







This reminds me of in assignment 3, for the breadth-first search, there were certain sections that needed to happen sequentially to prevent interference between the threads. When using "# pragma omp critical," it often seemed to be slower than when using "# pragma omp atomic." I wasn't sure why that would be, but this seems to be one possibility... Was it that declaring a critical section was like surrounding it with a lock, so that it always slowed down the system on that section, whereas using "atomic" used optimistic concurrency, like described on this slide?
This comment was marked helpful 0 times.

@jmnash You seem to be right.
So a basic summary of what this says:
If you have multiple critical sections that are unnamed, this can cause a huge slowdown. This could have been a problem because if you had two different critical sections, but they were not named, then only one thread can be in either of them, even if they were not dependent on each other. This can be thought of by using the same lock on both sections. Of course, this can be fixed by naming the sections differently.
For atomic sections, it requires a lot less overhead, but it also relies on the hardware having an atomic operation for whatever is in the section. In that case, no locks are necessary. However, if that is not the case, locks might have to be used. Additionally, being in an atomic operation section does not stop any other thread from entering another atomic section like unnamed critical sections do.
This comment was marked helpful 0 times.

To add on to potential downsides of using atomic, @ycp mentions that using it requires the hardware to have an atomic operation for the code inside the atomic section. The OpenMP specs actually specify what kind of operations can be inside of a atomic section (things of the form x++, x--, x binop = expr or similar). From the above comment, it may seem that if the expressions inside the atomic region do not follow the guidelines, the atomic expression may just use a lock. This is not true as far as I know; instead, the compiler will just yell at you until you fix it. Source: personal experience in assignment 3.
This comment was marked helpful 0 times.


Declarative abstraction sometimes is faster than imperative. When computer decides some operations (read and write) within "atomic" can be performed in parallel. This is explained in detail in lecture 15.
This comment was marked helpful 0 times.

How would you determine which to use in practice without actively writing both and testing them? You could test out both, but if imperative involves writing a large codebase with a complex series of locks it could be easier to know how much faster it would be than declarative without having to write it out.
This comment was marked helpful 0 times.

@retterermoore I'm not sure there is a better way to find out which is faster. Determining that without actually trying it would involve intricate knowledge of how the compiler translates the declarative code, target architecture, etc.
This comment was marked helpful 0 times.

I believe that when stated in a declarative way, this gives the compiler/runtime the chance to heavily optimize how it should atomize the code. This could potentially result in a much faster implementation than if the developer worries about it.
This comment was marked helpful 0 times.

ISPC forall loop is declarative, it let the compiler decide how to run the gangs and assign work. While the for loops is imperative, the programmer states how assignment should be done.
This comment was marked helpful 0 times.

@ruoyul I was having the same thoughts about explicit vs. implicit parallelism. Declarative is the same as explicit, in that the programmer has to specify the work division and how it should be done; Imperative is like implicit in which there is usually some construct that says how something will be done to an extent, but the actual implementations are usually hidden from the programmer.
This comment was marked helpful 0 times.

@bxb Shouldn't those be the other way around?
This comment was marked helpful 0 times.

I think declarative code would be more portable and much easier to write. SQL is an example of a declarative language.
This comment was marked helpful 0 times.


These transaction seem to be similar to SQL database operations, where you can perform bulk insert/delete/update operations in the database within a single transaction.
This comment was marked helpful 0 times.

The same ideas come into play in both cases. Databases were and are frequently accessed and edited by multiple clients at a time, and so Atomicity, Consistency, Isolation, and Durability (ACID), ensure that the databases does not lose or corrupt data.
I think the main difference is databases are affecting memory specifically in a database, whereas here it's just affecting memory.
This comment was marked helpful 0 times.

Well, that's not even much of a difference. In SQL you tell the driver to insert value X into column Y of table Z, and with transactional memory you insert value X into address Y--it's just a matter of how you address the memory owned by the database.
This comment was marked helpful 0 times.

How is this different from the ACID property of database transactions?
This comment was marked helpful 0 times.

Well it seems to be missing the consistency and durability parts of ACID. Durability might not apply to memory because memory really isn't meant for durable storage. If there's a power outage, we really don't expect (or even want) memory to be restored to its previous state.
I'm not completely sure why consistency doesn't apply, but memory might not follow certain integrity rules that might apply to databases. You can define a database such that all its data and transactions follow certain constraints, but that idea doesn't really translate to memory management. With memory management, you are concerned with coherence and consistency, not necessarily integrity constraints that the user imposes on the data. I could just be wrong though.
This comment was marked helpful 0 times.

@LilWaynesFather: I think that is completely correct. For database access the level of abstraction is raised. Consistency in DBs really just means keeping the database in a valid state, which has to do with the rules and triggers set up by the programmer when creating the schema. With memory management, this level of control is not built in and thus it doesn't make much sense to think of transactional memory in this way. However, we can say that transactional memory does guarantee a valid state, but this doesn't mean much.
This comment was marked helpful 0 times.

What is meant by "transactions seem to commit in a single serial order"? Is this referring to the order of memory writes within a single transaction, or the order in which multiple transactions are committed?
This comment was marked helpful 0 times.
@cardiff This is referring to multiple transactions: even though many transactions may be running in parallel, we want the results to be indistinguishable from those produced by running the transactions in serial in some order (but not necessarily any specific order!)
This comment was marked helpful 0 times.

Essentially, the operations within a single transaction will never appear to be interleaved (if doing so would affect the results).
This comment was marked helpful 0 times.




Besides the synchronized HashMap, Java also has a ConcurrentHashMap class that is another example of thread-safe hashmap implementation. Both maps are thread-safe implementations of the Map interface. ConcurrentHashMap, however, is implemented for higher throughput in cases where high concurrency is expected.
The following article has a good explanation of the implementation of ConcurrentHashMap, talking further about how it provides better concurrency while still being thread-safe:
ConcurrentHashMap implementation
This article compares the performance of Hashmap, synchronized hashmap and concurrent hashmap:
This comment was marked helpful 0 times.


It seems to me that for any data structure, there should be a thread-safe and non-thread-safe version, depending on if you have more than one thread accessing it or not. This way we wouldn't incur the locking overhead when synchronization wasn't needed. It seems Java has this for some data structures. However, I can see how this could make codebases more difficult to maintain, and also cause portability issues.
This comment was marked helpful 2 times.


Some disadvantages of fine-grained locking are shown on this slide. For a smaller number of processors, the overhead associated with locking and unlocking at each step clearly outweighs any potential benefits from having the fine grained locking. Furthermore, fine grained locking involves an extra lock element in the struct that defines nodes in a tree or hash table entries, which takes up more space.
This comment was marked helpful 1 times.

For the balanced tree, it looks like coarse locks doesn't cause too much of a performance problem compared to the find locks. In case where having a fine lock system where locks could be inefficient, it doesn't seem too bad of a choice to go with coarse locks, since it is simpler to program and doesn't cause too much trouble.
This comment was marked helpful 0 times.

@woojoonk I don't think it is reasonable to use coarse locks because it prevents the balanced tree algorithm from achieving any kind of speedup regardless of how many processors we use.
This comment was marked helpful 0 times.

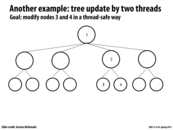
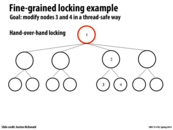
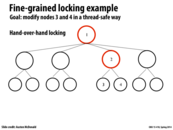
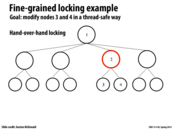
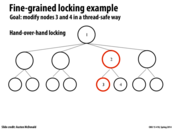

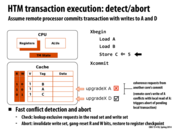
As discussed in lecture, a potential solution here without using transactional memory would be to use reader-writer locks on each node, which allow unlimited readers to access a node, but ensures that writers have exclusive access before they modify information. This would remove the contention for nodes 1 and 2 in this example since exclusive access would only need to be obtained on the locks for nodes 3 and 4.
However, one potential problem with this approach is that reader-writer locks are not fair and can either starve the readers or starve the writers, depending on the type used.
More information can be found on slide 16 in this 213 lecture.
This comment was marked helpful 4 times.

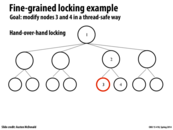
And also, updating node 3 could delay an update to any other node, since it locks node 1, which happens to be the root node. Hence, while it would be possible to concurrently update any leaf node without any problem, there's contention by the lock on the root.
This comment was marked helpful 0 times.

@spilledmilk I believe your statement, "reader-writer locks are not fair, and can either starve the readers or starve the writers", is not necessarily true. Whether or not a RW-lock starves anyone is implementation independent -- it is possible to imagine a RW-lock that stops allowing more readers into a critical section when any writers are waiting, and a RW-lock that lets a burst of readers access a critical section (if the readers want to) in between writes. Although this may not be optimized for the general case, both readers and writers would eventually gain access to the critical section, and thus neither would be starved.
This comment was marked helpful 0 times.
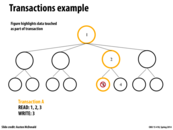
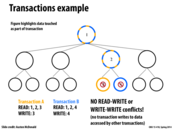

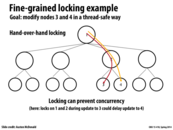
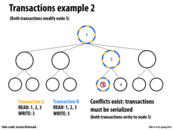
Instead of using hand-over locking, we can observe the paths that the two transactions (in this case, two writes, one to node 3 and one to node 4) take and determine whether or not the operations need to be serialized.
One possible solution is to first check whether the paths of the transactions running in parallel conflict or not. If they do, then we serialize the operations. Else, we can run them in parallel. Note that the observations can be done in parallel, since they aren't changing the data structure (only determine which operations are reads/writes). It's a small overhead, but it can allow the operations to run in parallel much more frequently.
This comment was marked helpful 1 times.





It's just like the dining philosophers problem: everyone pick up the fork on his left hand, then encounter deadlock. One way to solve it is to try to get another lock, say B, if we can't obtain B, then we have to release the lock A and try again later; if we can, we are good.
This comment was marked helpful 0 times.

@black: But such solution may lead to the livelock problem.
This comment was marked helpful 0 times.
Would a solution to this kind of problem be just acquiring the locks in a defined order? Such as if by some ordering a < b, then always acquire lock a before b. Then, regardless if we are calling transfer(a, b) or transfer(b, a), the locks are acquired in the same order and there can't really be a deadlock, because whoever gets a will get b as well.
This comment was marked helpful 0 times.
@ycp Possibly, but that would involve some additional checking regarding which locks have been acquired (which in turn would have to be atomic).
I think a simple solution to the problem would be just making the process of acquiring the two locks atomic; that is, you acquire both locks at the same time. It is impossible for a single lock to be acquired on it own.
This comment was marked helpful 0 times.

@arjunh
If you already had an atomic construct would you just put all the code in it like on slide 31. Having a ordering on how to acquire locks (as ycp suggested) would ensure that deadlock does not occur.
This comment was marked helpful 0 times.

Instead of atomically acquiring both locks, we can have a mechanism to ensure that a thread either gets all of the locks it needs or none. In that case, we prevent deadlock. one drawback would be starvation.
This comment was marked helpful 0 times.
@crs how is that different from atomically acquiring both? If you atomically get both, then you get all the locks you need... remember that atomic { } is a declaration and not an implementation, so your solution is simply one way of doing atomic { } (assuming we try to perform the transaction again when the locks might be free, which is a pretty safe assumption).
This comment was marked helpful 0 times.


This Java snippet illustrates how improper synchronization has the potential cause deadlocks. Another similar problem that can arise with nested synchronization - even when locks are acquired in the same order - is "nested monitor lockout". In essence, one thread blocks until a signal from the other thread is received, and the other thread blocks until the first thread releases its lock. There is a good example of this type of situation here.
This comment was marked helpful 0 times.



Transactional memory often performs as well as fine-grained locks, with the programming simplicity of coarse locks. Presumably, though, it would also not perform as well as coarse locking in the event of low contention, since it needs to keep track pieces of memory being modified in a highly granular manner? Could we just assume TM has a performance comparable to fine-grained locks, with the attendant advantages and disadvantages?
This comment was marked helpful 0 times.




Thread 2 blocks on flagA, which is set in thread 1, and vice versa. When we're using separate locks, this is fine, because while thread 2 is blocked, thread 1 is still able to run and set flagA to true, so that thread 2 can resume.
However, if we made these sections atomic, if thread 2 runs first while flagA is false, it will block indefinitely, because thread 1 cannot run while thread 2 is inside an atomic section. Thus, the program will deadlock, since thread 2 is waiting for thread 1 to set a flag, and thread 1 is waiting for thread 2 to exit the atomic section.
This happens because atomic constructs act like "global" locks, since no other thread can run while one thread is in an atomic section. However, in this case, we want different locks for each section of code.
This comment was marked helpful 5 times.
Wouldn't it be a good idea to be able to declare names for different atomic sections that need to be serialized with each other, i.e. atomic(crit_section_1) and atomic(crit_section_2). That would solve precisely this problem, and would probably allow speedups in many other situations. Or is that breaking the atomic abstraction?
This comment was marked helpful 0 times.

I am curious to the answer to sbly's question as well. My guess is that with atomic implemented using transactional memory, there's no easy way to do this. Transactional memory can detect that two different accesses are modifying/reading from the same variables, and one of the conflicting transactions out. It would probably be more complicated if we want to "tag" the transactions.
I am also curious about what happens if we have "nested" atomic sections. Maybe within an atomic section, we call a function which contains an atomic section. Is this disallowed? Does it instantly cause deadlock? Or is the inner "atomic" just ignored? Something like the following:
foo(){
atomic{
if(stop condition is true) return;
do some stuff
foo();
}
}
This comment was marked helpful 0 times.
@sbly that is likely breaking the atomic abstraction which is essentially that all or nothing happens. If you were to allow two atomic tags something along the lines of a = 1; if (a) b = 1; would not necessarily happen the way the programmer intended, given another atomic operation with a different tag somewhere else (assuming this is a relatively large code base, this is very plausible) had a = 0;. It would sort of ruin the appoint of atomicity guarantees.
@eatnow I don't see why that would need to deadlock: the atomic call would guarantee the exclusive execution of the code up until foo(); and then it would continue with a new call to foo. If there were only thread, everything seems like it would just be as serial as without making it atomic. I could be wrong, though.
This comment was marked helpful 0 times.


In this example, T1 executes some code in the atomic block, where it sets ptr to A and then does some other operations. If the two atomic blocks were joined together, since there is no code in between, we would be guaranteed that when we access ptr, it would point to A because all the operations in the braces would be atomic - no conflicting memory operations are allowed to occur anywhere in between the start and end of the atomic block.
However, the programmer here has accidentally split the two atomic blocks, so that conflicting operations can actually occur (the transaction has been committed too early, so other threads are now allowed to commit their transactions, and thus modify memory, before the next transaction in T1 begins). So, if we have the interleaving T1 atomic1 -> T2 atomic 1 -> T1 atomic 2, then ptr will be set to NULL before we access ptr again, causing a NULL pointer access.
This comment was marked helpful 0 times.



Don't Atomicity and Isolation imply Serializability? Or is there a situation in which a transactional memory could be Atomic and Isolated, but not Serializable?
This comment was marked helpful 0 times.



Eager versioning: The transaction will make the update directly to the corresponding address, given that it has successfully locked the location. The transaction needs to record the original value of the location, in case it aborts in the future.
Lazy versioning: Stores writes in private write-log buffer. On successful commit, the writes in the buffer are done to the actual location and on failure, discard the log.
This comment was marked helpful 0 times.
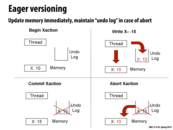

Here if we are going to be running through the entire undo log if the transaction fails. Why not we just store the initial value of X instead of a log of all the operations on X. This would not only save space but also the number of undo operations required.
Also according to my understanding a transaction either happens completely or does not happen at all, so we might not have a state where only few of the operations in the undo log have to be rolled back right? and hence removing the need to maintain history of operations that took place as part of the transaction.
This comment was marked helpful 0 times.

@pradeep I think we need to keep the log to check to detect whether a conflict occurred or not. I think it is true that we won't have partial state and that the result of rollback is the restoration of the original value, yet if we discard the information about the operations, we won't be able to see if a conflict happened.
As to why we walk the log backwards when a conflict happens rather than just restore the original value, I'm not sure. Maybe we don't want to keep that extra information around, since we need the log anyway? Can someone explain?
This comment was marked helpful 0 times.
Question: In transactional memory we say that we want to keep the operations secret until we commit the entire transaction. However for eager versioning, since we write directly to memory upon each operation, how can we possible prevent others from observing the change?
This comment was marked helpful 1 times.
I believe this is an implementation detail: since HTM is implemented with the cache coherence protocol. The write only updates the cache with the W bit set. So if another thread wants to read/write, it will have to ask the first thread to flush to memory, which happens after the first thread commits.
This comment was marked helpful 0 times.

@idl: You're hitting on why eager-optimistic implementations are "not practical". (Notice the chart in slide 52.) As shown above, an eager system does have updated values reflected in memory, so another processor in a transaction must pessimistically check for a conflict on loads and immediately trigger an abort if the value it is about to read is in the write set of a pending transaction.
I'd like to clarify that transactional memory can be implemented in many ways (including in software, albeit with much overhead). The implementation of lazy, optimistic transactional memory at the end of this lecture is implemented entirely in hardware as an extension of the coherence protocol, but that is not the only implementation of these ideas.
This comment was marked helpful 0 times.
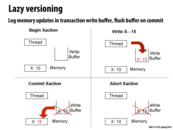

One difference between eager and lazy versioning is when we update memory. On the previous slide, the value of X in memory was updated on the Write step. With lazy, we don't update X in memory until the commit step. Instead, the new value of X is stored in a write buffer. Another difference is when we abort transactions. With eager, we had to roll back the transaction log to abort. But with lazy versioning, we simply clear the write buffer, which is faster.
This comment was marked helpful 0 times.
Question: For lazy versioning, if we had a chain of updates to x, say setting it to 10, then 15, then 20, do we store each individual update in the write buffer, or only the latest one? I'm guessing that for eager versioning, the undo log would have each entry (though perhaps an optimization could be some path compression of sorts, if it can figure out that the in-between values are insignificant).
This comment was marked helpful 0 times.
@idl I think that's a reasonable implementation (storing only the most recent update in the write buffer), but it would definitely require a slightly more complex implementation scheme (ie you need to maintain a set of memory addresses and their values, rather than a stack).
This comment was marked helpful 0 times.
As a side-note, while lazy versioning has a better abort mechanism than eager versioning, it does require a more complex data structure (either a stack or a set) to store the updates (whereas with eager versioning, we just store the original values). Also, actually committing the update is more expensive (since we need to obtain the results accumulated in the write buffer and write them to memory).
This comment was marked helpful 0 times.

@arjunh luckily all processors already have this data structure built in: the cache! By just writing updates to the cache as normal we essentially buffer all writes until the transaction completes. If anyone comes along and invalidates a line in the cache we know that a read/write conflict occured and someone can abort the transaction.
This comment was marked helpful 1 times.

How come lazy versioning has no fault tolerance issues? Can't it also crash in the middle of flushing its write buffer? I suppose this is less likely since simply writing the data will take less time than performing the operations in a transaction, but either way we are reliant on proper log keeping to make sure that we can detect if it happens and to abort the changes made if it does.
This comment was marked helpful 0 times.

@nrchu I think the idea is that the write buffer flushing is done in hardware, so we can check it ahead of time and know it will never fail. Eager versioning has a fault tolerance problem not because its log keeping infrastructure is more complicated, but because it has to run untrusted code (i.e. your code), and if your code fails then it needs to go fix memory.
This comment was marked helpful 0 times.



An issue mentioned in class is that in Case 2, if T0 were to then read from some address that T1 had written to previously, it would need to stall until T1 commited, however T1 was already stalling waiting for T0 to commit. In a naiive implementation this would deadlock. One possibility for avoiding this deadlock situation is to just cause one of the transactions to abort and allow the other to continue running.
This comment was marked helpful 0 times.

Something that was also brought up in class that I think is worth mentioning more is how there are many ways you could implement this. As @tchitten said, you could have T1 abort in case 2 instead of stalling, or in case 3, you could have T1 undo and abort instead of T0 aborting (though that wouldn't make perfect sense since writes are generally more expensive than reads)
This comment was marked helpful 0 times.

It's also mentioned in class that for case 2, an alternative plan is to read the previous value of A instead. The serialization property still holds, since you can view the ordering of two transactions as T1 and then T0. However, this solution also has problem with the case mentioned by @tchitten. The serialization property is broken because it's impossible to find the correct ordering of operations. For example, T0: wr A, rd B; T1: wr B, rd A. Then T0 is before T1 and T1 is also before T0. It seems to me the best solution is to abort in such a case, which may give you a livelock in the worst case.
This comment was marked helpful 0 times.
@squidrice it shouldn't lead to livelock since you only have to abort one of the transactions. The other one can proceed.
This comment was marked helpful 0 times.

In case 3, T0 needs to be aborted because of the serializability requirement. We need a sequence when two threads touching the same memory. So in this case, we can either abort T0 or make T1 wait until T0 finishes.
This comment was marked helpful 0 times.
What would constitute a good solution to the last case (where both transactions attempt to write to A)? My thought process is that the T0 can stall for an period of time (much like how we buffered test-and-set locks with an exponential back-off period, to avoid contention). This would allow transaction T1 to proceed, without any interference from transaction T0.
Of course, this leads to the same problems that we have with exponential delay (unfairness, increased latency for some transactions).
This comment was marked helpful 0 times.

Question: I am a bit confused by Case 2. When T1 reads A, it would read the un-updated value because T0 hasn't committed its changes yet. So after T0 commits, wouldn't T1 need to read A again? Or is that exactly what it meant :D?
This comment was marked helpful 0 times.
@Yuyang: I believe that the transactional memory system on this slide is eager versioning, so T1 reads the updated value that T0 wrote to memory and therefore has to stall until T0 commits before committing.
This comment was marked helpful 0 times.
@Yuyang and @spilledmilk: Pessimistic detection means that conflicts are checked for immediately (e.g., after every memory operation). In Case 2, the Rd A by T1 conflicts with the write set of pending transaction T0. One solution (the one shown in the figure) is just to hold up T1 until T0 commits, then the Rd A in T1 reflects the value of A after commit of T0. Another solution would be to abort T0 or T1.
In any of these cases, T1 will not read the updated value of A before T0 commits. If that was the case, then we've violated the semantics of what a transaction is.
This comment was marked helpful 1 times.

@arjunh, I think the easiest way would be to simply abort one of them and restart while we let the other proceed to completion.
This comment was marked helpful 0 times.

@pradeep maybe I'm getting confused but how exactly does optimistic detection keep memory in a consistent state? Doesn't both optimistic and pessimistic use a read and write set and only write to memory when a commit is successful?
This comment was marked helpful 0 times.
oops sorry I was thinking Eager and Lazy when I wrote that. Removed it so that it wont confuse anyone. Thanks.
This comment was marked helpful 0 times.

Here in Case 3, even though thread 1 writes to A, before thread 0 commits. Thread 0 could go ahead and commit, because all of thread 1's changes were only reflected in its local logs and nothing was committed to memory as yet as it commits after thread 0.
This comment was marked helpful 0 times.
Question: I am very confused by Case 4. I understand it would work fine with lazy versioning where nobody touches the memory. But what happens if we use eager versioning, where T0 already updated the memory before T1's read? Wouldn't this screw T1 up?
This comment was marked helpful 0 times.
Remember the Isolation property of transactional memory: no other process sees the change before it commits. Thus, T1 will not see the new value before T0 commits.
This comment was marked helpful 0 times.
Yeah I think Kayvon's answer on the Eager Versioning slide saying that the eager optimistic method is not practical to implement makes this clearer!
This comment was marked helpful 0 times.

@pradeep I don't understand why case 3 has things to do with local logs. When T0 commits, it will first check if there is any conflict operations in T1, whatever the value T1 sets to A.
Can anyone explain the case 3 of both pessimistic and optimistic: why T0 has to restart in PESSIMISTIC mode, while succeeds in OPTIMISTIC mode?
This comment was marked helpful 0 times.
Pessimistic: If we keep the order as in the example, T0 reads A and then checks with T1 for any conflicts. T1 hasn't done anything, so no conflicts. T1 now writes to A, and checks if there are any conflicts with T0. There is with the readA, and since we assumed that the checking thread is not the one aborting, T1 aborts T0.
Optimistic: Now T0 does its read, and it doesn't care about anything that T1 is doing in the meantime. But, once it gets to the commit, T0 checks for any conflicts. Since there are none, it commits. It would be a different case if T1 got to the commit first. Then T1 would find a conflict with T0, so T1 would abort T0. (as in the Case 2)
This comment was marked helpful 0 times.
Let's think about Case 3 in detail, because if you understand cases 3 and 4 you really have a good sense of the behavior of an optimistic implementation.
Transaction T0 goes to commit. In an optimistic system such as this one, the commiter wins. That means, on T0's commit the system performs checks to see if other outstanding transactions must abort.
In this check we see that T1's write set has A, and that T0's read set also has A. There's no need to roll back T1 since T0 did not modify A, and so all the information T1 has about A is consistent with the information it would have observed has T1 executed completely after T0. There's no conflict. Everything appears as if T1 executed entirely after T0.
However, if T0 has written A, then T1 would need to abort on T0's commit. This is the case regardless of whether A is in the read set or write set of T1. T1 now comes after T0 in the serialized order of conflicting transactions, so it's execution should observe all of T0's writes. This is in fact what is shown in case 4 (except in the case 4 illustration T1 is the committing transaction and so T0 aborts so it can observe T1's writes).
This comment was marked helpful 0 times.
I'd also like to point out that the eager vs. lazy implementation of transactions is simply an implementation detail. The semantics of a transaction (described here) are that the writes it performs are not observed by other transactions until commit occurs. Any system that does not implement these semantics is not a valid implementation of transactions... or at least an implementation that adheres to some other semantics. Whether or not these transactions are implemented via an undo log ("eager") or a write buffer ("lazy") does not change the definition of a transaction. This is another example of abstraction vs. implementation.
Of course, some implementation choices make it very difficult to implement the semantics of the abstraction. An eager, pessimistic system would be quite difficult to implement in any performant way. Consider what the system would have to do. It would sent writes immediately to memory and maintain an undo log. Then every other transaction would have to check all the undo logs on every load/store, and pull the data out of the undo logs, etc...
This comment was marked helpful 0 times.

I'm a little bit confused why Case 2 is labelled Abort and Case 4 is labelled Forward progress? I see that the threads with sets that contain writes to a location causes other threads to abort/restart once the set is committed because they contain the location in their read/write sets, but what is the reason why Case 4 is labelled Forward progress instead of Abort?
This comment was marked helpful 0 times.
@sluck: All situations are forward progress. Case 1 has no conflicts and thus no transactions must be aborted.. Case 2 features a conflict, and thus T1 has to abort and rerun. Case 3 contains no aborts at all. Case 4 requires T4 to abort and then rerun to make progress. The label was in contrast to the case 4 "no progress" label from the pessimistic case on slide 47. Obviously a good implementation of the pessimistic case would employ mechanisms to avoid the livelock shown on that slide.
This comment was marked helpful 0 times.


It seems to me that the pessimistic conflict detection is basically "check and then do or not do" while the optimistic version is "do and then check and then undo if needed". Therefore the pessimistic version is apparently guaranteed to always have 2 (if do) or 1 (if not do) steps while the optimistic version has 2 (if do) or 3 (if not do) steps. Therefore, I'm confused as to why the pessimistic version is not always used? It seems to me that having less steps (i.e. work) is more beneficial to "forward progress guaranteed".
This comment was marked helpful 0 times.
The optimistic version has only 1 step. It simply does the operation. It only makes one check at the end to see if there was a conflict. So the optimistic version will have less total work if there are no conflicts.
This comment was marked helpful 0 times.

Found this guide about pessimistic and optimistic conflict detection in SQL databases (IBM's solidDB), as in this case the database allows you to choose which one is better for your usage.
After seeing this, I wondered what the default option was, and found it interesting that it depends on whether your table is on disk (optimistic) or in memory (pessimistic), which makes sense.
This comment was marked helpful 0 times.



Software TM would be more flexible and easier, since HTM would need to modify hardware. But HTM would be faster. A hybrid TM method would be use HTM when no context switches or something else bad for HTM(would cause problem for HTM), otherwise switch so STM. But this could be tricky.
This comment was marked helpful 0 times.

Eager + Optimistic is impractical in hardware because the check for conflicts doesn't happen until the thread is ready to commit, even though the thread attempting to commit could have gotten all the information that needs to be checked through cache coherence. If the thread had checked for a conflict sooner, it could have aborted sooner rather than having to run through to completion and then run through a rollback.
In software, though, where you don't have cache coherence to give you clues about who else is using the same memory, Eager + Optimistic can have its advantages. More specifically, in a software TM system, it would be more expensive to have to check a write buffer (stored in software) at the end of each transaction than check for conflicts in memory and thus Eager + Optimistic can be faster than Lazy + Optimistic in software.
[More info on page 17 if anyone's interested.]
This comment was marked helpful 0 times.

I have a question about the role that transactional memory systems hope to play in the future. Is the eventual goal to reach a point where memory is by default transactional and there is no need for locking based mechanisms or will transactional memory always be a sideline approach for concurrency and transaction coherence?
It seems that operations that are highly contested would not gain much from a transactional memory system as opposed to the simple locking and unlocking schemes discussed earlier. This being said, is a hardware-based transactional memory system practical. I understand that lock based programming could still be laid over the memory system but would this lead to sub-optimal performance in high-contention parallel code? As opposed to a software based system that can be turned on and off as needed
This comment was marked helpful 0 times.

Just a note this is talking about a lazy-optimistic scheme.
This comment was marked helpful 0 times.

This is an interesting paper that describes and evaluate an implementation of HTM:
http://research.cs.wisc.edu/multifacet/papers/hpca07_logtmse.pdf
This comment was marked helpful 0 times.



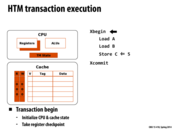
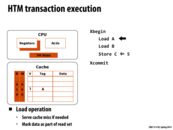
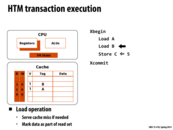
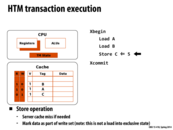

The hardware transaction is implemented in cache. A potential problem is that variables involved in a single transaction cannot fit into cache. The solution is to let processors abort such a transaction with an abort handler. However, for transaction with the number of variables that is essentially too large for cache, no matter how many times it tries, it always gets aborted. The transaction then is livelocked. A way to avoid this livelock is to use short transactions with acceptable number of variables in memory.
This comment was marked helpful 0 times.

Aborting of a transactional memory commit will be somewhat costly due to the time it will take to reload the cache line and restore the values in the transaction. This is not an earth-shattering amount of time, but can build up if it happens too often. One can also imagine that the more this memory commit gets stuck, the more it holds up the rest of the program. If too many processors are trying to commit the same places in memory (which hopefully doesn't happen or is prevented by other hardware), then a particular processor may never be able to commit its changes.
This comment was marked helpful 0 times.


Here and here are more information about hardware transactional memory in Haswell. The first one talks more in depth about the use of it in Haswell processors, including the possible implementation, analysis, and the future of transactional memory. The second gives some graphs of its performance.
This comment was marked helpful 0 times.

In lecture, Kayvon pointed out that one of the reasons why the processor might abort the transaction is that the cache lines being used in the transaction might be evicted from the cache. Usually, the abort handler falls back to some sort of lock based implementation to ensure forward progress because the processor might keep on causing an abort if the transaction was retried using HTM.
This comment was marked helpful 0 times.

The key idea of transactional memory is optimistic concurrency, it creates the abstraction that one region is atomic. But in actual implementation, atomic regions would be executed in speculation, when there is conflict, trigger abort, otherwise complete the transaction. It creates an illusion that if no body saw me doing it, then I did not do it. I think speculation is one important idea in computer architecture. Another related work is speculative lock elision. Also, "Two Techniques to Enhance the Performance of Memory Consistency Models", this paper talks about techniques to enhance SC memory consistency model to perform nearly the same with some relaxed consistency model by speculation, and the trick is similar to TM.
This comment was marked helpful 0 times.
For reference - His page is here: http://csl.stanford.edu/~christos/
This comment was marked helpful 0 times.