














To summarize, here are the definitions of these concepts.
Deadlock "is a state where a system has outstanding operations to complete, but no operation can make progress" (slide). This is generally unrecoverable.
Livelock "is a state where a system is executing many operations, but no thread is making meaningful progress" (slide). This is generally unrecoverable without outside intervention.
Starvation "is a state where a system is making overall progress, but some processes make no progress" (slide). This may be recoverable, but is less-than-ideal.
This comment was marked helpful 1 times.


According to 15-410, deadlock has four requirements:
Mutual Exclusion: Some resource/lock is allocated to one process/thread at a time.
Hold & Wait: Processes/threads must have the potential to hold a lock while waiting for more.
No Preemption: No one is able to "give up" a resource.
Circular Wait: A cycle can be defined in the resource graph (ex, process 0 needs something from process 2, who needs something ... who needs something from process 0).
Deadlock MUST HAVE ALL FOUR REQUIREMENTS to occur.
This comment was marked helpful 1 times.

Absolutely. How do those four conditions manifest in this intersection example?
This comment was marked helpful 0 times.

Mutual Exclusion: Our critical section is space on the road. A space of road can only hold one car at a time.
Hold & Wait: A car "holds" a resource by being on the road. It "waits" for the road it wants to travel on by simply stopping the car until the space is available.
No Preemption: Assuming this intersection deadlock situation only allows cars to move forward, cars cannot give up the road they are on because they have nowhere else to drive to.
Circular Wait: Each car needs the road in front of it to drive forward. Thus, the green cars need the resource occupied by the yellow cars, while the yellow cars need the resources occupied by the green cars, which forms a cycle.
We can note that since the 3rd requirement doesn't hold in real life (since cars can move in reverse), we don't have true deadlock in this situation.
This comment was marked helpful 0 times.

We can divide the intersection into four quarters of space, and treat each of those as a resource. Then,
- Mutual Exclusion : Each unit of road space in the intersection is being held by a car, and each of those units can be held by at most one car at a time.
- Hold & Wait : A car holds a unit of road space, and can choose to remain there (assuming the civility of other road users :D), while waiting for the next road space it intends to consume to free up. In this situation, the green cars are holding a quarter of the intersection each, and each is waiting for a quarter being held by the yellow cars, and vice versa.
- No pre-emption : This one is slightly confusing; each car is in fact able to back-up and so "give up" its resource. It makes more sense if you think of it in terms of a supervisor/operating system; no pre-emption on Wikipedia is defined as 'The operating system must not de-allocate resources once they have been allocated; they must be released by the holding process voluntarily'. In this example, I suppose you could say that there's no supervising traffic light that'll force the green cars to back up and allow the yellow cars to pass. Each car has complete, individual control over whether or not to give up its resource.
- Circular wait : Each car is waiting for the road-space being held by its counter-clockwise adjacent neighbor.
This comment was marked helpful 0 times.



This is deadlock because neither animal is making any progress. The frog is holding the other animal's throat so it can't eat the the frog. The frog cannot really do anything because it refuses to let go of the animal's throat and therefore, can't move either.
This comment was marked helpful 0 times.

@ycp Agreed, although it seems to me that there is no mutual exclusive resources here...
This comment was marked helpful 0 times.

@analysiser not dying seems like a decent candidate, assuming the frog is out for revenge.
This comment was marked helpful 0 times.

It seems to me that the frogs are winning in both situations.
This comment was marked helpful 0 times.

I think the first example can also be interpreted as starvation, as I agree with iamk_d__g that the frog is going to be the winner here. Assuming the frog can still breathe (through its skin), the resource in contention here is air. However, the frog is preventing the stork from getting any air by blocking its breathing passages. In this case the frog will eventually let go or the stork will suffocate, and the starvation will end. Still seems like a bit of a stretch -- maybe we're looking into this a bit too much =D.
This comment was marked helpful 0 times.


Another example of deadlock happens with mutexes in a multi-threaded program. Say I have two variables, x and y, which are both locked so that only one thread can modify them at a time. There are two different operations: x = x + y; and y = y + x. If two threads enter these different sections at the same time, one thread will acquire the mutex for x and the other will acquire the mutex for y, but neither will be able to perform the operation because both mutexes are needed in each case.
This comment was marked helpful 0 times.

I was thinking on ways to avoid a deadlock here. Here are some:
- Make the threads acquire the locks in the same order (a thread should first acquire the lock for x and then the one for y)
- Have a thread acquire both locks, or immediatly release the first if it fails to get the second, then try again (although I think this can cause a livelock)
This comment was marked helpful 0 times.

If you want to look at some of the ways to deal with deadlocks, you should take a look at 2 phase locking: http://en.wikipedia.org/wiki/Two-phase_locking
It's used in many databases to avoid deadlocks. Pretty much each transaction (unit of work) is divided into two phases, a phase during which it can only acquire locks and a phase during which it can only unlock locks. If all transactions follow 2 phase locking, then you can assure that all schedules are serializable.
This comment was marked helpful 0 times.
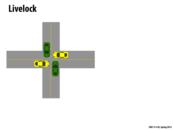
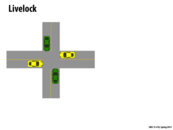
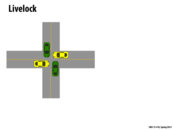


One very good intuitive example for this concept that was mentioned in class was the situation where two people bump into each other in a hallway, and then move back and forth in the same directions as they try to pass each other. In this situation, they are both still trying to do work (move past each other), but making no progress.
This comment was marked helpful 1 times.

So I'm curious, if a situation that would have cause a livelock to occur did not have a backing off mechanism, then wouldn't a deadlock occur instead? Thus would if be fair to say that deadlocks are a subset of livelocks?
This comment was marked helpful 0 times.

Livelocks often occur because there is a mechanism for recovering from deadlock that is repeatedly triggered, so the removal of the mechanism would cause deadlock to occur. However, by definition, you wouldn't be able to say that deadlocks are a subset of livelocks. Livelocks can be considered a special case of starvation though, I think.
This comment was marked helpful 0 times.

On the next slide it says starvation is not usually a permanent state. It seems that in general livelock is also not necessarily a permanent state (you could get lucky and eventually one of the restarts will be timed correctly to successfully proceed). On the other hand, if you somehow have restarting but the livelock can never be avoided even with luck (e.g., if your program has no branch that would not deadlock), then it doesn't seem to meaningful to distinguish between livelock and deadlock since the restarts do nothing. So I guess it seems like you could classify livelock as either starvation or (equivalent to) deadlock.
This comment was marked helpful 0 times.

As stated above, livelock occurs when there is a mechanism for recovering from deadlock that is repeatedly triggered, so if 2 people are in a corridor, they both try to get out of each other's way ensuring they are still stuck. The way to recover from livelock therefore is to ensure that only one process (chosen randomly or priority) tries to recover from deadlock so that the processes can proceed. In our analogy, only one person would try to get out of the other person's way, ensuring that both people can proceed.
This comment was marked helpful 0 times.

To rephrase what's been said above, livelock occurs when threads continue to change their states without making overall forward progress. Therefore it occurs in one of two cases: when threads have the ability to undo their computation, and when they can undo each other's computation. The former happens mainly in optimistic algorithms (instead of locking, try to do something and then undo it if there was a conflict), and the latter in deadlock avoidance (kill another thread if it interferes with you, or a set of threads if they're in a deadlock). Livelock looks exactly like deadlock to users, but in some ways it's even worse than deadlock, because livelocked threads are still consuming the computer's resources while deadlocked ones aren't. It seems strange to me to classify livelock as a subset of starvation since in starvation usually something is making progress and in livelock nothing is; I'm not sure I understand the distinction there.
This comment was marked helpful 0 times.

I can see it as a subset of starvation in the sense that they're both situations where the computer is constantly doing work, but the desired result is not occurring in terms of completed processes.
How would a program detect livelock? It seems easy for a computer to detect deadlock occurring since nothing is progressing, but automatically sensing livelock would be a much harder problem.
This comment was marked helpful 0 times.
@asinha: one "random" choice that could help them get unstuck (eventually) could be chance in a concurrent system. At some point, one person may switch faster than the other and find his way through. Obviously, we'd prefer not to have to rely on chance, though, so it's better to explicitly use one of the fixes you mentioned.
@mchoquet: I think the idea behind people saying livelock is a subset of starvation is that in starvation some processes can make no progress, whereas in livelock all processes can make no progress. By this definition, livelock could be an instance of starvation (all ==> some). I did notice that the next slide says that in starvation some process is making progress, which would then make them mutually exclusive. I think it's more useful to be able to generalize before looking at the specific differences in classification, though.
This comment was marked helpful 0 times.
@retterermoore: that's why formal reasoning about your code is better than testing (when possible). Livelock should be easily detectable through some form of verification. Then, rather than "detecting" livelock when it happens, you could prevent it.
This comment was marked helpful 0 times.

@retterermoore @kleino: it might not actually be possible to formally determine whether your code can get stuck in livelock - the problem seems to be undecidable: see http://www.cs.utexas.edu/~gouda/papers/conference/cp58-whole.pdf
There might not be a single way to detect livelock in a system being executed, but if something is progressing through the same cycle of states repeatedly in an unusual way that's one indicator of possible livelock.
This comment was marked helpful 0 times.
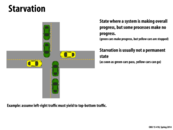

From my understanding, if some processes make absolutely no progress, it's starvation. If processes can still make progress but very limited compared to some other processes, it is a fairness issue but not starvation.
This comment was marked helpful 0 times.

According to Wikipedia, this is incorrect---starvation is characterized by a "severe deficiency in caloric energy, nutrient, and vitamin intake."
(but actually Wikipedia agrees with you)
This comment was marked helpful 5 times.

Starvation is usually caused by schedule policies with priority concept. If a process with higher priority never blocks, other processes with lower priority will rarely get resources.
Another interesting example I learned from Wikipedia: Suppose Priority(process3) > Priority(process2) > Priority(process1) and process3 has dependency on process1. If process2 holds the resource for a long time, process3 will never move forward even though it has higher priority, as it cannot get results of process1.
This comment was marked helpful 0 times.

@chaihf I'm a bit confused by your example. The way I understand it, process1 and process3 are being starved while only process2 is progressing, but I would think that process1 would be able to run to completion once process2 releases the resource meaning process3 will also be able to move forward eventually. If you could give a link to the example, that'd be great.
This comment was marked helpful 0 times.

A special case of starvation is write-starvation in a system with a readers-writers lock that gives readers priority over writers at all times. This lock ensures that multiple readers can read a resource at the same time, but only one writer can write to the resource at a time. In this case, if there is a steady stream of readers and a writer is waiting to acquire the lock, then the writer will wait forever (or at least until the stream of readers dries up), which illustrates the principle of starvation.
This comment was marked helpful 0 times.

@devs? It is called Priority inversion. The basic idea is High priority process has to wait/block for the low priority process.
This comment was marked helpful 0 times.
@devs: It is called Priority inversion. The basic idea is a high priority process has to wait for/block by a low priority process. This is an important problem for the real-time system.
This comment was marked helpful 0 times.

So, to avoid starvation in this case, we need to have some police or traffic light to guarantee the fairness.
This comment was marked helpful 0 times.

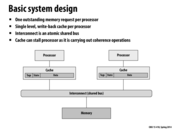

The shared bus here is atomic in terms of transaction. That means only participants of a single transaction can use bus during the transaction. Here is An example from class. A cache asks for data in memory. With an atomic shared bus, this read transaction would occupy the bus until the data is sent back from the memory, even though there may be a period when the bus is actually idle. With a non-atomic bus, other transactions are allowed when the bus is idle.
This comment was marked helpful 1 times.


Question: After sending address and appropriate command on the bus, why does it have to wait for the command to be accepted?
I thought that requesting for bus and getting the bus grant had already guaranteed that the cache controller has the exclusive access to the bus.
This comment was marked helpful 0 times.
Correct, but "wait for command to be accepted" on this slide meant wait for all other processors to acknowledge that they have seen the message.
This comment was marked helpful 0 times.

An important realization here was that steps 3-7 constitute the "shoutout for data" in the snooping based coherence based studied before. Thus these 5 steps need to happen atomically.
This comment was marked helpful 0 times.

For a uniprocessor, aren't step 4 and 7 unnecessary? since the single processor is guaranteed to have exclusive access to the bus, right?
This comment was marked helpful 0 times.

There are other things connected to the bus that also need access (most obviously the memory, but potentially other non-processor devices as well depending on the system) -- a bus with only one device on it wouldn't be very useful!
This comment was marked helpful 0 times.

This problem actually relates to the STARVATION. If the processor keeps receiving priority, the cache can't get chance to do the tag lookups and thus hold up the whole system. On the other hand, if the cache keeps receiving priority and will prevent any further performance continue on the local processor.
This comment was marked helpful 0 times.
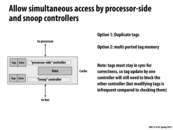

One possible enhancement to reduce the effect of locking-out a controller: updating the processor-side tags only when the cache data is modified rather than immediately when the bus-side tags are updated (see chapter 6.2.1 of the course book for more details)
This comment was marked helpful 0 times.

@azeyara, I'm a little confused by your comment. Could someone please give an example of how this enhancement would work, and when it would help? Thanks!
This comment was marked helpful 0 times.

Assume a cache read miss in MESI: 1 should the memory not respond as long as there's a shared copy in other's cache? 2 if the line is dirty, should it be flushed to memory?
This comment was marked helpful 0 times.

@iamk_d__g I think the answer to both your questions depend on the implementation.
This comment was marked helpful 0 times.
To elaborate on Yuyang's response, I believe it would depend on the type of cache that is in use.
In this case, we have a write-back cache, so on a cache read miss, the data must be fetched from other caches if the line is dirty and memory if it is not.
If this were a write-through cache, then the cache would only need to ask memory. However, if the line were dirty, it could also ask the other caches depending on the trade-off in latency between implementing such a protocol and the benefits of fetching from other caches vs. fetching from memory.
This comment was marked helpful 0 times.


If I recall correctly from lecture, whenever someone issues a "shoutout," the snoop-valid wire is set to high, and as each processor responds, it stops asserting high, and we know that every processor has responded to the shoutout when the snoop-valid wire goes to zero. I think I'm a little confused on what exactly causes the valid wire to be set to high, or who initially sets it. The idea that every processor stops asserting on the wire once it responds to the shoutout indicates to me that we require each processor assert high immediately after the shoutout, and that the valid wire is set to high as a result of each processor asserting high on it. If this is true, what if we have a scenario like the fetch deadlock example toward the end of the lecture, and every processor is issuing a BusRd and waiting for everyone else to respond instead of responding itself? Wouldn't the valid wire never be set to high?
This comment was marked helpful 0 times.

Take the example that Processor A wants to read a variable x; by the MESI protocol it must wait for all other processors to check to see if the data is in their cache lines to determine whether to load to Shared or Exclusive. First Processor A get permission from the controller to shout a BusRd over the bus.
Processor B and Processor C are listening to the bus at this. When they hear the BusRd, they immediately drive a high voltage through the valid wire and begin to process the request (determining whether the data is in the current cache line, whether the line in the cache needs to be flushed or not, etc). As soon as B and C finish their tasks, they immediately assert low on the valid wire.
Now keeping this in mind, we can respond to the situation caused by issuing many commands to read from all processors at the same time. First of all, each processor has to get permission from the bus controller before it will issue a BusRd shout. However, even if a processor is waiting to issue a command, it can still respond to signals that are conveyed across the bus. To quote the slide "To avoid deadlock, processors must be able to service incoming transactions while waiting to issue requests".
Thus even if a processor has a read operation trying to be executed, on a well-designed snooping system this will not lock out the computational capacity of the processor or processor cache. A possible implementation of such a system that uses a separate bus controller and processor control for each cache could be extended to allow processors to wait for permission on a task while simultaneously looking for cache lines. However, I am not sure if a sort of cache ILP is how this is actually implemented.
This comment was marked helpful 6 times.
Question: Is it correct that a wire could only have 1 or 0 as its value?
Does high mean its value is 1?
This comment was marked helpful 0 times.

yes, I think that is the correct way to think about it.
This comment was marked helpful 0 times.

Somehow it seems that there should be more than what is described here: We are relying on the Snoop-valid wire because we cannot tell when every processor has updated the voltage on Shared and Dirty.
But if so, how do we know that every processor has raised the voltage on the Snoop-valid wire in the first place? What if processor A does not set Snoop-valid to high in time, and the rest of the processors do their thing, and as a result processor A loses its chance to respond?
I am guessing the underlying problem is that checking with the cache for the shared/dirty bit is slower, and also more inconsistent in terms of the time it takes, relative to just responding and immediately raising the voltage on the Snoop-valid wire. Can someone with more hardware knowledge confirm/correct this?
This comment was marked helpful 0 times.
We know because the bus isn't really just a set of wires, which connects a bunch of processors, memory and I/O devices. In addition to that, there's a ton of logic that exists in reality, which is responsible for determining things like, who gets the bus and when, what devices said what, "oh something important happened, let's interrupt all processors to do ____".
Think of ^ that as the control bus. Maybe this picture will help?
{kind=link}
So to answer your question, I'd guess the Shared, Dirty, Snoop-Valid lines in the diagram could be part of the control bus, which uses a form of logic + some enable bits + a clock to make sure everything gets communicated on time.
(And I was only thinking of single bus systems, nowadays you have more complex systems, i.e. Lecture 17, and I'm not 100% sure how the architecture of those looks like)
This comment was marked helpful 0 times.

@sluck
To add to vrkrishn. We can easily design a system where all processors caches set the snoop valid line to high after another processor is granted access to the bus. This can be achieved using a simple hardware thread in each processors cache. This thread must set the snoop valid line to high the cycle after seeing another cache get granted the bus. This would guarantee that the cache that was granted the bus does not see the snoop as being ready before other caches have responded. After the hardware thread sets snoop valid to high, the cache can set it to low after asserting the correct values on the shared and dirty lines.
This comment was marked helpful 0 times.

@sluck, to address your question about a possible fetch deadlock, this won't happen because we have ensured in this example that we have an atomic bus which means that no other commands happen between the BusRd/BusRdX and the processor receiving the data. (Refer to previous slides).
This comment was marked helpful 0 times.


Can someone explain point #2 of variable delay? Does the memory wait until it hears otherwise or does it continue and then backtrack if it hears otherwise?
This comment was marked helpful 0 times.

@RICEric22, I think it deals with when cache line is invalid, then memory will response only if it hears all caches response 'cache miss' or something else that indicates all of them don't have that address. So if snoop can be done quickly, memory may response in less time than fixed clock cycles.
This comment was marked helpful 0 times.
@RICEric22 I'd imagine the memory still works the same way. I don't see the need for memory to not employ backtracking, provided the overhead isn't massive. Variable delay seems to essentially be the same as a fixed number of clocks but with finer granularity. It won't need to ask every cache to reprocess the request if one fails to meet the cycle count deadline.
This comment was marked helpful 0 times.

Question: Since main memory is also connected to the caches by the interconnect, and so it's also listening to the snoop-valid, dirty, and shared wires, why can't it just, when snoop-valid is 0, immediately react to the request if needed? This seems to be the most intuitive and efficient way, and it doesn't seem to be more complex than the fixed number of clocks way.
This comment was marked helpful 0 times.

@idl I think what you're trying to describe is variable delay, but more specifically. Since it may be a variable number of clocks until snoop-valid is 0. But as mentioned in lecture, it is a lot less hardware to assume X cycles, rather than add complexity for this logic.
This comment was marked helpful 0 times.
@idl, in addition, having an access to memory when it could possibly be present in another cache, is simply wasteful.
This comment was marked helpful 0 times.


Using a write-back buffer maintains coherence because reads are allowed to move ahead of writes in a memory consistency model when the W->R memory operation ordering condition is relaxed (e.g. total store ordering or processor consistency). We sacrifice sequential consistency for better performance.
This comment was marked helpful 0 times.

@tomshen, I do not agree. I think write-buffer maintains coherence because write-back buffer is an extension of cache, with status and tag. What you said is about memory consistency, not cache coherence.
This comment was marked helpful 2 times.
@yanzhan2, I'm somewhat confused. I think I understand tomshen's explanation of why this maintains consistency, but could you (or a fellow student) elaborate on why this maintains coherence? I remember Kayvon offering a different explanation about how the order in which caches claim lines in the modified state is the total order of all writes, and I see how this is maintained because write buffers get flushed when other caches want to read/write to that cache line, but the more ways I understand coherence/consistency the better.
This comment was marked helpful 0 times.
Incidentally, does anyone have a good way of remembering which one is coherence and which is consistency? Currently all I can do is remember by thinking about memory consistency models...
This comment was marked helpful 0 times.
@mchoquet, Coherence always relates with one memory address(or one cache line). Consistency relates to the ordering of load/store operations to all address. Which means memory operations to different address, such as load A, store B, would not cause coherence problem.
Adding a write buffer, without give up the state M, would not cause coherence problem. If other caches want to read/write data in the write buffer, same operations happens again as if the data is in the cache. So this means write buffer is kind of an extension of cache. I agree with your explanation above.
This comment was marked helpful 1 times.

I think one way to think about coherence here is to note that when we are evicting cache line X, we must have made a request to read a different cache line Y. Otherwise we would've had a cache hit and there would've been no eviction. And since we're dealing with two different memory locations, coherence isn't violated.
But we do have to be careful of new reads/writes happening on cache line X while it is still in the write buffer (not yet in memory). Not handling this correctly will mean that coherence is violated.
This comment was marked helpful 1 times.
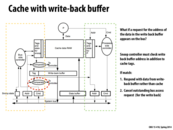
Question: How does the "Tags and state for P" and "Tags and state for snoop synchronized? I can see how the snooping tags may be updated based on the bus information issued by the processor side cache controller. But how does the tags on the P side knows when the snooping disables on some tags? wouldn't that be very important?
(upon raising the question I have a guess: So the snoop side controller independently takes care of all other routines that does not modify the tags, like responding to shouts with its own state (like, shared). However, when the snooping side controller decides that it needs to modify a tag, it needs to stall the processor and update the tags on the processor side. Is that what it does? )
This comment was marked helpful 0 times.
I don't know the details, but any change to the stored tags ought to correspond to a change in the actual data stored in the cache, right? I imagine that your guess is right, and both copies of the tag are updated at the same time as the cache data itself.
This comment was marked helpful 0 times.

I think that in most modern processors, when a cache line is updated, the tag bits can also be updated in the same clock cycle. It should be trivial to add the extra wires from the cache controller which are connected to the correct address register.
I don't think the processor has to 'stall' for a cache line's tag bits to be updated - since it is done in one clock cycle the processor-side controller will just notice that the slot in the cache which previously had a different line or no line now has a line with some tag.
If the processor was completely waiting on getting the new data into the cache, then the processor would be stalled. If the processor has hyperthreading then it might have switched to the other hyperthread while waiting for the line to get into the cache, and in that case the processor does not have to stall. Same with single-thread ILP.
This comment was marked helpful 0 times.

Can someone explain how is having a line in the dirty state different from having a write-back buffer? I mean you could just mark the line dirty and leave it there. You only need to flush when another processor asks for it anyways. You can't avoid/delay that even if you have a buffer. So what's the point of a buffer in the first place?
This comment was marked helpful 0 times.

@achugh I think you also need to flush when the processor's cache is out of memory. Hence, the point of the buffer is to allow the processor to obtain the new line without waiting for the write back to complete in those cases (someone correct me if I'm wrong).
This comment was marked helpful 3 times.

In this diagram, the green region is the logic performed when the processor makes a change to a piece of memory, and the yellow region is the logic performed when some other processor makes a change to a piece of memory and this processor receives a request from the bus.
The red region highlights that when this processor receives a (write) request from the bus, the cache isn't the only thing checked to ensure correctness. The write-back buffer maintains its own tags for each item to be written back so that, on a BusWrX, values that are to be written back to memory that have since been modified by another processor are in fact not written back.
This comment was marked helpful 0 times.

Thank you @uhkiv. Your answer is very clear. So the write-back buffer is used to hide the latency. However, the dirty bit is based on the belief that the dirty cache may be changed again in the near future.
This comment was marked helpful 0 times.


Ideally what could happen is for P2 at the end to notice that its pending BusUpg request is wrong, and modify it to a BusRdX instead. I'm guessing this is a very hard thing to do!
This comment was marked helpful 0 times.


For those of you keeping score at home, I think the optimization described introduces a problem where two processors may write to the same memory location, but they don't tell the otter processors until the write is complete.
As a concrete example, Jill may load memory address foo, then write 3 to foo in her local cache and put it back in global memory. Sometimes while this is happening, her buddy Jack loads foo into cache, increments it, and then tries to put it back. Finally, Jill remembers to tell everybody, "Hey y'all, I wrote 3 to foo" and assumes everybody knows what's what. Now Jack is confused - did he increment correctly? We'll never know!
So instead, we can use a write-back buffer. But why doesn't a write buffer have the same problem? It seems to me, based on the description in slide 31, that the effects of the write buffer only kick in when Jill's cache line containing foo is evicted. Wouldn't it be more important to ensure the invalidation message gets broadcast at an appropriate time?
This comment was marked helpful 0 times.
@tcz
First and foremost, I LOVE otters!!!!!!!! otter processors are sooooo cute!!!!!!
And less importantly:
So I believe that the purpose of introducing write-back buffer is not to solve the problem mentioned in your first paragraph. The write-back buffer is just a separate optimization we made to hide memory latency. The use case for a write-back buffer is such:
Sometime ago, I acquired M state for the cache line X, I modified it, and it stays dirty in the cache line (because we are using write-back instead of write through). However, later on I need to access another cache line Y which conflicts with cache line X, so I must evict X and bring Y in. However, this is expensive, because we have two data transactions. So to cover that up, we bring the Y in, and put the dirty line X into the write-back buffer (until the data line is not so busy and we could flush X to memory).
Remember that at this point of time, no other processor has cache line X valid now because I have it in the M state. Now, if some processor want to busRd or busRdx X, I will check both my tag and state and also my write buffer. I will see that I have X in the modified state, so I will respond with "Hold on I have it dirty, you need to wait for me to flush it to memory", and then do the actual flushing.
This preserves the memory coherence and the scenario you describe would never happen for a line in the write back buffer. :D
This comment was marked helpful 9 times.
@yuyang so re: your example, how is putting the dirty line X into the write-back buffer and flushing to memory at a later time better than just immediately evicting and flushing X? My understanding is that if X is needed again even before it is flushed, that processor can just load it back without needing those extra data transactions, since it is already in the M state.
This comment was marked helpful 0 times.
@idl: I guess that is one thing... But I think the major thing is that since a evict needs two data operations (load new data, write old data), which is very expansive, we might as well break it into two pieces and not occupy the data line for too long and potentially make all the data operations queue up by blocking the data line for too long. By splitting it up into two pieces the 'write old data' can be postponed until sometime later when the data line is not that busy, or when it is absolutely needed :D
This comment was marked helpful 0 times.
@idl another reason to buffer was covered here. Basically, by buffering writes, the cache doesn't have to wait while memory is handling that write. This can lead to higher throughput. But as others have mentioned above, this optimization leads to complications in regard to maintaining coherence.
This comment was marked helpful 0 times.


I think that to say that this situation is a deadlock depends on how much time does p1 need to wait before it gets cache line A. What if p1 gets what it request immediately ? Then the situation of waiting is not a long lasting one to call it a deadlock. Am i right?
This comment was marked helpful 0 times.

If p1 gets the request before the BusRd for B appears on the bus, then there is no deadlock. Like other cases, deadlock would happen when two different controllers request each others' resources, but neither can request and respond at the same time. In this case, if P1 asks for A, and then is sent A before anybody requests B, then there is no deadlock. Since like you said the amount of waiting determines whether or not there is deadlock, there would be a race condition and in general probably makes a not too reliable system.
This comment was marked helpful 0 times.
To have p1 be able to service incoming transactions while waiting to issue request is to break the circular wait condition in the 4 deadlock conditions. This will ensure that deadlock doesn't happen.
This comment was marked helpful 0 times.

Does this assume the processors are sharing line B? If so, then the two processors could be trying to access different memory addresses that both map to line B, right?
If not, then the processors must necessarily be accessing the same memory address, is that correct? Otherwise, P2 wouldn't care whether P1 invalidated the line or not, cause it's different data.
This comment was marked helpful 0 times.

@tcz The smallest level of granularity in a system is a single cache line. A processor's cache handler announces its intention to write to a cache line; it doesn't specify which address it is writing to. If there are any other processors holding that cache line, they must all invalidate their cache lines; it doesn't matter if those processors are using a set of addresses disjoint from those that the writing processor is modifying.
See false sharing for more detail on this.
This comment was marked helpful 2 times.
@arjunh, I agree the snooping unit is cache line, but when cache controller put request on the bus, address is also recorded on the bus (slide 32 has Addr comparison), otherwise the processor can not know whether it has the same cache line.
This comment was marked helpful 0 times.


When we use the policy where multiple processors are competing for bus access and this leads to starvation, will the state of starvation be permanent or not?
This comment was marked helpful 0 times.
@elemental03 I dunt think there will be starvation if using FIFO arbitration.
This comment was marked helpful 0 times.

Starvation can't really be permanent unless the flow of work is continuous and never decreasing - progress is being made somewhere and eventually the processor will get bus access (also, if it's random, then it's very likely access will be obtained eventually, it's just the time frame that is an issue).
This comment was marked helpful 0 times.


Question: Is it true that a system is atomic $\iff$ it is race free?
This comment was marked helpful 0 times.
To Summarize, our design abstraction is that all the transactions are atomic. But making them actually atomic in hardware would be very slow. Therefore, to optimize performance, we break up transaction into smaller pieces, and that is where all the trouble come from. Because we need to make the transactions 'look atomic' even when they are not under the hood :D
This comment was marked helpful 0 times.

@idl, yes. Atomic transaction is the highest standard and therefore the most costly for multi-threading/multi-process cases. Therefore it is safe to say atomic system is race free.
This comment was marked helpful 0 times.
All through class I kept being astounded at how complex implementing cache coherency is. Even in our simple model, there are a large number of steps that need to be performed. Doesn't this negatively affect performance, and the benefits of using a cache in the first place? Specifically, how much slower is using a processor with cache coherence than without?
This comment was marked helpful 0 times.
Of course it depends on the specific protocol, but based on this evaluation of the cost of cache coherence protocols, it seems that 35% slower might be a reasonable figure for MESI.
This comment was marked helpful 0 times.
@sbly, sure this will take away from the performance of a cache, but it is still a significant speedup from a system with out a cache. As the link @cardiff seems to be dead, I would simply say its hard to say how much slower a processor with cache coherence is. This is because without cache coherence, a lot of things would be trash as we as the programmers have a basic assumption of how the memory system works. As the cache abstraction should not really change our thought process of how memory works, having no cache coherence can really cause some problems. Therefore, I think its hard and useless to compare the speed difference between a system that works with coherence, and a system that has issues without coherence.
This comment was marked helpful 0 times.
I believe I have fixed the dead link in my comment above. Thanks @ycp for pointing out the problem.
This comment was marked helpful 0 times.