support hardware context switch between four threads, we need four execution contexts like lecture 2 slide 48?
andymochi
@kayvonf I forgot to thank you for the awesome explanation. Thanks!
@BigFish I believe the answer 4 threads total with 2 threads per core. Also, the quiz described a processor which was two-way multi-threaded with two hardware contexts. This indicated a few things. Only one thread was running at a time. Each core could run up to two threads without having to load a context from the O.S. The answer to that exercise was 4 threads with 2 threads per core as expected.
This does raise a good question though. Is this an accurate statement?
I'm guessing that we can consider the O.S. context switch a cache-hit (contexts are likely small enough that they won't get evicted?)
BigFish
@andymochi It seems that OS context switch should be much higher than memory stall, since we have to store many states. So we cannot hide memory stall using four threads given that we have only 2 execution contexts. However, I believe that if we have 4 execution contexts, and the cache is still 16KB. Although the size of working set is 6KB * 4 = 24KB. We can achieve a speedup even though there is no cache hit, since the CPU is doing computation all the time.
kayvonf
@andimochi:
You can assume the latency of a hardware context switch is 0. (and if not zero, just a few cycles)
Latency of a memory stall is on the order of 10's to 100's of cycles.
The cost of a OS-managed context switch is likely 100,000's or millions of cycles.
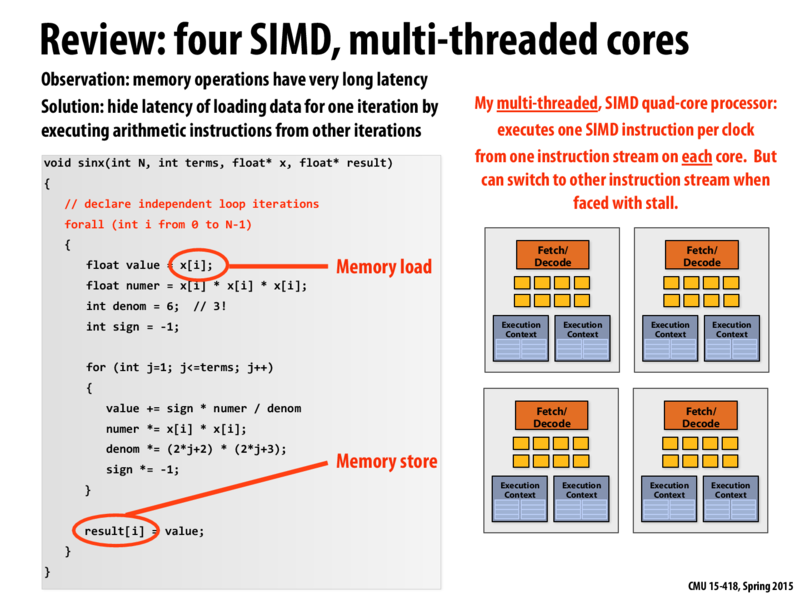
I took an OS course once and learned that the operating system chooses how to schedule threads, and that when one is waiting for memory it's taken off the core and another thread is put in. In this class we have only looked at the hardware of each core choosing which thread to run.
Do these contradict? Or does the OS choose how to fill up the blue boxes in the above diagram, and the core chooses which blue box to run?
@russt17: Exactly! They do not contradict. They are the same idea of using interleaved execution to hide latency, but at different granularities.
The operating system will take thread T1 off the processor and schedule another thread T2 in it's place when it knows T1 is blocked on a very long latency operation such as a disk access. The cost of the OS context switching a thread into an execution context is large -- perhaps 100,000's of cycles. The cost of an OS context switch is way too high for it to be the mechanism to handle stalls due to memory (DRAM) access, which are at most hundreds of cycles. (It's pretty silly to pay 100,000 cycles as a solution to a 100 cycle stall!) Thus, if there is to be context switching to hide memory latency, it must be performed extremely efficiently by the hardware itself. That context switching, to be fast, can't involve much data copying. Thus the processor maintains multiple execution contexts (blue boxes) and chooses which one to run.
@kayvonf: Thanks, that makes a lot of sense!
@kayvonf: Are the 'execution context' blocks in our diagrams implemented in software, hardware or either?
We said on lecture 2, slide 50 that our contexts are stored in the L1 cache of the processor (software threads?), but I'm not sure if this means that we can still support running two simultaneous threads (e.g. hyper-threading). I feel like we'd still need some way to double the read/write bandwidth of the ALU <-> context logic to support this if it is not implemented in hardware.
I think we've come across the notion of 'hardware-implemented' threads before. Does this mean that we can expect there to be two physical register sets for the separate execution contexts?
I'm not entirely sure if the answer to this question matters, but I think it is useful to be able to understand the processor spec sheet here. Under the performance section, it says # threads (which I assumed meant the # of hardware threads available over all of the cores).
This is very important.
The execution context in this diagram referred to the storage provided by the processor to maintain state required to execute a thread. In class we talked about one major example of this state being registers (including stack pointer, program counter, etc.). This storage is a component of the hardware. A processor that supports hardware-multi-threading, such as the made-up processor in the diagram above, will have storage for multiple execution contexts (e.g, 2 sets of registers as shown above).
In the Intel ARK processor link you mentioned, the specs say the chip has four physical cores but can maintain state for up to eight threads. So yes, that means each core has state for two threads (Which, not surprisingly, is exactly like my fake processor above.) Intel Hyper-threading is the external marketing name for their implementation of maintaining state for two threads on each core at once, and then choosing which instructions to run from those two threads on each clock. A more detailed description of Hyper-Threading is on this slide.
On lecture 2, slide 50, the point I was trying to make is that given a fixed amount of storage on a chip, supporting more threads at once necessarily means that the execution contexts of those threads much be smaller. I see how this could be a bit confusing, especially since we haven't talked about GPU architecture yet, so think about it this way:
On most CPUs, all execution contexts are exactly the same size since the architecture precisely defines that an x86 thread has a specific number of registers, etc. (It's part of the architectural abstraction.) Thus, moving from a single-threaded processor to a two-threaded processor means that the chip mean provide twice as much storage to hold the execution contexts of two threads. However on GPUs, the size of an execution context is actually dynamic based on the program being run. The compiler emits a binary that declares how many registers it needs. Then, the GPU uses this number to figure out how many threads it can run at once on a core based on how many execution contexts it can support from a fixed pool of SRAM storage on the processor.
On lecture 2, slide 50 I put "or L1 cache" in parens just to indicate that this idea of partitioning a fixed pool of store into contexts pertains to both the register storage, but also the working set of the program out in memory. For example, imagine you had one thread that had a working set of 16KB of data, and so most of it's data accesses hit in the L1 cache. However, now imagine you run two threads at the same time on a Hyper-Threaded processor, so the combined working set of the two threads is now 32KB. If the L1 cache of the core was only 16KB, then the two thread case would suffer far more cache misses, something that you might have observed on Exercise 1.
Just keep in mind that running multiple threads at the same time is a good thing because it allows for fine-grained latency hiding to reduce stalls. But there's no free lunch, all the resources on the chip are shared among those threads: including the ALUs and on-chip storage resources (whether that be storage for data in the L1 cache, or storage used to maintain execution contexts).
If there are only two execution contexts on a core, the hardware context switch only support two threads? That means if we have more than two threads on a core, we must let OS to do the context switch, which is too costly? In Exercie 1 question E, I found that using 4 threads on a core can completely hide the memory latency although there is no cache hit, with the assumption that the cost of context switch of these four threads on a single core only takes several cycles. So this assumption cannot hold at all? To support hardware context switch between four threads, we need four execution contexts like lecture 2 slide 48?
@kayvonf I forgot to thank you for the awesome explanation. Thanks!
@BigFish I believe the answer 4 threads total with 2 threads per core. Also, the quiz described a processor which was two-way multi-threaded with two hardware contexts. This indicated a few things. Only one thread was running at a time. Each core could run up to two threads without having to load a context from the O.S. The answer to that exercise was 4 threads with 2 threads per core as expected.
This does raise a good question though. Is this an accurate statement?
latency(memory stall) >> latency(O.S. context switch) >> latency(hardware context switch)
I'm guessing that we can consider the O.S. context switch a cache-hit (contexts are likely small enough that they won't get evicted?)
@andymochi It seems that OS context switch should be much higher than memory stall, since we have to store many states. So we cannot hide memory stall using four threads given that we have only 2 execution contexts. However, I believe that if we have 4 execution contexts, and the cache is still 16KB. Although the size of working set is 6KB * 4 = 24KB. We can achieve a speedup even though there is no cache hit, since the CPU is doing computation all the time.
@andimochi: