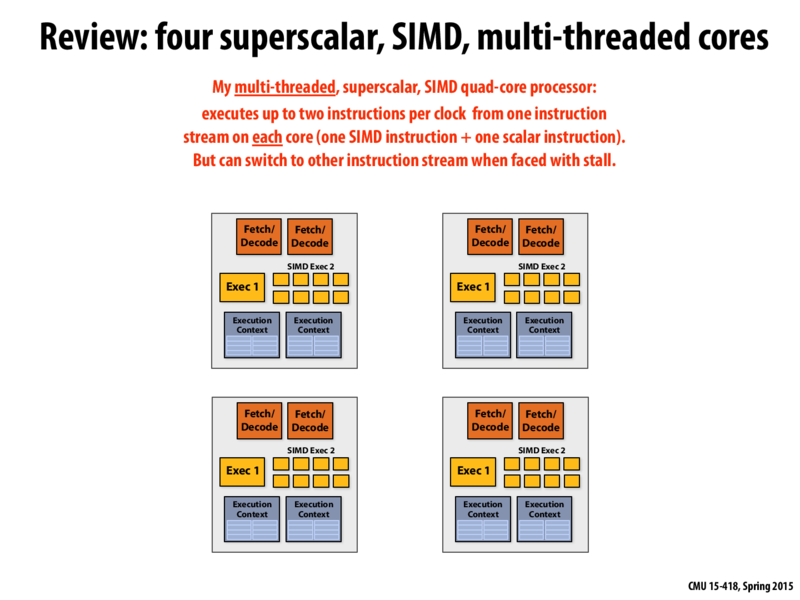
So what is the "Exec 1" box here? Is is a bulky ALU (that would likely handle some special "scalar" computations, as referenced above)?
If it weren't for the heterogeneous mix of ALUs (I'm assuming - I could be wrong depending on the answer to the above), then each large box would be different cores by our previous, basic standard, right? Specifically, each large box has more than one fetch/decode unit, more than one ALU, and more than one execution context. So, were it not for the fact that each core has one "exec 1" unit, for this abstract perspective of boxes of hardware I could consider the large boxes above to contain more than one core.
However, that perspective seems to ignore the important fact that cores can manage the instruction streams they are handed in ways that two separate cores cannot - single cores can made their hardware collaborate to handle instruction streams differently then two cores "chatting" with each other about juggling instructions. If what I'm saying is correct (flip a coin for that), then in the abstract sense we are considering cores, cores are defined by instruction stream abilities, not bundling hardware.
lament
The above is purely speculation.
TA-lixf
First of all, please re-read the third paragraph of your post because some typos are making it a little unclear.
As for your question, "Exec 1" is the scalar ALU briefly discussed above. If I'm not misunderstanding, you are asking why can't one core be split into two cores since it can process two instruction streams?
If the cores are actually like what's depicted here (has no shared logic or memory bus), then you might. Although one might argue that way you lose the freedom to decode any instruction, i.e. the decoder on the scalar core will want to work on non-parallel streams while the SIMD core likes parallel ones. However, in reality it's hard to know what the nature of the streams are without decoding it.
Also, another reason is the two ALUs and decode/fetch units actually share other resources on the core. For example, caches and memory buses and even pipelining and prefetching logics. If you split them, that means you would need to duplicate those as well. So, splitting them has overhead and at some point the gain is not justified anymore.
andymochi
In lecture, Kayvon mentioned that multi-threaded processors are not common in the mobile processors. Here is a short paper from ARM in 2013 which goes through some of the benchmarks and alternate architectures to multi-threading.
It's a good read for computer architecture noobs like me, though I did have some trouble understanding the tradeoffs of out-of-order execution with multi-threading and what it meant for power consumption.
pmassey
Out of curiosity, is Exec 1 better than any individual ALU in the SIMD Exec 2 collection? What exactly is the advantage of a scalar instruction over using just one of the SIMD ALUs? It seems as though there must be some advantage, as without one having two sets of SIMD ALUs would be better.
parallelfifths
Adding to @pmassey's question, I assume that the logic required to make SIMD execution work is more complicated and probably more power consumptive such that it is much less efficient for core [size? power consumption? ... what are the other tradeoffs?] to be running a scalar instructive stream on only one lane of SIMD execution unit?
Kapteyn
Why are there two fetch/decode units? Is one for SIMD instructions and the other for the scalar instructions?
andymochi
@Kapteyn Yup. The thing to be careful about is knowing that both these fetch/decode units operate on the SAME instruction stream at the same time whenever possible.
I think in some other drawings (like the GPU in later slides), the fetch/decode units are capable fetching from multiple instruction streams.
So what is the "Exec 1" box here? Is is a bulky ALU (that would likely handle some special "scalar" computations, as referenced above)?
If it weren't for the heterogeneous mix of ALUs (I'm assuming - I could be wrong depending on the answer to the above), then each large box would be different cores by our previous, basic standard, right? Specifically, each large box has more than one fetch/decode unit, more than one ALU, and more than one execution context. So, were it not for the fact that each core has one "exec 1" unit, for this abstract perspective of boxes of hardware I could consider the large boxes above to contain more than one core.
However, that perspective seems to ignore the important fact that cores can manage the instruction streams they are handed in ways that two separate cores cannot - single cores can made their hardware collaborate to handle instruction streams differently then two cores "chatting" with each other about juggling instructions. If what I'm saying is correct (flip a coin for that), then in the abstract sense we are considering cores, cores are defined by instruction stream abilities, not bundling hardware.
The above is purely speculation.
First of all, please re-read the third paragraph of your post because some typos are making it a little unclear.
As for your question, "Exec 1" is the scalar ALU briefly discussed above. If I'm not misunderstanding, you are asking why can't one core be split into two cores since it can process two instruction streams?
If the cores are actually like what's depicted here (has no shared logic or memory bus), then you might. Although one might argue that way you lose the freedom to decode any instruction, i.e. the decoder on the scalar core will want to work on non-parallel streams while the SIMD core likes parallel ones. However, in reality it's hard to know what the nature of the streams are without decoding it.
Also, another reason is the two ALUs and decode/fetch units actually share other resources on the core. For example, caches and memory buses and even pipelining and prefetching logics. If you split them, that means you would need to duplicate those as well. So, splitting them has overhead and at some point the gain is not justified anymore.
In lecture, Kayvon mentioned that multi-threaded processors are not common in the mobile processors. Here is a short paper from ARM in 2013 which goes through some of the benchmarks and alternate architectures to multi-threading.
It's a good read for computer architecture noobs like me, though I did have some trouble understanding the tradeoffs of out-of-order execution with multi-threading and what it meant for power consumption.
Out of curiosity, is Exec 1 better than any individual ALU in the SIMD Exec 2 collection? What exactly is the advantage of a scalar instruction over using just one of the SIMD ALUs? It seems as though there must be some advantage, as without one having two sets of SIMD ALUs would be better.
Adding to @pmassey's question, I assume that the logic required to make SIMD execution work is more complicated and probably more power consumptive such that it is much less efficient for core [size? power consumption? ... what are the other tradeoffs?] to be running a scalar instructive stream on only one lane of SIMD execution unit?
Why are there two fetch/decode units? Is one for SIMD instructions and the other for the scalar instructions?
@Kapteyn Yup. The thing to be careful about is knowing that both these fetch/decode units operate on the SAME instruction stream at the same time whenever possible.
I think in some other drawings (like the GPU in later slides), the fetch/decode units are capable fetching from multiple instruction streams.