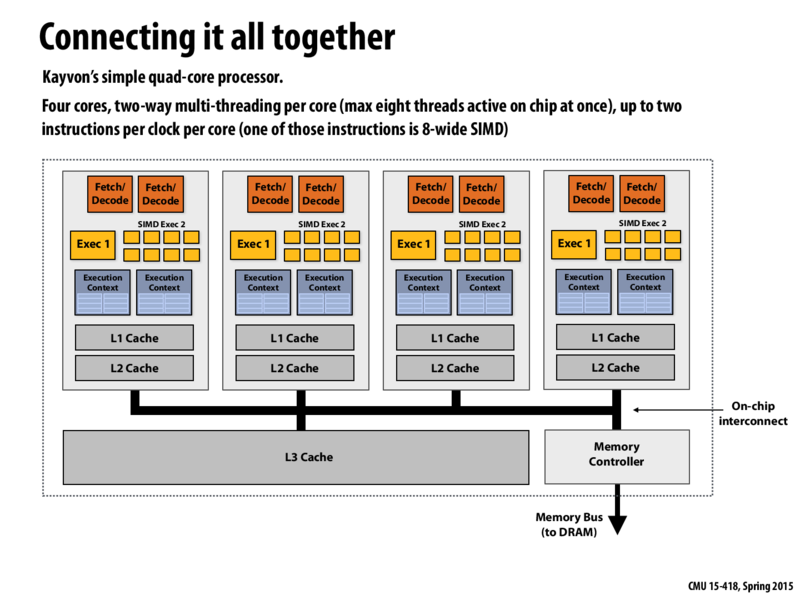
I asked this question in class, but I'm not sure I fully understood. Why is it not a good idea to separate the four SIMD processing units into 2 cores and the scalar processing units into 2 other cores? The logic to decide whether an instruction must be parallelly processed or not can reside at a level above the cores (unlike a GPU+CPU combo where the programmer decides what is run on the GPU). Wouldn't this be easier for the OS to manage?
bwf
@Vivek Scheduling becomes difficult if we separate our CPU into 2 types. Unless we complicate matters for the programmer, and have them explicitly say how to run things, the OS has to determine what kind of code would run better on the different parts of the processor. "Is this code better on our SIMD cores or our scaler cores?" is a difficult problem to handle when scheduling.
During lecture Kayvon mentioned that we currently a scheduling issue like this when determining whether to run something on the CPU or GPU, though I'm not too familiar with how that works. Anyone have some knowledge on that subject?
TA-lixf
@bwf, Good question. I'm no expert in this but here are some references I found online.
From my understanding, the scheduling can be dynamically adjusted by the OS settings. Depending what you do with your rig, you could schedule things on the GPU explicitly. e.g. scientific computing. Otherwise, specific applications will request to be scheduled on the GPU. e.g. video games. Here's a paper on CPU-GPU collaborative computing: http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=4624866
Also, an interesting bottleneck is the communication between CPU and GPU. Currently it's done with PCIe bus, which is pretty fast but check this (NVLink) out: http://www.nvidia.com/object/nvlink.html
parallelfifths
@Vivek, to add to @bwf's answer, I assume that the answer relates back to one of Kayvon's responses on slide 9 of this lecture. In the case where the programmer wouldn't explicitly declare whether to run an instruction on a SIMD-capable core or a scalar processing core, the OS would need to dynamically decide which core to run the instruction on. Kayvon said that the cost of a hardware context switch is practically 0 clock cycles, where as the cost of an OS-level context switch can be 100,000+ cycles.
I asked this question in class, but I'm not sure I fully understood. Why is it not a good idea to separate the four SIMD processing units into 2 cores and the scalar processing units into 2 other cores? The logic to decide whether an instruction must be parallelly processed or not can reside at a level above the cores (unlike a GPU+CPU combo where the programmer decides what is run on the GPU). Wouldn't this be easier for the OS to manage?
@Vivek Scheduling becomes difficult if we separate our CPU into 2 types. Unless we complicate matters for the programmer, and have them explicitly say how to run things, the OS has to determine what kind of code would run better on the different parts of the processor. "Is this code better on our SIMD cores or our scaler cores?" is a difficult problem to handle when scheduling.
During lecture Kayvon mentioned that we currently a scheduling issue like this when determining whether to run something on the CPU or GPU, though I'm not too familiar with how that works. Anyone have some knowledge on that subject?
@bwf, Good question. I'm no expert in this but here are some references I found online.
From my understanding, the scheduling can be dynamically adjusted by the OS settings. Depending what you do with your rig, you could schedule things on the GPU explicitly. e.g. scientific computing. Otherwise, specific applications will request to be scheduled on the GPU. e.g. video games. Here's a paper on CPU-GPU collaborative computing: http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=4624866
Also, an interesting bottleneck is the communication between CPU and GPU. Currently it's done with PCIe bus, which is pretty fast but check this (NVLink) out: http://www.nvidia.com/object/nvlink.html
@Vivek, to add to @bwf's answer, I assume that the answer relates back to one of Kayvon's responses on slide 9 of this lecture. In the case where the programmer wouldn't explicitly declare whether to run an instruction on a SIMD-capable core or a scalar processing core, the OS would need to dynamically decide which core to run the instruction on. Kayvon said that the cost of a hardware context switch is practically 0 clock cycles, where as the cost of an OS-level context switch can be 100,000+ cycles.