









To clarify, this is deadlock because P1 is waiting for the bus, but another processor is waiting for P1 to respond to BusRd for X. Since the bus is busy because the BusRd for X is pending, and P1 needs to respond to make the bus available, P1 is waiting on itself, which is a circular wait.
Mutual exclusion occurs because only one processor can be using the bus at one time.
Hold and wait occurs because the processor which issued the BusRd for X is holding the bus, and waiting for P1 to respond.
Preemption cannot occur because P1 is not capable of servicing the incoming BusRd request while also waiting to issue its own request. Also, the BusRd for X is not preempted because the processor which issued it cannot magically cancel the request.
We fix the issue by allowing P1 to preempt its own request.
This comment was marked helpful 2 times.

At an abstract level this seems like a problem --> we set up a condition where P1 has to wait to send a request and also set up a condition where P1 has to do something while waiting.
While this may seem like an issue, when it comes to actually implementing an efficient "waiting" protocol, it seems like one would store P1's request until the bus tells P1 it can send the request, rather than have P1 loop until the bus is free. This event based model I've just described would obviously allow P1 to service other requests quite easily.
I am not sure if this is particularly easy to implement in hardware, but I'd imagine an agnostic loop that simply polls for ANY kind of update (rather than a specific "CAN_USE_BUS" signal) would be a good first attempt at the problem.
This comment was marked helpful 1 times.

To elaborate on @bwasti's idea, I don't see why we can't simply have another wire as part of the bus, which is triggered by the bus itself, to indicate that it is free. If the voltage on this wire is high, then the processors can make their requests and the bus arbiter will decide accordingly.
This comment was marked helpful 0 times.


In the context of the traffic example:
- Mutual exclusion: Only one car can occupy a certain piece of road space at a time.
- Hold and wait: Cars occupy their space until they can move foward, and can't back up because there are other cars behind them.
- No preemption: Kayvon said this one is a bit of a stretch, but there is no helicopter that can come remove a car from the road to clear the path for other cars.
- Circular wait: green car 1 is waiting for yellow car 1, yellow car 1 is waiting for green car 2, green car 2 is waiting for yellow car 2, and yellow car 2 is waiting for green car 1.
This comment was marked helpful 1 times.

I agree that this paraphrases exactly what we said in class.
This comment was marked helpful 0 times.

I'm a little confused about the difference between hold and wait and no preemption. Hold and wait says that a processor keeps a resource until it can acquire another resource to do an operation, but no preemption only seems to emphasize this in saying that they will keep the resource until they finish the operation. So basically no preemption seems like a subset of hold and wait with a bit more emphasis on the holding...
This comment was marked helpful 0 times.

@jhhardin The way I understand it, (in deadlock) not only is a process going to hold onto a resource until they finish the operation, but no preemption refers to the fact that you cannot force it to give up the resource, e.g. there's no external player saying hey, you're causing problems, give up your resources. One of the examples for no preemption given in 15-410 is: "Interrupting a CD-R burn creates a 'coaster.'" But I think the comments on the previous slide might help to give a clearer picture in how "hold and wait" and "no preemption" are separate conditions for deadlock.
This comment was marked helpful 0 times.


So if my understanding of livelock is correct, the number of times the two 'parties' try to obtain a resource and fail (due to livelock) is nondeterministic. In my mind, I'm drawing a parallel here, to when you're face-to-face with somebody and you try to avoid walking into them, and both decide to duck in the same direction, again and again. Nobody knows how many times this will happen before the livelock is resolved... is this the case here too?
This comment was marked helpful 1 times.

Yep!
This comment was marked helpful 2 times.

Are there any "required conditions" for livelock, like we discussed for deadlock? I imagine that we still require mutual exclusion, but the other three don't seem to fit since, in this case for example, neither processor attempts to complete their operation.
This comment was marked helpful 0 times.

@moon I'm not sure if there's a set of requirements for livelock that apply to all cases. But I think the key reason livelock occurs here is that we add in preemptibility (P1 invalidates in response to P2's request to BusRdX) without ensuring progress.
This comment was marked helpful 0 times.



I'm going to try to give at least partial answers to these questions:
When a bus request is made, the bus will be occupied for the entire duration of the request and the response, which also includes the time between request and response when the data is being looked up in memory. In many cases this is unnecessary because requests don't conflict and they could be done in parallel.
There is a bus for requests and one for responses. There is also a separate bus for data. Information can be travelling along all three buses at the same time, but there can only be one request/response/data at a time per respective bus.
In an atomic bus, deadlock can occur when a processor is waiting to send a BusRdX, but at the same time a BusRd comes for a cache line that the processor has modified. In a non-atomic bus, deadlock can happen when the L2 cache is trying to update information in the L1 cache, but another request is coming in from the L1 cache. It cannot send the information until it receives the other information from L1, but L1 cannot receive the information from L2 until it sends its first request. I think I have this sort of correct, I was a little confused about slide 29.
Queues seem useful here for the same reason they are usually useful in parallel systems: because it gives a better chance that workload will be evenly distributed, and with fewer stalls in between so that the total workload can be finished faster.
This comment was marked helpful 0 times.

For question 3, I believe that the example with the L1 cache and L2 cache for a non-atomic bus deadlock wouldn't apply since there isn't any bus traffic involved in communication between those caches.
However, I'm actually not entirely sure how to cause a deadlock on a non-atomic bus-based system that is due to the bus itself instead of the actual program logic. That is, it is possible to write a program that, when executed, has instructions that in some sequential ordering of concurrently executing code, will cause a deadlock on a non-atomic bus-based system. However, that would be more of a fault of the program itself and not a fault of the bus. Anyone have further input on this?
This comment was marked helpful 0 times.

Correct me if I'm wrong, but I agree with @spilledmilk that there cannot be an interleaving of instructions that does not involve L1 - L2 communication in a non-atomic bus-based system. If all the processors keep track of request they issued and all processors respond in a reasonable amount of time, the system should not deadlock at all. However, when L1 - L2 queue comes into play, there can be a deadlock as mentioned in the later slides.
This comment was marked helpful 0 times.

For question one, the motivating reason is that for a atomic bus, the bus cannot be used by another entity when one request is not finished even if the bus is idle at some point. This is inefficient and we'd like to utilize the idle time.
This comment was marked helpful 0 times.

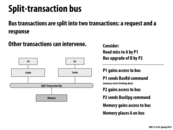

A split-transaction bus means that when a CPU places a memory request on the bus, that CPU immediately releases the bus, so that other entities can use the bus while the memory request is pending, and this is why a split-transaction bus is non-atomic. When the memory request is complete, the memory module involved will then acquire the bus, place the result on the bus (the read value in the case of a read request, an acknowledgment in the case of a write request), and in most implementations, also place on the bus the ID number of the CPU that had made the request. The latter (the CPU with that ID) will see that the memory’s response is for it and accept it.
This comment was marked helpful 0 times.



Do modern multiprocessors only support a fixed number of outstanding requests as our processor did (and if so, what's the number?), or do they work with a dynamic number of requests?
This comment was marked helpful 0 times.

There will be a fixed number of outstanding requests. Hardware bookkeeping structures that keep track of outstanding requests (e.g., the request table in this lecture) will be fixed size.
Take a look at this figure for some stats from a recent Core i7. The number of outstanding misses in the figure is the number of outstanding memory requests from any one cache. This is slightly different from the number of outstanding requests on the interconnect, which we deal with in this lecture, but it makes a similar point.
This comment was marked helpful 0 times.
It seems like we don't really talk about the issue of possible starvation due to the NACK. I would guess that in real hardware there are procedures in place to ensure that you don't get a NACK an unbounded number of times.
This comment was marked helpful 0 times.

So the system queues request regardless of request content? If so the chance of starvation can probably be kept low just by the design of hardware.
This comment was marked helpful 0 times.
A simple solution is that you elevate the priority of a client each time they get NACKed. (or decrease the priority of a client each time they successfully use the bus) If the bus arbitrator inspects these priorities when making bus grant decisions, no one will be starved.
This comment was marked helpful 0 times.

I might be misunderstanding something here, but don't you get a NACK if the buffer is full? The arbitration is then solely on whether the buffer is full or not, so I'm not understanding how increasing priority would work - if you're unlucky and issue a request just as the buffer fills up every time, you'll just get more NACKs.
Perhaps you could simply inspect the entire buffer and throw out requests that have lower priority than the incoming one, but this could lead to livelock if the thrown out request causes many more requests that get NACK'd and its priority eventually increasing higher than the request that had originally evicted it from the buffer.
edit: on second thought, it seems like decreasing the priority of the client on each successful bus use would work pretty well in combination with inspection of the buffer. Nevermind.
This comment was marked helpful 0 times.


In class someone mentioned the idea using address as the tag, instead of using the entry of the table. I still think it is a good idea, since we already have the address bus at the request bus. So what is the disadvantage of such method?
This comment was marked helpful 0 times.

Maybe it's just that the response tag is smaller? It looks like like lookup in the request table is done by-tag, so it might be simpler to choose a smaller tag than the size of a memory address.
This comment was marked helpful 0 times.

@yetianx: At first, I thought that problems might occur with that approach when multiple outstanding requests existed in the request table for a single address (i.e. different processors request to read the same address). However, I now realize that if there are multiple requests to the same address, then the responses are the same for both of those requests, meaning that they don't need to be matched up to the specific processor that made the request and could just be sent to whichever processors have outstanding requests to that address. This brings us back to the same question. It seems redundant to have an extra bus line for the response tag when the address could serve as the identifier.
This comment was marked helpful 0 times.
Well I think the point is that since we also have to keep track of the outstanding requests, and therefore will have an index into the table of requests, we may as well use the index because it's smaller. Basically, there is no advantage to using the address over the tag, so we may as well use fewer wires for the response bus. Note that the address is not part of the response bus already - the address is only included in the request bus - so we don't get the address for free.
This comment was marked helpful 0 times.
@kleino: I think your point that we don't get the address for free is right. If we use the address line to pass the response memory address, we lost the ability to pass the request memory address at the same time. It would slow our pipeline.
Now, another process can send a request while one process is receiving data.
This comment was marked helpful 0 times.

On modern CPU's, how many buses are there? (Like it says on the slide the BUS is split into a Request and Response BUS, and then there is also the response tag bus).
This comment was marked helpful 0 times.
Woops, missed this, Intel's Ring Interconnect has 4 rings.
This comment was marked helpful 0 times.

@yetianx: In hardware selecting an entry from that table using its index needs only a simple multiplexer. Doing this using addresses, would require a comparator for each entry in the table (to check for address matches). This would be more costly in silicon, and time.
This comment was marked helpful 2 times.
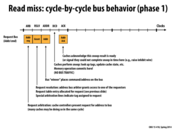

Is the above always true for bus behavior? More specifically, does each of those steps above always only take 1 cycle?
This comment was marked helpful 0 times.
@LilWaynesFather This probably depends on the design of your system. If certain parts of this process were slower than others, it is likely that those parts would take more than 1 cycle.
This comment was marked helpful 0 times.
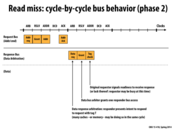

Are there any performance implications if the original requestor does not signal readiness to receive the response? Will the data still be sent immediately?
This comment was marked helpful 0 times.

I don't think the data will still be sent if the requestor does not signal readiness. The diagram seems to indicate that there is a certain time frame for receiving the signal for readiness. I would assume that if the time frame passes without any response, there would be some mechanism to cause the request to be retried. I couldn't find any information on it though.
This comment was marked helpful 0 times.

Why would it be necessary for the original requestor to signal readiness to receive the response? Couldn't the data just be sent and then once the data is on the other side of the bus, the requestor can be signalled that the data has arrived? Also, in most cases the requestor is probably just waiting around for the data it needs which is another reason it seems unnecessary for the requestor to signal readiness.
This comment was marked helpful 0 times.
@asinha I think that sending the data on the bus might need to happen over multiple cycles, as is the case here. If the original requester is busy (for whatever reason) and doesn't grab the data from the bus on each cycle, it'll basically not get the data it needed.
As to why it would be busy with something else, I'm not entirely sure. It's definitely not because it's receiving memory for a different request, since there is only one response bus. Maybe someone else can comment?
This comment was marked helpful 0 times.

@asinha I think what also might happen is that if the original requestor is not ready for the data, the response will get sent over the bus and then sit while the requestor finishes whatever it is doing. Meanwhile, nothing else can be sent over the bus or else the response will be lost (I suppose something else could be sent over the bus, but then the response would have to be sent again later). Perhaps one reason the original requestor might be busy with something else is that it has switched contexts while it waits for the memory request to finish, such as in a multitasking system on a CPU.
This comment was marked helpful 0 times.

As we see on the next slide, sending data requires several clocks of usage of the data bus. Soif we just send immediately without a response, then we just wasted a bunch of cycles on the data bus.
This comment was marked helpful 0 times.
If the requestor is not ready, the data cannot be sent. (Otherwise the requestor will miss the data!) The responder essentially receives a NACK on the response. The responder will have to try and send its response later, and hopefully the requestor will then be ready.
This comment was marked helpful 0 times.
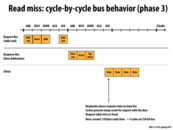

Question: What does 'Caches present snoop result for request with the data' mean?
This comment was marked helpful 0 times.

@Yuyang A couple of slides before this, one of the steps was "Caches perform snoop: Look up tags, update cache state, etc." When the data is on the bus is when any snoop results are actually needed/used.
This comment was marked helpful 0 times.
These are the results of the snoop, such as a caches indicating it also has the line in the shared state. The snoop results tell the requesting processor what state to load the line in.
This comment was marked helpful 0 times.
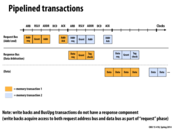
Separating the BUS into several different lines allows this pipe-lining to occur because it lets different requests start before others have finished. This is only possible because it breaks a request into sections and once a request/response is done with that section, it can let another message be sent on that line. Overall, it increases the throughput and decreases the latency for requests.
This comment was marked helpful 0 times.

All the complicated communications and designs here are just trying to make a synchronous transaction asynchronous. Designing an asynchronous system is not easy even on the software layer. Great work!
This comment was marked helpful 0 times.

@ycp: I think pipeline increases throughput but not necessarily decreases the latency.
This comment was marked helpful 0 times.

Is latency decreased or not?
I think it is because now as against to the case of an atomic bus other processors don't have to wait until the bus is done with both request-response. Thus the average latency will be lower.
This comment was marked helpful 0 times.

@iamk_d___g: I think the decrease of latency is a result of latency hiding. For a single transaction, the latency is not decreased whereas due to multiple transactions could be running at the same time as opposed to what's happening on atomic bus, the latency is hidden.
This comment was marked helpful 1 times.

I agree with @shabnam, latency decreases because most threads will spend less time waiting for the bus. The pipelining allows the second memory transaction to go ahead and make its request while the first is waiting for its response. On an atomic bus, the second transaction would instead have to wait for the first to receive its response before making its request.
This comment was marked helpful 0 times.

This is very similar to the washer/dryer problem we looked at a while ago. I believe that any single transaction, disregarding other transactions, does not get decreased latency. However, once multiple transactions are considered, we can see the latency hiding in action.
This comment was marked helpful 0 times.
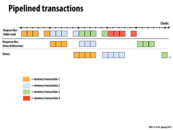

The start-to-finish time for the first transaction is about 13 clocks, but each bus (request, response, data) is only used by the first transaction for a fraction of those clocks. Pipelineing other transactions reduces bus idle time and results in a greater transaction throughput. This is especially important because not all transactions use the response and data buses, and those buses would be essentially wasted for several clocks if other transactions weren't able to use them.
This comment was marked helpful 0 times.
This reminds me of the washer/dryer example from the first half of the semester.
This comment was marked helpful 0 times.


Couldn't NACKs be a source of livelock? That is, a request keeps retrying, but every time it does so the buffer is full, because other requests have been sent in the meantime? Is there a mechanism for preventing this? Or is this just basically unlikely enough that we ignore it?
This comment was marked helpful 0 times.
What you described sounds like starvation, not livelock. I'm not sure what mechanisms are used to prevent this, but I bet caches retry so frequently that it isn't an issue.
This comment was marked helpful 1 times.

If the other requests filling the buffer are currently making progress, then that is in fact starvation and not live lock. It is only live lock when no progress is being made by everyone.
This comment was marked helpful 0 times.
Oops you guys are right! It's starvation, not livelock. It still seems like that's a problem though.
This comment was marked helpful 0 times.
@sbly Yeah, I was also thinking that the NACK might cause a starvation. I think a simple way to solve the problem is to keep track of an int, NEXT , denoting a cpu. We can imagine NEXT starting as 0. Whenever the buffer fills, NEXT gets incremented (wraps back to 0 if it goes beyond the number of processors). Then once the buffer has room, the cpu denoted by NEXT gets the highest priority making the next request.
So worst case, a processor will get a NACK equal to the number of processors. And this NEXT variable doesn't need to be centralized either. It can be kept updated on each processor, just like the table.
This comment was marked helpful 1 times.

I think negative acks can we used as a solution for the conflicting requests. This might help increasing the efficiency, by knowing immediately that a request to (say x) can't be completed right now. This way the processor which sent the conflicting request, can do some useful work instead of remaining idle, and then it could send the request again.
This comment was marked helpful 0 times.
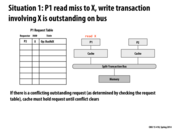

One of the possible responses by the bus is to respond with a "NACK" to P1, so it can go do something else productive (if that is possible) rather than simply stalling (another alternative).
This comment was marked helpful 0 times.

I think that if the only operation the processor has is the read X, then a NACK wouldn't really help here as it'll remain waiting.
This comment was marked helpful 0 times.

Wait, who wrote the 'share' in the Request table? Is it P2 or P1? If it is P1, how would this work for MESI protocol?
This comment was marked helpful 2 times.
@yuyang, I do believe it makes sense that P1 wrote the 'share' in the request table. The fetching of data from memory is necessary for both processors anyways and presumably, each of them will change their state according to the 'status' on the request table, after receiving the data. I'm not a 100% sure if this is how it is in practice though.
This comment was marked helpful 0 times.
I also just wanted to double check that in the event that the outgoing request is a write, then we always get a NACK and the only scenario where we do something other than a NACK is when we have 2 reads to the same location.
This comment was marked helpful 0 times.
P1 made a note in it's own table that it is interesting in the result of the outstanding operation triggered by P2. 'Share' in this slide means, "I should take action when that response is put on the bus". Do not confuse it with the 'S' state in the coherence protocol. (However, it is true that this value will be loaded into P1's cache into the 'S' state, since the line will also be held by P2.)
This comment was marked helpful 0 times.



In general, if we seek to maximize performance, we would prefer to have longer queues. However, given that longer queues need more memory, we need to make some tradeoffs. If we have a fairly predictable, balanced workload, then a shorter queue would be fine, since we wouldn't need to queue up more than a few requests at a time. However, if we have a highly unpredictable workload, longer queues would be worth the extra memory because of the time saved by avoiding stalls.
This comment was marked helpful 0 times.
For those interested, the probability that a request finds the queue busy is given by the Erlang-B formula. The formula is a little messy, but it decreases exponentially with the length of the queue. This is assuming that request times follow a Poisson process, though, and I don't know how realistic that is for this situation. Maybe Kayvon has some data on that?
This comment was marked helpful 0 times.
We had an interesting discussion about how work rates translate into different size of queues. If we want maximum performance and assuming we can make some assumptions that the rest of the parameters are standard and assuming we don't know if work steps are even or not, we will chose the biggest queue possible.
I think this was the conclusion? I think we need smaller queues if workload is assumed to be around balanced whereas we need bigger queues if workloads aren't that balanced.
This comment was marked helpful 0 times.
In this case, I think the tradeoff is between bus lines and queue length. For a longer queue, the bus needs to be wider to have more contain more tag bits.
This comment was marked helpful 0 times.



If L1 cache has a cache miss it will request data from L2 cache, creating one outgoing read request to fill up the buffer. Now, there might be a cache coherence transaction and the actual data in the L1 cache is dirty and L2 requests L1 to flush it. Suppose another third transaction comes in and if L2 is busy with it and L2 needs to tell L1 about this transaction. This situation is deadlock because L2->L1 queue is full and L1 can't drain that queue because it's waiting for the request in L1->L2 queue to be completed.
This comment was marked helpful 1 times.
I had a misunderstanding here that queues are channels and both L1 and L2 caches have their own buffers. There is no deadlock in such case.
But it is wrong, because queues are buffers here and caches cannot do anything until buffer is ready/empty.
This comment was marked helpful 0 times.

Armed with the knowledge from the following 2 slides, I believe the problem here is that the queues are used for both requests and responses. Both asking for data and responding take a slot in the queue. When both processors are asking for things from one an-otter, there is nowhere to put the response; the queues are full. So processor 2 is waiting for processor 1 to finish servicing the request its working on and clear out the queue, so 2 can put its response to 1's request onto the queue. But processor 1 is waiting for processor 2 to do the same thing. Hence, deadlock.
This comment was marked helpful 0 times.


How big would that size have to be? Is it that each processor should have room for requests from all other processors on its buffer, plus room to respond to them, so 2(P-1)M, where P is the # of processors and M is the size a request takes up?
This comment was marked helpful 0 times.
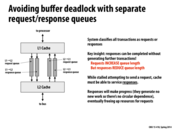

I'm not sure about how two queues can solve the problem. For example, there is a situation that both L1 and L2 are attempting to send requests. They stall because both request queues are full. They can service responses, but this only reduces response queues. How can this mechanism eventually change the states of requests queues?
This comment was marked helpful 1 times.
I think that this is solved by the caches being implemented in hardware. Just because a cache is "stalled" on a request does not mean it cannot respond, especially since there is an available queue for responses.
In your example,
L1 --> L2 request * (queue size + 1) (waiting for the +1)
L2 --> L1 request * (queue size + 1)
L2 gets request (we can read off the incoming queue while waiting to send our +1)
L1 gets request
L2 responds in response queue
L1 responds in response queue
L2 pulls a new request off the incoming queue
L1 pulls a new request off the incoming queue
(etc)
This comment was marked helpful 0 times.

@squidrice, When a request is serviced, a response message is generated to put on the response queue, and the corresponding request message is removed from the request queue. In your situation, if two request queues are filled, then each cache could receive message and put response messages to the response queue, so it can remove messages in request queues. I totally agree with @smklein.
This comment was marked helpful 0 times.
I think this method is similar to adding virtual channels in interconnect networks. The advantage is that messages belong to different types and if there is only one channel, head-of-line blocking could occur and block later messages which could be processed for other types.
In this example, if the request in request queue could not be serviced dur to some reasons, it could stay in the queue and wait for the situation to be solved. But other messages from different channels could be received and make progress. Such as response queue.
This comment was marked helpful 0 times.


ohgodwhy
This comment was marked helpful 10 times.
Can somebody explain in more detail what is meant by " ability to cancel pending bus transfer requests"?
This comment was marked helpful 0 times.
We assume that our system has a relaxed W-R consistency model (allowing writes to move in from of reads that are not dependent on outstanding writes) that is implemented using a write-back buffer. Let us now define a situation:
Processor 0 writes x = 0 and then rapidly reads a million elements from an array. The update x = 0 now resides in the write back buffer; it has not been flushed out to memory yet. The update resides in the write-back buffer and keeps trying to gain access to the bus in order to flush its data to memory.
Processor 1 then asks for variable x and by our coherence model, the variable x must be flushed out to memory. However, the write back buffer still is requesting access to the bus the bus to write x to memory. Therefore, we need to be able to cancel the write-back buffer's request to flush x out to memory
This comment was marked helpful 1 times.
@vrkrishn, Does the write buffer constantly try to get access to the bus for a BusWr? I thought the actual flush out to memory happened only when someone else requests for a read of a line that is in our write buffer or if our buffer is full.
This comment was marked helpful 0 times.
I think "the ability to cancel pending bus transfer requests" means to avoid race condition when two processors are competing to get access to and write to a shared address. When one processor wins, the other has to drop previous BusUpg request and change it to BusRdx.
This comment was marked helpful 0 times.