





One intuitive way to think of why this formula holds is that the fraction of work done sequentially is (1-f) (the fraction that is not parallelizable) plus f/n (each processor's share of the parallelizable work). The inverse of this gives the speedup, 1/((1-f) + f/n).
This comment was marked helpful 0 times.


This new representation of Amdahl's law takes into account heterogeneous parallelism. Comparing back to the earlier formula, we now have to consider systems which may have cores with varying resources per core.
Also on a tangent, I found this article pretty cool - http://developer.amd.com/resources/heterogeneous-computing/what-is-heterogeneous-computing/
This comment was marked helpful 0 times.

So the unit of perf(r) is time if I am thinking correctly right?
This comment was marked helpful 0 times.

@shabnam: perf(r) is a rate. If a processing core with r units of resources can process work at a rate of 1 (e.g., one instruction per clock). Then by this very, very simple model a core with 'r' units of resources can process sqrt(r) instructions per clock.
Throughout the lecture I've assumed perf(r) = 1. And lets assume a program is a total of 1 units of work. Then the numerator in the equation above work/workrate = 1/1 = 1 = time to complete job sequentially with a core where r=1. The denominator is (sequential_work / sequential_work_rate + parallel_work / parallel_work_rate) = the time to complete the job on the heterogeneous processor.
This comment was marked helpful 0 times.

Since perf(r) is modeled as sqrt(r), if we total the performance with a fix number of resources, we would get more performance by giving each core a single unit with r performance, whereas combining resources in a single core gives sublinear performance, and thus less than r performance.
This comment was marked helpful 0 times.


It is important to note in these diagrams that perf(r) is modeled as sqrt(r). The single 256 resource unit core on the right really only achieves performance 16x that of the 256 single resource unit cores on the left. The total computing power of the 256 single resource unit cores is thus 16x higher than that of the single 256 resource unit core, however performance is limited by the parallelizability of the programs being modeled.
This comment was marked helpful 0 times.

The diagrams in this slide show the change of performance in terms of speedup, not latency. It is incorrect to say with a higher $r$, the red line drops because speedup is measured with respect to the speed of one single core. The absolute speed here is related to both speedup and single-core speed. Note that a higher $r$ actually improves the speed of one core. Thus, it may not be very obvious without a derivation (I hope I made it correct).
Let $perf(r)$ defined as $ \sqrt{r} $.
$$ speedup(f, n, r) = \frac{1}{\frac{1 - f}{\sqrt{r}} + \frac{f\sqrt{r}}{n}}. $$
Thus, the absolute speed could be expressed as
$$ speed(f, n, r) = speedup(f, n, r) \times perf(r) = \frac{nr}{(1 - f)n + fr}. $$
Take derivative in terms of $r$.
$$ speed(f, n, r)' = \frac{n^2(1 - f)}{((1 - f)n + fr)^2} > 0. $$
Note that this derivative is greater than zero but decreasing when $r$ increases. Therefore, we get better speed with larger $r$, but the difference between multiple threads and a single thread becomes less remarkable.
This comment was marked helpful 0 times.

You would expect relative speedup to increase with fewer, "fatter" cores when less of the code is parallelizable (blue line) because the resources can then be put toward things like dedicated instruction hardware and branch predictors that enhance single-threaded performance.
This comment was marked helpful 0 times.


Just to be sure I'm understanding this right, in the formula on this slide, r refers to the resources used to make the one "fat" core with r=4, correct?
Then, in the (perf(r) + (n-r)) term, perf(r) would be the performance of the one big core, or perf(4). And (n-r) would represent the 12 cores with r=1.
Can someone verify this?
This comment was marked helpful 0 times.

@aew that looks correct to me
However, considering the difficulties in using a heterogeneous system (as described in later slides), would this formula be a fair approximation for how performance actually scales in real machines? It seems to be a little too optimistic...
This comment was marked helpful 0 times.
@aew: correct.
@eatnow: perf(r) = sqrt(r) is a very crude approximation to reality that was used to make the graphs. The key point is that it is sublinear. If it was the case that perf(r) = r, then there would be little need for parallel processing as we'd use all our resources to linearly improve single-threaded performance, and not make software developers tackle the challenges of parallel programming.
This comment was marked helpful 0 times.
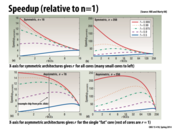
Just curious, how were these data collected/measured?
This comment was marked helpful 0 times.

Well, here's the paper these graphs are from. I don't think they were generated from actual data, but from the Matlab code linked on this page. There's also an interactive speedup graph generator there, which is pretty neat.
This comment was marked helpful 0 times.

So I remember that a comment was made in class and I think it was actually very important to bring up again on the slides. When looking at these graphs, when thinking about the actual numbers, that x-axes on the graphs represent different things. On the top row, rBCEs=4 means that there are 4 cores with 4 units of resources. However, on the bottom row, rBCEs=4 means that the biggest core has 4 units of resources but there are 12 other cores with just a single resource. So, it is true that the speedup seems to be a lot higher in the bottom row pretty much across the board, but the number of processors being used is so different. In fact for rBCEs=4, we just showed that there are 3 times more cores in the bottom row. Thus, take this graph with a grain of salt. There a lot of ways to analyze this graph, but I think the key piece of information here is simply that there something to gain by having heterogeneous cores.
This comment was marked helpful 0 times.


Question: If we were to design a scheduling algorithm for heterogeneous processors, then presumably the programmer would have to specify that specific threads would require "fatter" or "thinner" cores. How would this translate to pieces of code running on devices with different hardwares (i.e. different numbers of fat/thin cores and various fixed function units)?
This comment was marked helpful 0 times.

That's not necessarily true. If we had a pool of worker threads that each took a task from some shared queue, it's plausible we could know the size of the task without the programmer's intervention. If the task had to read a file then we could estimate the time for the task by the size of the file, or if it had to compute something in a loop, then the runtime would probably be proportional to the number of loop iterations. Then the scheduling algorithms would be able to use this information to make smarter decisions. Also, scheduling algorithms don't have to know the size of jobs. These are called "oblivious" scheduling algorithms. Examples include First-Come-First-Served, Random, Processor Sharing, and Foreground-Background scheduling. This last one estimates the size of a job not based on any information about the job itself, but only on how long the job has been running so far.
This comment was marked helpful 0 times.

One example of a processor that could benefit from heterogeneous resources is one that is made to run physics simulations, such as those for particle physics. Some parts may parallelize well because many particles may be affected at one time, but sometimes there might be a chain reaction where only a few particles are being affected at each time step, which would not parallelize well. Also, sometimes certain particles may require more computation than others to determine their new state, whereas other times all particles are effected equally, which effects the usefulness of SIMD execution. For the last point, at the beginning the particles next to each other will probably be in memory next to each other, which makes data access predictable when a force is acting on one area of the particles. However, after they are scattered, there is no guarantee that the particles in one area of the simulation will be near each other in memory, causing unpredictable data access.
This comment was marked helpful 0 times.

Heterogenous computing is more than just using a mixture of CPU's and GPU's to solve a problem. Currently, CPU's and GPU's don't mix too well together, as they tend to operate in different environments entirely.
Communication necessitates expensive memory copying between the CPU and the GPU, which limits the usefulness of the GPU (it is only beneficial when the cost workload is significantly higher than the cost of communication, as we saw when implementing a CUDA-based scan in assignment 2; for relatively smaller values of n, the serial version was actually substantially faster than the CUDA version).
This comment was marked helpful 0 times.

To summarize, the motivation for a heterogenous mixture of resources is because most real-world application have complicated and changing work loads. Having heterogeneous resources ensures we have the right tool for the job when the situation changes.
This comment was marked helpful 0 times.
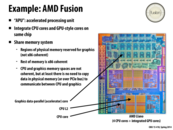
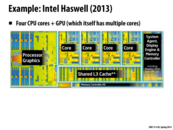

By having an on chip GPU, this chip could run the graphics necessary for many tasks on chip. This would save the power of running the GPU, and the time of transferring data across the PCIe bus to the GPU memory. In a pure computing application, this on chip GPU turns this chip into a heterogeneous processor. It would allow trivially parallelizable code to be run on the GPU (many small cores), and sequential code to be run on the main processing cores.
This comment was marked helpful 0 times.
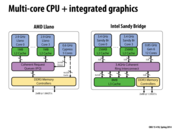
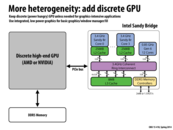
The integrated and discrete GPU are used for different workload cases. Discrete for graphics intensive applications while integrated used for basic graphics applications. This can save power and be more efficient when running things like window manager since we avoid the cost of copying through the PCIe bus and the high power consumption of the discrete GPU
This comment was marked helpful 0 times.


For those who use Macbook Pro 2011 and and other Macbook with multiple GPUs, the following article will be useful when programming in openGL. It tells openGL developers all they need to know in order to get their openGL code to render properly on multiple GPUs:
Rendering openGL properly with multiple GPUS
This comment was marked helpful 0 times.






Watt does the W in MFLOPS/W mean?
This comment was marked helpful 3 times.
Mega flops per watt
...Wait, watt do you mean by that question?
This comment was marked helpful 4 times.

Note that the sites here are much much smaller than the sites from the previous slides. While these machines are extremely energy efficient, the total power they consume are many magnitudes less than the most powerful machines. Most of the green machines are under 100 kW while the most powerful machines range from 2000 kW to near 18000 kW.
This comment was marked helpful 0 times.

One thing pointed out in lecture I thought was kinda interesting is that all of these computers use the NVIDIA K20 GPU, mostly because it's impossible to get this low level of performance per watt with really large CPUs. The white paper here gives a bit of an overview of the technologies added to the K20 in addition to some performance comparisons with other hardware.
This comment was marked helpful 0 times.



An example of the limits of chip power consumption can be seen in speech processing software in mobile devices. Speech processing software such as Siri use quite a bit of the battery life of the mobile device because it must constantly process the speech around it and process that speech for keywords to activate the device. That is why it is imperative that the speech processing software on the chip is as efficient as possible so as to reduce power consumption of the chip. It is a very common occurrence where Siri has dramatically reduced the battery life of a mobile device.
This comment was marked helpful 0 times.

The commands that are dictated to Siri are processed locally and on the cloud. If the command require the usage of things on the phone, then it just performs it. Otherwise the information is sent to the server for further processing.
source: http://www.zdnet.com/blog/btl/how-apples-siri-really-works/62461
This comment was marked helpful 1 times.

power analysis of phones are complicated as the same code can have different effects across different devices. Apps that behave well individually can have problems when run in parallel. There are also non-technical challenges. For example market study suggested a large amount of power consumed by apps were used in powering 3rd party ads.
source: http://sites.ieee.org/isgt/files/2013/03/Stavrou6C.pdf
This comment was marked helpful 0 times.


From class we learned that ASICs were fixed function units that are extremely energy efficient and high performance in regard to the function that they are designed to run. However, I did some more research about why the performance of the FPGA unit is still much better than the CPU, but an order of magnitude worse than the ASIC unit.
FPGA are Field-Programmable Gate Arrays, which essentially are programmable hardware devices. They are optimal in design situations where there is a limited volume of production or in which rapid prototyping is necessary. Often ASIC units require considerable investment to manufacture and design so FPGAs are good for testing environment.
FPGAs consume more power because they tend to have a lower gate utilization as compared to ASIC units. They also rely on memory technology and lookup tables, which don’t offer particularly efficient power or speed. There are many power control methods on ASIC chips that don't work on FPGAs.
Even though both the FPGA and ASIC units are synthesized hardware execution units, the FPGA sacrifices energy efficiency and performance for flexibility and decreased cost of design.
However, the FPGA is still hardware. It has an amazing internal bandwidth and a potential for parallelism and data flow that does not directly map to a CPU implementation.
This comment was marked helpful 1 times.

A technique commonly used to save power (but highly discouraged in CMU's undergrad RTL design courses) is clock gating. The clock tree in FPGAs are fixed, unlike in ASICs where it is specially built, which enables this technique to be used.
This comment was marked helpful 0 times.


The figure originates from this article.
The authors have pointed out an embedded processor spends only little portion of its energy on the actual computation. The figure shows that the processor spends most of its energy on instruction and data supply. 70% of the energy is consumed to supply instruction (42%) and data (28%).
This comment was marked helpful 0 times.

I understand why the code needs to be compute-bound for speedup to occur, but why is floating-point math a problem? Wouldn't that make it more computation intensive than integer math and thus more able to be sped up by parallelism?
This comment was marked helpful 0 times.

I believe the restriction on floating-point math is due to the fact that processing floating point arithmetic is difficult and therefore, the performance of the ASIC would not reach the ~100x or greater improvement in perf/watt.
Quoting this page,
Floating point operators generally have dramatically increased logic utilization and power consumption, combined with lower clock speed, longer pipelines, and reduced throughput capabilities when compared to integer or fixed point.
This comment was marked helpful 0 times.

I remember when I was considering a Moto X, I was confused by that always-listening feature. First, I figured it would kill the battery, plus it raises interesting concerns for a phone to constantly be processing speech. This solution makes much more sense. Follow up questions, for fun and (not) profit.
- I read that the Moto X can be trained to your voice. (Actually, they said that it's not responsive unless you say the keywords in the exact way you trained it, which fits with the fact that they use an ASIC for detection.) But if ASICs are hardware-based, how can they be "trained" that way?
- Does using an ASIC mean that it's like a clapper switch of the old days, just with a little fancier functionality? Then that seems to sidestep any privacy concerns.
- Challenge: Say you were a journalist tasked with explaining to those who aren't techno-literate why they shouldn't shun friends who own a Moto X for fear of spying and stuff. (Assuming the answer to question 2 above is yes.) You have 100 words.
This comment was marked helpful 0 times.

- ASICs are hardware-based, but that doesn't mean they are just hardware (we could say the same for phones or laptops - they are hardware-based as well). They can be reprogrammable and flexible to an extent as well. System-on-chips are actually considered ASICs.
- ASICs can get pretty fancy. In regards to privacy concerns, I think it would depend on how the ASIC is implemented/its intention of use. If it only transmits information to the CPU when the spoken phrase matches the one set by the user, I don't really see any issues with privacy. But they can definitely be designed to be something worrisome (maybe like storing voice and sending it to the CPU whenever the user does something to engage the CPU).
- The 'always listening' feature of the Moto X is like a machine (the ASIC listening) that only comes to notify you (the CPU) if it hears something you told it to listen to (the phrase you set). It has no memory and doesn't tell you anything other than the fact that it heard the phrase it's supposed to listen to.
I think the Snapdragon 800 has a dedicated chip to listen and process audio without touching the CPU. Here's another set of chips that have the same functionality. The site talks a bit more about hardware and background.
This comment was marked helpful 0 times.
Apple also includes the M7 coprocessor in order to collect data from the sensors, including while the phone is asleep, so that it can have data available to applications when the phone wakes up again without using the full amount of power (and battery) needed to run the full processor.
This comment was marked helpful 0 times.
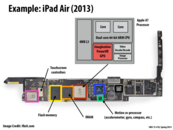

This remind me of an article talking about the performance of Iphone and Android processors. Actually, they are not comparable, because Apple A7 is two big processors with a lot of recourses. But Android CPU is usually four or eight small processors, it's unfair to compare them just according to their number of processors or absolute performance.
This comment was marked helpful 0 times.

Speaking of Android, I looked up what chip is used on a Galaxy Tab 3, and it was Intel Atom Z2560 (http://ark.intel.com/products/70101/Intel-Atom-Processor-Z2560-1MB-Cache-1_60-GHz). However, although this chip has integrated GPU, it doesn't seem to have dedicated video encode/decode or an image processor. Does anyone know why that might be? It seems like a good idea to have them on mobile devices. Does it have anything to do with software video decoding?
This comment was marked helpful 0 times.

The Intel Atom Z2560 has a PowerVR GPU in it. The PowerVR GPU carries the video decoders.
This comment was marked helpful 0 times.




Optimization for certain work seems to be the reason for the relative high speed in camera.
This comment was marked helpful 0 times.

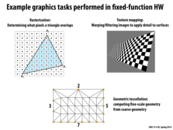




Here the idea being conveyed is that chip designers always tend to over-provision and be conservative when developing fixed-function components.
Here for ex:If they had under-provisioned the rasterizer by giving it 1% rather than the 1.2% required by it, then assuming it ran at 100% when it was correctly provisioned it will be running at around 83.3%(100/1.2) on under-provisioning.
Now if all the other components depended on these then all of them would be slowed down proportionally and hence one single under-provisioned component can slow down the entire chip. So the usual practice is to over-provision which might diminish a few advantages of the fixed functionality device.
This comment was marked helpful 0 times.
Is it possible for the software to detect when hardware rasterization is not enough (and is the bottleneck), and so have computation "spill over" to the general purpose cores?
This comment was marked helpful 0 times.

I wouldn't be surprised if that was done in hardware, if at all. As far as I know, GPUs offer little control to the programmer over which chips are used.
This comment was marked helpful 0 times.


http://developer.amd.com/resources/heterogeneous-computing/what-is-heterogeneous-system-architecture-hsa/ So the challenges of homogeneity and heterogeneity in system architecture are radically different. From my understanding, CPU's are better suited to running the operating system and dealing with memory, but GPU's are better suited towards parallelism and large data sets/computation. This is caused mostly by the differences in architectures of the two different units. From http://superuser.com/questions/308771/why-are-we-still-using-cpus-instead-of-gpus, GPU's are Turing complete and can thus run any computer algorithm; thus, one would be inclined to believe that GPU's can run algorithms that aren't particularly targeted towards GPU usage.
I imagine that if a specific set of the silicon dye is devoted to something, say rasterization, then even if we end up with not enough computing power of that particular unit, we can give the rest to other units which are not necessarily as suited to run those algorithms (such as the GPU or the CPU if it is idle). In this sense, we can still maintain the high amount of benefit from specialization, with a little bit of lost time from the other units trying to run the algorithms (but still getting it done in parallel).
This comment was marked helpful 0 times.

The PetaBricks language helps with the automatic generation of architecture-specific implementations, which reduces the portability nightmare while giving good performance. Programmers offer the compiler choices in how a program might be implemented, allowing it to optimize for the appropriate architecture.
This comment was marked helpful 1 times.
@pwei: GPUs are good with large datasets, up to a point. CPUs of today's era have far more memory available (extremely high-end GPUs can have up to 6 GB of memory, whereas a common laptop has around 8 GB). Although pulling from disk is a nightmare, CPUs can still do it, whereas GPUs are limited, in many cases, to no more than the memory available. The bandwidth is obviously far superior on a GPU, but if you have an extremely large dataset, it becomes infeasible to use them.
This comment was marked helpful 0 times.

I mentioned on Piazza that some people were encouraging users not to kill the applications on their phone, as that evicts them from RAM and causes more battery to be used when re-opening that app (especially if it's a frequently used/slow-to-load app, like Chrome). Are there numbers for the energy to load data from disk? And where are these ballpark figures from?
This comment was marked helpful 0 times.


I was debating something after reading the points on this slide -- we want to compute less, and we want more specialized computation. Why not outsource the majority of our computation to web-servers with specialized hardware? We would get all the benefits of specialized computation, without the expensive space and ASIC cost!
Except not. Remember how accessing memory is super expensive? Well transmitting information to a cell tower (and receiving a result later) is wayyyyy more expensive, especially in terms of power consumption. So this outsourcing is really only beneficial if the amount of computation required vastly dwarfs the dataset that needs to be transmitted from a mobile device.
This comment was marked helpful 0 times.

@smklein, that's an interesting point. I believe if the network bandwidth is high and latency is low, then maybe our PC/Mac would be only a screen, some basic OS control and network stuff. Also, the game Titanfall use Microsoft cloud computing to do some non-player activity to let the local computers on players to focus on graphical performance. I think this is one big trend.
This comment was marked helpful 0 times.

How do hardwares such as FPGAs and ASICs save energy and allow good performance at the same time?
This comment was marked helpful 0 times.

@jinghuan - Fixed-function hardware sacrifices generality to achieve faster execution per available resource. What a general-purpose CPU can achieve with a given budget (transistors, power, etc) will be much lower than what an ASIC with the same budget would be able to achieve because the ASIC does one task only. This is how ASICs save energy while having high performance; they exchange the general-purpose circuity of a modern CPU for a fixed-function circuit which only does one specific task. As I understand it, FPGAs also have very good performance but aren't quite as fast as ASICs. FPGAs can be repeatedly burned with arbitrary logic, but the resulting circuitry will be slower than the "pure" transistor-level logic that makes up an ASIC.
@smklein - Neat idea, reminds me of how the Opera Mini browser handled javascript. They proxied your traffic through their servers to do some of the heavy-lifting server-side, and sent back to your device a static version of the page.
This comment was marked helpful 1 times.


Some arguments from the lecture for each processor:
Processor A: Better if we are optimizing for running single-threaded applications or applications that don't make good use of parallelism on many cores. This processor would be better if we were, say, optimizing for running Microsoft Word.
Processor B: Processor B has more processing power overall. It might be better if we are running a lot of different threads and don't care about single-threaded performance, or if we want to demonstrate good speedup on a program that takes advantage of many cores.
This comment was marked helpful 0 times.
An interesting note is that modern CPUs support some sort of Turbo. When only a few cores are used (say, 1 in a quad core cpu), the single core overclocks itself and the other cores to go sleep, so overall the entire processor still fits in the same thermal envelope. The CPU essentially takes resources (in this case, power) from one core and donates it to another core to form a fat core.
This comment was marked helpful 1 times.